Point-E experiments
/u/dismantlemars created a colab to run OpenAI's new Point-E model that you can use here. My first few experiments were interesting though not very usable yet! Supposedly it's thousands of times faster than DreamFusion though (the most well known crack at this). It took me about 30 secs to generate models, and converting the point cloud to a mesh was instant.
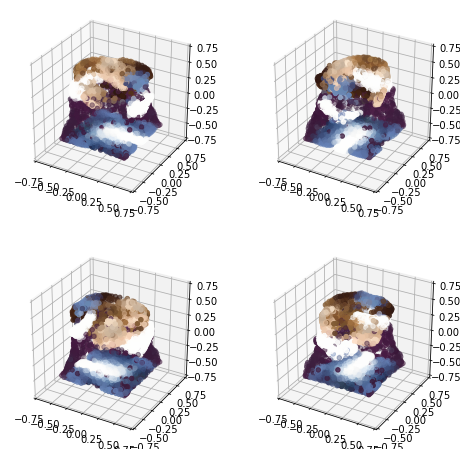
I tried to first turn my profile picture into 3D, which came out all Cronenberg'd. To be fair, the example images are all really clean renderings of 3D models, rather than a headshot of a human.
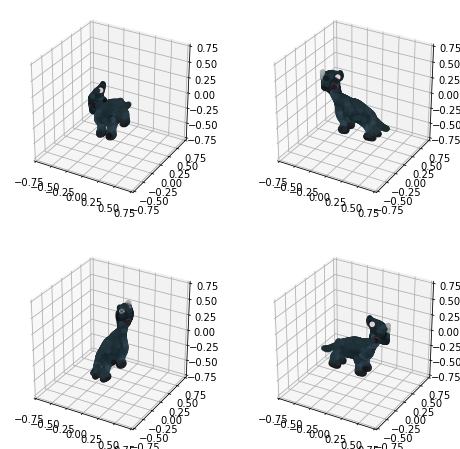
Then I tried the text prompt "a pink unicorn" which came out as an uninteresting pink blob vaguely in the shape of a rocking horse. Simply "unicorn" looked a bit more like a little dinosaur.
And finally, "horse" looked like a goat-like horse in the end.
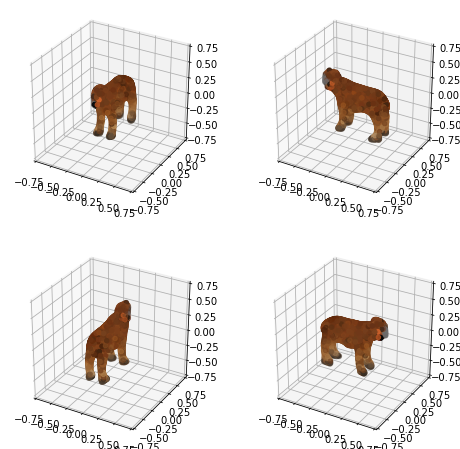
The repo does say that the text to point cloud model, compared to the image to point cloud model is "small, worse quality [...]. This model's capabilities are limited, but it does understand some simple categories and colors."
I still find it very exciting that this is even possible in the first place. Probably less than a year ago, I spoke to the anything.world team, and truly AI-generated models seemed so far out of reach. Now I feel like it won't be much longer before we can populate entire virtual worlds just by speaking!
On a related note, I recommend that you join the Luma waitlist for an API over DreamFusion.