Log #ai
This page is a feed of all my #ai posts in reverse chronological order. It only includes posts with a timestamp (so e.g. not named "digital garden" pages or living documents). You can subscribe to this feed in your favourite feed reader through the icon above.
Everything here was written by me and me alone. Writing is a big part of my thinking process and these posts get published out of my internal writing. It's all organic; 0% AI assistance. Sometimes I will write about my experience using AI tools (e.g. to create a song or such) and in that case it will be very obvious in what I write that the attached media is made by AI.
![]()
Amar Memoranda > Log (ai)
 Yousef Amar
Yousef Amar
Why vibe mathsing is actually just vibe coding
I watched this video recently which talks about how an Erdős[1] problem was solved with a single prompt. Multiple problems in fact!
We'd previously written about how even though AI is still a bubble, there is a strong use case in coding agents. A large part of this is thanks to the fact that these agents can check if the code compiles and run tests in a loop until the code works.
So I was surprised to hear that these agents are now good at mathematical proofs too, as that was notoriously the hardest domain for LLMs. It turns out, there's a functional programming language called Lean which allows you to write proofs as code that are guaranteed to be correct at "compile-time". I won't claim to understand how it works, but it seems like proofs are treated like types in Lean, so a type checker is really a proof checker.
So maths, at least some kinds of maths, can be reduced to code, and we already know why LLMs are good at code! It makes me wonder, what other domains could be expressed as a DSL with a "compiler" that can check the output?
Incidentally, my Erdős number is 4! My shortest path is via Richard Mortier, but I also have a non-overlapping 5 path via Philip Torr. ↩︎
Everything Al does
Last time, I wrote about RISC-like tool use for my agent Al. As I'm rebuilding Al from scratch, I've been writing down everything he does so far (albeit not reliably), and everything I need him to be able to do. Everything in the lists below is realistic. For the most part, all he needs are a webhook endpoint and these CLI tools:
- Basic file tools (
cat,grep,find, etc) curlfor APIs and fetching URLsgogto access Google appsrr(roadrunner) to access the Beeper MCP- Obsidian CLI to access PKM (not critical given the first point)
That's it! I'll add more over time I'm sure, but this is already a lot.
For now, I'm leaving out smart-home related things, as the tools for that are a bit too complicated, but you can imagine e.g. Al turns the TV on, turns the lights low, and queues up a movie after we decide on one from the movies list. For now, he only needs to do relatively few things with these tools, some of which are not even that critical. Let's expand a bit:
- The ability to communicate
- Send/receive WhatsApp messages
- Own phone number
- Send/receive emails
- Own email inbox with hooks for incoming email
- Send/receive Slack messages
- Own Slack app
- Send/receive voice notes
- Own OpenAI key
- Make phone calls
- Own Twilio key and number -- I tried other providers as I hate Twilio, but unfortunately Twilio is the best for this right now. Might use something else in the future.
- Send/receive WhatsApp messages
- The ability to schedule tasks for the future
- Own calendar to schedule events that trigger hooks
- A place to take notes
- Own folder in my Obsidian vault (symlinked out)
- Ability to store and modify own files
- A place to log mistakes (via Obsidian CLI)
- Own self-improvement Kanban (via Obsidian CLI)
- The ability to check RSS feeds (cURL)
- https://kill-the-newsletter.com/ to turn newsletters into feeds
- The ability to keep tabs on me
- The ability to monitor my own emails and Drive files (via gog CLI)
- And messages (Beeper MCP via roadrunner CLI)
- A way to check my GPS coordinates (and orientation?) on demand (via OwnTracks API)
- The ability to gather information from the internet
- Fetch arbitrary URLs
- Access to Google Maps API
- Ability to modify some of my own files (via Obsidian CLI)
So that's well and all, but what would it do with all those powers? These are relatively few powers, but you'd be surprised at how that's enough to seriously change how you operate. I can't wait for my Pebble Index to arrive as I'll be issuing commands via that primarily.
Here's a full breakdown of my use cases so far, organised into general categories.
