First attempt at actually organising my bookmarks
In April 2023, I came across this article and found it very inspiring. I had already been experimenting with ways of visualising a digital library with Shelfiecat. The writer used t-SNE to "flatten" a higher-dimensional coordinated space into 2D in a coherent way. He noticed that certain genres would cluster together spatially. I experimented with these sorts of techniques a lot during my PhD and find them very cool. I just really love this area of trying to make complicated things tangible to people in a way that allows us to manipulate them in new ways.
My use case was my thousands of bookmarks. I always felt overwhelmed by the task of trying to make sense of them. I might as well have not bookmarked them as they all just sat there in piles (e.g. my Inoreader "read later" list, my starred GitHub repos, my historic Pocket bookmarks, etc). I had built a database of text summaries of a thousand or so of these bookmarks using Url summariser, and vector embeddings of these that I dumped into a big CSV file, which at the time cost me approximately $5 of OpenAI usage. This might seem steep, but I think at the time nobody had access to GPT-4 yet, and the pricing also wasn't as low. I had also I accidentally had some full-length online books bookmarked, and my strategy of recursively summarising long text (e.g. YouTube transcripts) didn't have an upper limit, so I had some book summaries as well.
Anyway, I then proceeded to tinker with t-SNE and some basic clustering (using sklearn which is perfect for this sort of experimentation). I wanted to keep my data small until I found something that sort of works, as sometimes processing takes a while which isn't conducive to iterative experimentation! My first attempt was relatively disappointing:
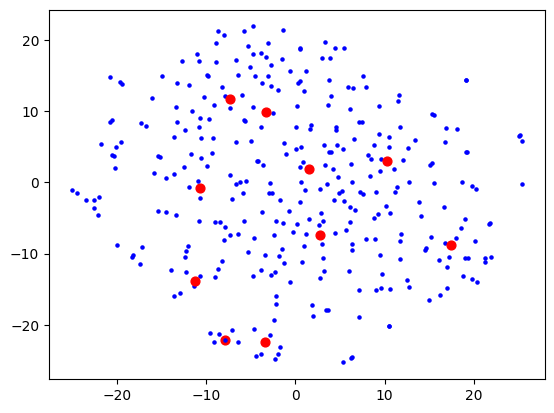
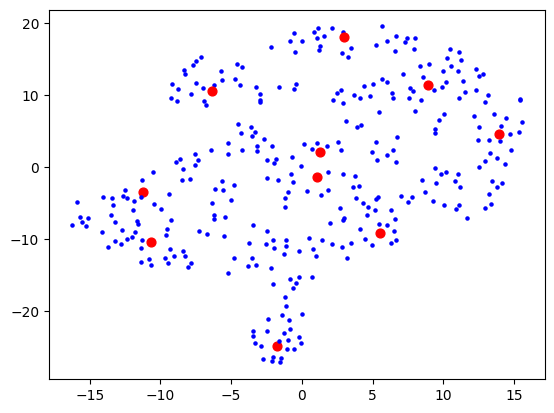
Here, each dot is a bookmark. The red dots are not centroids like you would get from e.g. k-means clustering, but rather can be described as "the bookmark most representative of that cluster". I used BanditPAM for this, after reading about it via this HackerNews link, and thinking that it would be more beneficial for this use case.
