deen.ai
Overview
deen.ai can be summarised as "Muslim ChatGPT". It's a one-shot AI assistant that answers your questions from the perspective of an Islamic scholar. The scope was deliberately small, as I wanted to do this in a short amount of time to try out a few different things. I bought the domain and build everything on the weekend of the 7th of January 2023. The code is on GitHub. The reason I picked this vertical / use case, is because:
- I could get a lot of feedback via my Muslim networks, as well as friends and family
- It seemed like it hasn't really been done before, at least not in this way (and I think I know why not now)
- It seemed like an easy use case (turns out it's a lot more nuanced than I thought)
- It could potentially help build a newsletter that I could tell about other projects
Architecture
I set out wanting to hone the workflow for creating products like this, as well as experiment with a new stack. On the front-end, I wanted to try using htmx, but it turned out to not be very well suited to this, so I ended up going pretty vanilla for this. I wanted to try building a specific kind of journey that goes like this:
- Land on a page with one very clear action that creates value
- That action also creates an easily shareable artefact, that has a domain watermark on it, which becomes the main growth driver
- People can also sign up to a newsletter to keep up to date about future projects, such that when those launch, growth is not from scratch
- Or, they can repeat the journey once more
The main very useful bits of code here (that I plan to use in some other projects -- already have ideas!) are:
- Generating a shareable image from the user (and AI) generated content
- Code for using the Web Share API where it's available, or letting you download the image where not
- The little embedded form for easily signing up to the newsletter (this uses ConvertKit but I ended up doing the same with TinyLetter too)
Besides that, I streamlined my process for different bits and pieces like UI, logo, social media preview cards, favicons, loading states with an SVG spinner, etc.
More important is the back-end however. I've been using Node-RED more and more to create little APIs, and it's super convenient and easy to build things in. Currently, this is what the back-end to deen.ai looks like:
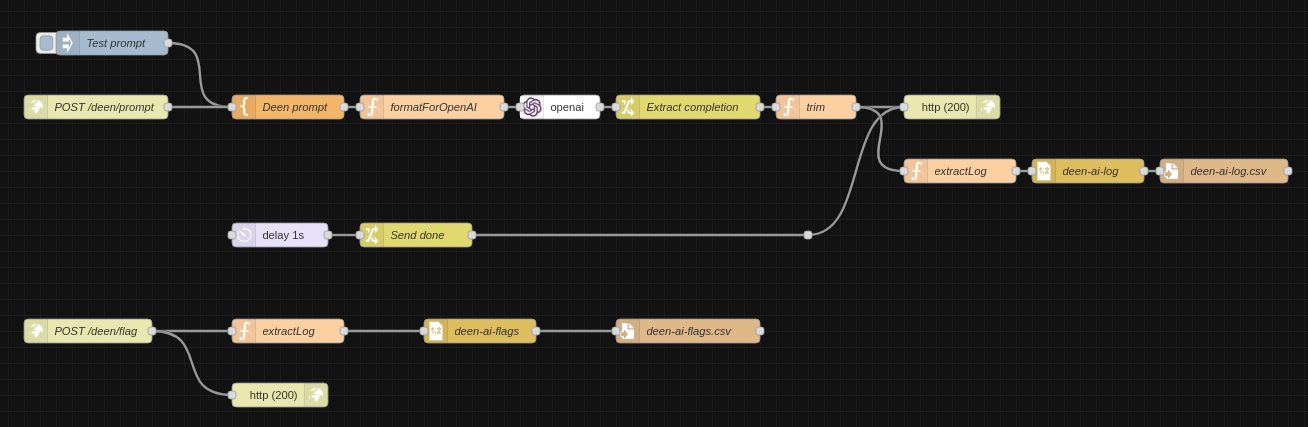
I even have some nodes in there just for testing (e.g. sending a test prompt, or bypassing OpenAI and instead waiting a second and responding "Done") which sped up development. The heavy lifting is of course done by GPT-3, which I would like to fine-tune based on the training data I collect from this first release. Besides that, I mainly transform prompts and answers, and append these with a timestamp to a CSV file.
On the bottom, we have the flagging flow. If a user flags a result, it gets logged to a separate CSV, so I can use this later to improve the model.