Self-improvement
Al needs to be able to improve himself by maintaining and modifying his prompts and code. Al does not modify these directly, but by making suggestions.
- Watch for OpenClaw updates or use cases that may be interesting and proactively make feature suggestions to own project if it may be useful
- Regularly review own chat log and log mistakes
- Regularly look at list of mistakes, brainstorm and research ways to address, create improvement tasks
- Create new workflow files to learn new abilities over time after I've shown how it's done the first time
Helping with work
Al needs to be able to help with my startup Artanis, and in some cases communicate with my colleagues over Slack or whatever other medium.
- Maintain notes on Artanis in memory/artanis/
- Keep tabs on our Monthly Update emails (there's an RSS feed)
- Keep tabs on all relevant Google Docs/Sheets
- Keep tabs on our calendars and Slack (especially the #planning channel)
- Keep tabs on our Linear workspace
- Complete specific workflows
- Create Gmail forwarding rules for invoice forwarding
- Help me track down missing invoices for bookeeping, including asking my team
- Schedule call review slots in my calendar when Sam sends a call recording
- Turn long written agendas (e.g. offsite schedule, or an event) into calendar events in my calendar
- Modify my working location on my work calendar so colleagues can know if I'm WFH or WFO or somewhere else on any given day
- The morning of when a Team Lunch is scheduled, sort out the logistics
- Ask my team what they feel like having for lunch
- If external guests are joining (it will say on the calendar event), ask them too
- Find out if we're eating out or getting takeaway
- If they suggest a cuisine rather than a restaurant, find an appropriate restaurant
- Give the option between a past place (so remember what we eat) and a new place when found
- If takeaway, find based on delivery time and if listed or not on either Uber Eats or Deliveroo
- If eating out, find based on walking distance from office and rating
- If takeaway, initiate a group order (both Uber Eats and Deliveroo support this) and send the link. Only add things to the order when explicitly asked. When everyone is done adding, check out.
- If eating out, make the booking for the time on the calendar event
Filter through the noise
Al should act as a first line of defence against digital comms noise.
- Notify me of any important emails or messages when they come in
- Reply to emails on my behalf when asked
- Unsubscribe from emails on my behalf when asked
- Where there's no way to unsubscribe, this includes replying with a request to be taken off their list, from the same email address
- Archive emails on my behalf when asked
Help me stay on top of things
Al should keep me up to date on what he's doing, what the world is doing, and what I should be doing.
- Send daily morning reports
- Summary of schedule for the day (5 calendars)
- Any emails/messages that I haven't responded to in longer than 2 working days
- HackerNews front page picks, with links, based on my interests
- Any open threads that might need my attention from our projects
- Summary of overnight work or research
- Summary of any conversations with others
- Bookmarks of the day, which I can decide to keep or delete
- Send weekly report (Monday report is special)
- In addition to the above, also check all DNS and server statuses
- If ISP have rotated my IP, run workflow to update IPs
- If a server is down, flag immediately
- In addition to the above, also check all DNS and server statuses
- When I flag a grocery list item that needs restocking, add it to the calendar event for ordering groceries
- Initiate weekly Sainsbury's grocery order every Sunday
- Check if browser use is still authenticated (no API)
- Check what time the delivery should be scheduled for in the calendar
- Start an order, and if the time slot is not available, look for alternate times in the calendar, then ask me if it's ok to move it. Once we've found a time, make sure the calendar event is at the right time and book a delivery slot
- Never order new items, only items from past orders or in Favourites. Follow the workflow file to understand how to use this UI
- Add all the regular items to the order and the additional ones from the calendar event
- Get it over the minimum charge and check out the order
- Send a message to notify for amendments before the cut-off date
Communicate with others
Al should take some comms weight off me by responding to my contacts when they message directly.