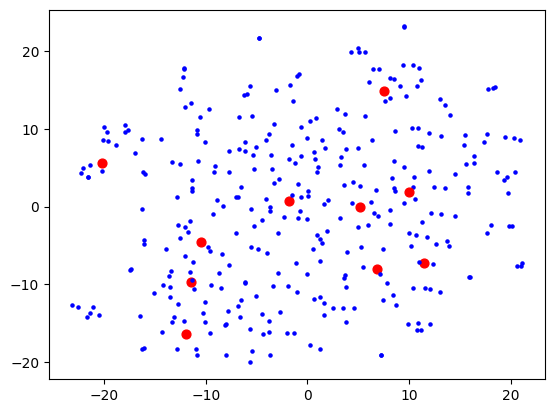
I was using OpenAI's Ada-2 for embeddings, which outputs vectors with 1536 dimensions, and I figured the step from 1536 to 2 is too much for t-SNE to give anything useful. I thought that maybe I need to do some more clever dimensionality reduction techniques first (e.g. PCA) to get rid of the more useless dimensions first, before trying to visualise. This would also speed up processing as t-SNE does not scale well with number of dimensions. Reduced to 50, I started seeing some clusters form:
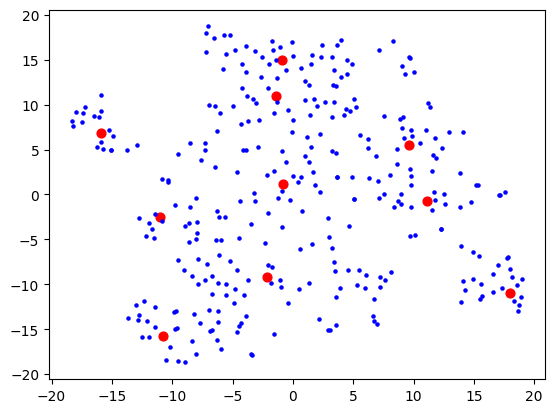
Then 10:
Then 5:
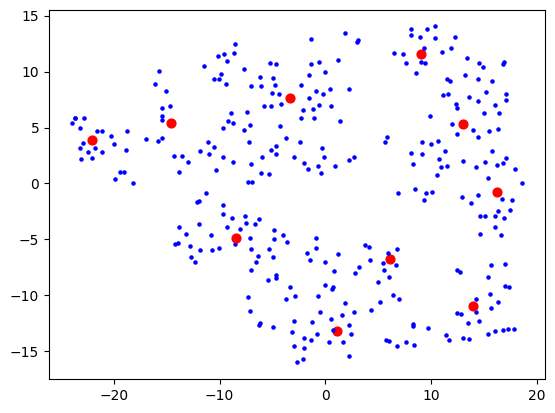
5 which wasn't much better than 10, so I stuck with 10. I figured my bookmarks weren't that varied anyway, so 10 dimensions are probably good enough to capture the variance of them. Probably the strongest component will be "how related to AI is this bookmark" and I expect to see a big AI cluster.
I then had a thought that maybe I should use truncated SVD instead of PCA, as that's better for sparse data, and I was picturing this space in my mind to really be quite sparse. The results looked a bit cleaner:
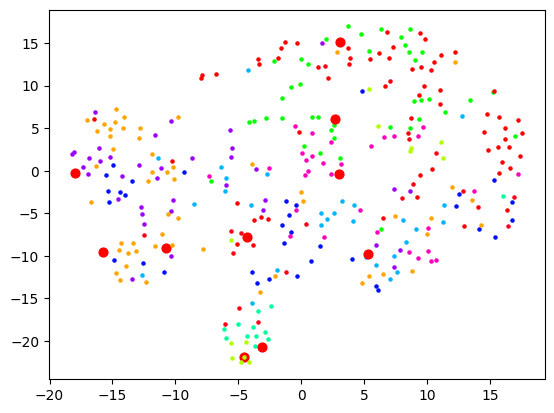
Now let's actually look at colouring these dots based on the cluster they're in. Remember that clustering and visualising are two separate things. So you can cluster and label before reducing dimensions for visualising. When I do the clustering over 1500+ dimensions, and colour them based on label, the visualisation is quite pointless:
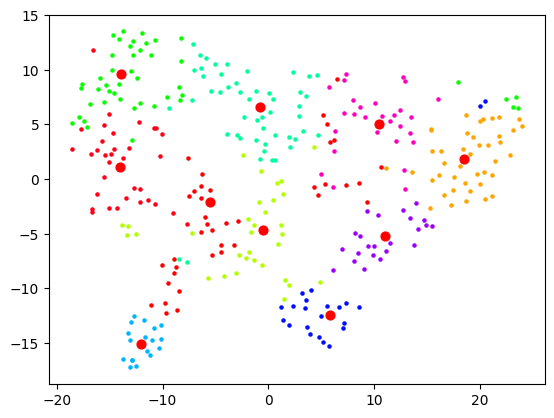
When I reduce the dimensions first, then we get some clear segments, but the actual quality of the labelling is likely not as good:
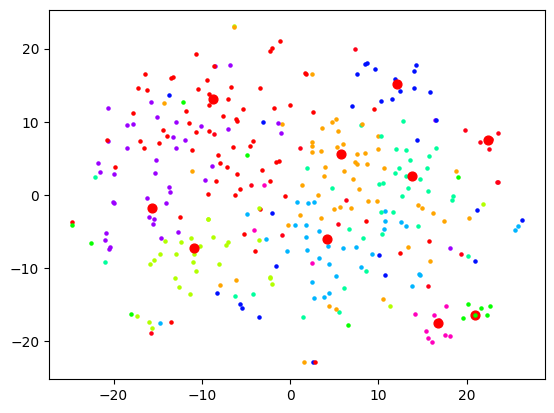
And as expected, no dimension reduction at all gives complete chaos:
I started looking at the actual content of the clusters and came to a stark realisation: this is not how I would organise these bookmarks at all. Sure, the clusters were semantically related in some sense, but I did not want an AI learning resource to be grouped with an AI tool. In fact, did I want a top-level category to be "learning resources" and then that to be broken down by topic? Or did I want the topic "AI" to be top-level and then broken down into "learning resources", "tools", etc.