Challenges
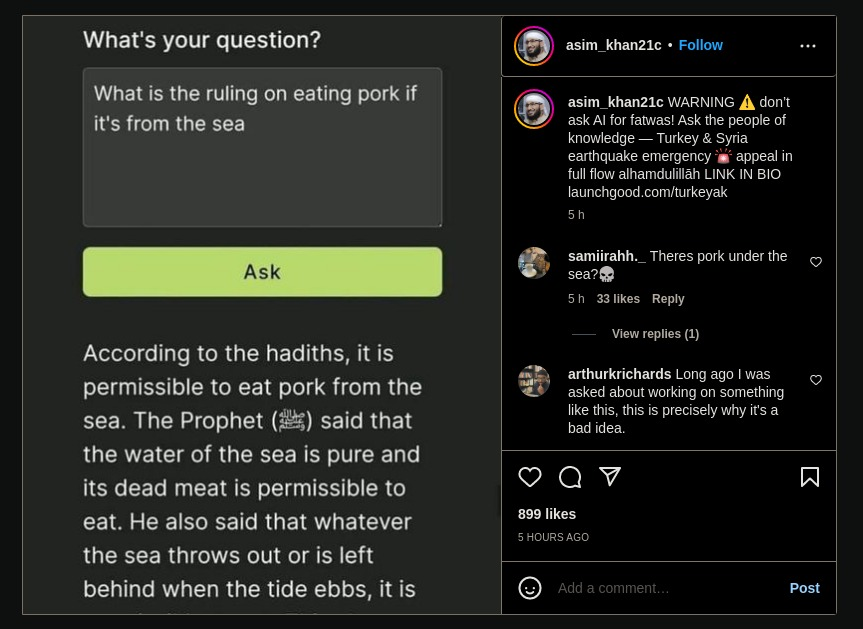
The answers you get back are sometimes quite off. The worst thing that can happen is that the answer is just completely made up, including the citations (I try to force it to always give primary source citations). I think I could introduce some steps later in the pipeline to verify these against quran.com and sunnah.com, but my friends who've been testing this have found cases where a hadith talks about photography, it insists there are only 3 fardh prayers, or it says something not quite right, then backs it up with a completely unrelated hadith. Like many other GPT-3-based products, it's just not quite there yet, and that last part makes all the difference. Maybe GPT-4?
The other questions is: who's actually asking questions? Is it the curious non-Muslim asking "easy" exploratory questions? Is it the Muslim asking very technical questions that depend on the madhhab? Is it the anti-Muslim looking to get an out-of-context quote? Human Islamic scholars tailor their answers to the person who's asking the question, but deen.ai can't do that currently. Similarly, there may be several correct answers to a question (cf madhhab) and indeed you might get different answers to the same question if you ask it again. I don't want to be responsible for misinformation.
So overall, I think these problems might be intractable for now, so I won't present this as anything more than an experiment, and try to improve it to reach that ideal accuracy. Maybe this could spawn other ideas in the same space (I already have a bunch) or help build useful datasets!
Amar Memoranda > deen.ai
 Yousef Amar
Yousef Amar
Log
Why certain GPT use cases can't work (yet)
Some weeks ago I built the "Muslim ChatGPT". From user feedback, I very quickly realised that this is one use case that absolutely won't work with generative AI. Thinking about it some more, I came to a soft conclusion that at the moment there are a set of use cases that are overall not well suited.
Verifiability
There's a class of computational problems with NP complexity. What this means is not important except that these are hard to solve but easy to verify. For example, it's hard to solve a Sudoku puzzle, but easy to check that it's correct.
Similarly, I think that there's a space of GPT use cases where the results can be verified with variable difficulty, and where having correct results is of variable importance. Here's an attempt to illustrate what some of these could be:

The top right here (high difficulty to verify, but important that the results are correct) is a "danger zone", and also where deen.ai lives. I think that as large language models become more reliable, the risks will be mitigated somewhat, but in general not enough, as they can still be confidently wrong.
In the bottom, the use cases are much less risky, because you can easily check them, but the product might still be pretty useless if the answers are consistently wrong. For example, we know that ChatGPT still tends to be pretty bad at maths and things that require multiple steps of thought, but crucially: we can tell.
The top left is kind of a weird area. I can't really think of use cases where the results are difficult to verify, but also you don't really care if they're super correct or not. The closest use case I could think of was just doing some exploratory research about a field you know nothing about, to make different parts of it more concrete, such that you can then go and google the right words to find out more from sources with high verifiability.
I think most viable use cases today live in the bottom and towards the left, but the most exciting use cases live in the top right.
Recall vs synthesis
Another important spectrum is when your use case relies on more on recall versus synthesis. Asking for the capital of France is recall, while generating a poem is synthesis. Generating a poem using the names of all cities in France is somewhere in between.
At the moment, LLMs are clearly better at synthesis than recall, and it makes sense when you consider how they work. Indeed, most of the downfalls come from when they're a bit too loose with making stuff up.
Personally, I think that recall use cases are very under-explored at the moment, and have a lot of potential. This contrast is painted quite well when comparing two recent posts on HN. The first is about someone who trained nanoGPT on their personal journal here and the output was not great. Similarly, Projects/amarbot used GPT-J fine-tuning and the results were also hit and miss.
The second uses GPT-3 Embeddings for searching a knowledge base, combined with completion to have a conversational interface with it here. This is brilliant! It solves the issues around needing the results to be as correct as possible, while still assisting you with them (e.g. if you wanted to ask for the nearest restaurants, they better actually exist)!
Somebody in the comments linked gpt_index so you can do this yourself, and I really think that this kind of architecture is the real magic dust that will revolutionise both search and discovery, and give search engines a run for their money.
ChatGPT as an Islamic scholar
Last weekend I built a small AI product: https://deen.ai. Over the course of the week I've been gathering feedback from friends and family (Muslim and non-Muslim). In the process I learned a bunch and made things that will be quite useful for future projects too. More info here!