- Gatekeep people asking to meet
- Find out what the purpose/agenda is
- Short-circuit / reject if appropriate
- Determine if it can be done in messages instead and ping me
- Help them find a virtual/physical time/place to meet if appropriate based on my availability and preferences
- Follow up with them when needed when they haven't responded
- Figure out information from them on my behalf when they're being too obtuse
- Allow my mother to find my general location in an emergency
- Immediately inform me of new conversations and odd requests
- Remember things about my contacts and practice information hygiene by only loading the person's file that is in conversation
Pay others
Al should pay others on my behalf, for personal payments. As this is a sensitive action, these use cases are not a subset of examples, but the total set of what Al can do here.
- Pay my driving instructor Jameel £67.50 the morning I have a driving lesson scheduled and text him to say I paid and when I'll meet him
- On receiving an email from Kate on scheduling changes, modify the standing order, then respond to her confirming the exact changed that was made and when to expect payments.
- As this doesn't work via the Monzo API, Al should also just initiate the payments manually on the due dates in received invoices and pay exactly £45
- As Al is limited to only paying those exact two amounts to those exact recipients and a limited frequency, Al must notify me immediately if a payment fails, why, and suggest what needs to change (e.g. a limit increase)
Help manage my schedule
Al should help scheduling and rescheduling events in my calendar and use external tools to help.
- Book my gym classes the moment they become available via provided URLs. Right now, this means checking every Wednesday morning and booking classes for 2 weeks into the future. Where I have clashes, ask me what to do
- Schedule gardening tasks into my calendar based on seasons and inventory
- Put travel itineraries in my calendar with the correct timezones
- Help me reach physical locations that I need to be at
- Finding e.g. the nearest pharmacy
- Sending directions straight to my phone
- Informing me of ETAs
- Informing others of ETAs
Help manage my personal knowledge base
I have a lot of notes, journals, etc (this blog is part of it). Al should not ever edit anything I've written, or write anything on my behalf, however can help me a lot with organising these.
- Enrich and append items to my lists
- Reading list
- Video games list
- 2x movie lists
- Writing ideas
- Blog drafts
- Dream logs
- Stray thoughts
- Tagged bookmarks (one file per bookmark, unlike other lists)
- Help me work through those lists by
- Making suggestion when I'm looking for something to read or watch, and updating the columns in those lists accordingly. When appropriate, asking for a review from me to add that to the list as well
- Providing writing prompts, reminding me to finish a blog, or finding connections between thoughts/notes
- Surface old notes for me to decide if they should be kept, pruned, or recombined
- Surface old files that may be interesting to revisit or write about
Help me research, learn, grow
Al should gather information off of the internet and present it to me in an appropriate way depending on if it's for research to answer specific questions, or to learn new concepts.
- Analyse codebases
- Clone an open source codebase into ~/src
- Launch a Claude Code session to analyse stack, architecture etc
- Produce a short report to be shared with me
- If the codebase is too large, then Claude code should not clone and simply browse the remote repo (e.g. on GitHub)
- Wait until I have no more questions before deleting the repo
- Help me plan tasks or software projects
- Research libraries or tools for me
- Launch a Claude Code session to plan a software project (architecture, functional decomposition, etc)
- Produce Kanbans in the PKM
- Help me learn new things
- Research a topic online and gather learning materials
- Organise those materials into a course with scheduled blocks
- Tutor me through those materials. Potentially create engaging podcasts timed to fit within e.g. train journeys
- Act as a therapist and coach
- Analyse my notes and journals at a regular cadence, comparing them to my growth goals and progress
- In timed blocks, act as a therapist to dissect that information, and a coach to help me towards my goals
More to come, stay tuned!
Building a better OpenClaw
I've completely changed my digital right hand to use OpenClaw for most of February, and while it was quite fun (and sometimes dangerous -- ask my colleagues about the Monzo API), I quickly found the cracks. These were not related to security as people might think, but rather reliability. I started logging mistakes not long after the switch in a MISTAKES.md, and the vast majority are related to the agent ignoring my instructions. This was usually caused by spotty memory (which is exacerbated by the agent forgetting to remember things as instructed) as well as some deeper architectural issues.