I realised I hadn't actually thought that much about what I wanted out of this (and this is also the main reason why I limited the scope of Machete to just bookmarks of products/tools). I realised that I would first need to define that, then probably look at other forms of clustering.
I started a fresh notebook, and ignored the page summaries. Instead, I took the page descriptions (from alt tags or title tags) which seemed in my case to be much more likely to say what the link is and not just what the content is about. This time using SentenceTransformer (all-MiniLM-L6-v2) as Ada-2 would not have been a good choice here, and frankly, was probably a bad choice before too.
I knew that I wanted any given leaf category (say, /products/tools/development/frontend/) shouldn't have more than 10 bookmarks or so. If it passes that threshold, maybe it's time to go another level deeper and further split up those leaves. This means that my hierarchy "tree" would not be very balanced, as I didn't want directories full of hundreds of bookmarks.
I started experimenting with Agglomerative Clustering, and visualising the results of that with a dendrogram:
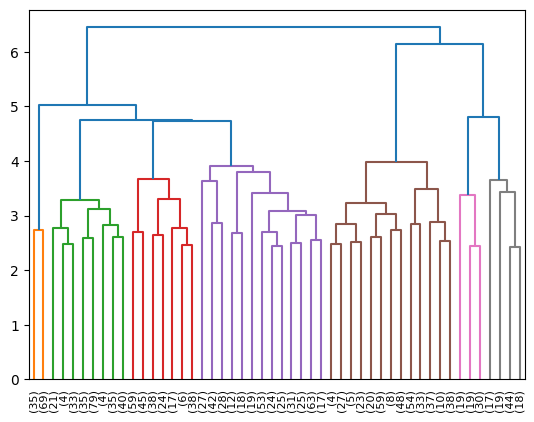
Looking at the where bookmarks ended up, I still wasn't quite satisfied. Not to mention, there would need to be maybe some LLM passes to actually decide what the "directories" should be called. It was at this point that I thought that maybe I need to re-evaluate my approach. I was inadvertently conflating two separate problems:
- Figuring out a taxonomy tree of categories
- Actually sending bookmarks down the correct branches of that tree
There's a hidden third problem as well: potentially adjusting the tree every time you add a new bookmark. E.g. what if I suddenly started a fishing hobby? My historical bookmarks won't have that as a category.
I thought that perhaps (1) isn't strictly something I need to automate. I could just go through the one-time pain of skimming through my bookmarks and trying to come up with a relatively ok categorisation schema (that I could always readjust later) maybe based on some existing system like Johnny•Decimal. I could also ask GPT to come up with a sane structure given a sample of files.
As time went on, I also started to spot some auto-categorisers in the wild for messy filesystems that do the GPT prompting thing, and then also ask GPT where the files should go, then moves them there. Most notably, this.
That seems to me so much easier and reliable! So my next approach is probably going to be having each bookmark use GPT as a sort of "travel guide" in how it propagates the tree. "I'm a bookmark about X, which one of these folders should I move myself into next?" over and over until it reaches the final level. And when the directory gets too big, we ask GPT to divide it into two.
The LLM hammer seems to maybe win out here -- subject to further experimentation!