Overall, I think this is mostly fixable, but I would have to just rebuild it from scratch, in a much simpler and more principled way, based on what I've learned. I'm a big believer in the future where single-user apps will proliferate, so I think it's more important to align on the right principles than implementation-specific things like what integrations you use.
1: Text is king
I've written about this before, so I'll summarise with the Unix Philosophy:
Write programs that do one thing and do it well. Write programs to work together. Write programs that handle text streams, because that is a universal interface.
An LLM's whole thing is text, so we should lean heavily into that.
2: Code is text
Therefore code is king too. Any abstraction over taking actions is unnecessary, beside the ability to use a CLI. General-purpose agents work better with a reduced instruction set. We don't need plugins and tools and MCPs etc (although it's great that the MCP hype is pushing people to make their products machine-accessible).
An agent with a CLI can use cURL to talk to your REST API. It can learn new CLI tools faster than you can, through a man page or --help. It can write scripts to solve hard tasks. Code is already a problem-solving language, and there was a hell of a lot of training data, so agents are really good at this. They can also write tests and fix bugs iteratively. Don't kneecap it by inventing some new protocol because you think you're making things better.
3: Use human products
OpenClaw did one thing very well, which is to have human chat apps as first-class integrations. You should not invent yet another web chat UI -- take the conversation to where humans already are and where they talk to other humans. Yes, WhatsApp doesn't have text streaming and markdown table rendering etc, but I suspect over time these spaces will be more agent-friendly.
However, OpenClaw did not go all the way. You should not use cron jobs for scheduling, you should use a calendar. You should not use a markdown file in some internal workspace directory to plan, you should use a Kanban board.
"But Yousef", you lament, "didn't you just say they should live in the CLI?". Yes, but they should use human products from the CLI. The products should be the same, but not necessarily the interfaces, even if over time interfaces are shifting towards conversation. They can be different for humans and agents. Agents can interact with these products via their API, not browser use. Some examples:
- My OpenClaw instance has its own Google Calendar, with software that fires hooks when a new event starts. I have access to this calendar too for visibility, but I can also easily modify it.
- I can see all the OpenClaw workspace files as they're symlinked out of my Obsidian vault. This means I get markdown rendering/editing as well as backups for free. I use an Obsidian plugin too that can render markdown files in a certain format as a Kanban board, which OpenClaw barely needed any information to know how to use.
- The future of building software is not in a Claude Code terminal, but in your project management software. I use Linear, which already supports assigning tickets to agents. You should talk to these agents in the Linear comments, like you would a human engineer, and you can review their work in PRs on GitHub, again just like you would a human engineer. Linear has an MCP server, but it's not needed, as my agents know the
linearisCLI tool. They create new tickets for me through that all the time.
4: Policy beats memory
An agent's memory should just be the chat log. By all means store that, but you should never need to check it unless its relevant to the task at hand, just like a human will only search their chat history to get something, but it's a terrible way to stay organised or remember things. Chat should be ephemeral by nature.
Agents should act on anything important immediately and not rely on chat. This means remembering a new workflow for example. Agents should have their own permanent notes, just like a human may have a personal knowledge base. Just like humans, quality beats quantity, so the Digital Garden should remain curated. It's not a journal or a blog.
Both the agent and the human should maintain policy together. Policy can exist in many forms, but for a general-purpose agent, it's good to organise these so that they're pulled on demand. An example of this is Claude's Agent Skills where each skill contains detailed descriptions and other resources for a specialised workflow.
The crucial part is that the main prompt should inform the agent where these skills live, how to unpack one, and most importantly, under which conditions to unpack one. The goal is to solve scaling a sprawl of skills (say that 10 times fast). A single skill may be as thin as "here's a new command line tool that does X", it just doesn't need to be in context all the time.
Full disclosure: at my startup this is the exact problem we're solving. Getting policy (e.g. some niche knowledge about your domain) out of your head and into your agent, and keeping this internally consistent without ambiguity or contradiction. Every mistake that your agent makes is an opportunity for policy refinement.
There are other problems that need to be solved, e.g. access control: can you guardrail your agents in a guaranteed way (software) that is granular/flexible enough but still easy to use and doesn't ask you for a million permissions? These are all subsets of strong policy.
I'm starting to believe that anything additional to this (e.g. creating "planning modes" or orchestrator agents, or allowing the agent to spin up sub-agents, or even just compacting chat history instead of truncating) just gets in the way and often backfires. I suspect all these attempts at juicing agents will just become less and less useful over time as the models get better at a more foundational level.
Thoughts on the future of software
The way I like to speculate about the future of software is by imagining that you have infinite engineering resources. The other day, someone mentioned that they don't want to try PicoClaw (or any of the other spin-offs) because they'll miss out on cool features of the biggest project with the most contributions.
My uncontroversial prediction is that there will be a lot more hyper-personalised software, even products for single users, because that problem will go away. Agents will watch other projects for updates, or the internet for cool ideas, and instantly implement them. Commercial software in competitive spaces will quickly reach feature-parity and stay there, and it'll be harder to differentiate.
A lot of open source software today struggles because the commercial models around them don't work. People can donate money to the developers sometimes (very little in practice) or their time through contributions. A lot of open source software stalls and dies.
With infinite engineering resource, even if it's not completely free, there may be a commercial model where people share the token costs, instead of paying a subscription for a product. Then as long as people keep contributing, features keep getting developed. The more users a product has, the cheaper it becomes to develop.
The downside is there will be a pressure not to fork that software, because the userbase gets reset to 1. It's open source, but instead of donating to devs, or donating your time, you're donating tokens. But if you fork because the maintainers don't like your feature suggestion, and you want it anyway, suddenly you (or rather your agents) have to maintain that fork.
However, I suspect that this will become extremely cheap, in the same way that storage has become cheap. Cost will not be the bottleneck -- you'll be able to clear your product backlog faster than you can fill it. So the asymptote here is that there just won't be any maintainers anymore except your agents, making you your own personal software suite.
My hope is that there will be better interoperation between all this sprawl of software. It's hard to predict as I think the interfaces will change drastically (especially agent-to-agent communication). Collaborative software or social media may be the last to go, as they still have reasons for being unified (technical, or because of network effects and intentional walled-garden-ness).
Data is the only real moat left for SaaS founders. Speaking of data, I think data brokers are in big trouble if everyone starts building their own consumer apps. I would say this is overall a good thing.
Sentinel is now Al
It's been a while since I've written about the bot formerly known as Sentinel. It has continued to evolve, with the most significant change being a switch from Node-RED to n8n. Over the past couple weeks, there has been an even more fundamental shift however: a brain transplant. One that has prompted me to rename Sentinel to Al (that's Al with an L).
The fact that it looks like AI with an i is a coincidence -- it comes from the Arabic word for "machine", and I also decided to start referring to Al as "him" rather than "it" for convenience. Rather than an "assistant", I position Al as an digital extension of myself and the orchestrator of my exocortex[1], while I'm his meatspace extension.
The big shift is that I've jumped on the OpenClaw bandwagon! People have mixed views on OpenClaw, but I can say that overall I find it quite exciting. I, like many people, have fully embraced the use of Claude Code, and have been trying to retrofit it to do more than simply build software. OpenClaw looks like the beginning of an ecosystem that allows us all to do just that without all rolling our own disparate versions.
OpenClaw embraces a concept that I find so fundamental as to be laughably obvious: the interface to chat bots should be existing chat apps. This is why Sentinel and Amarbot had their own phone numbers. While I have used Happy (and later HAPI, self-hosted on https://hapi.amar.io) in order to access my Claude Code sessions from mobile without the insanity of a mobile terminal, even those felt like anti-patterns. You can read more on why I think this is in my post on why we should interact with agents using the same tools we use for humans, as well as my post on agent chat interfaces in general.
For the record, I think these mode of interaction are inevitable, not a preference. While AI will interface with things via APIs, raw text, or whatever else, the bridge between AI and human will be the same tools as between human and human. This is also why I think the UIs purporting to be the "next phase" of agentic work where you manage parallel agents (opencode, conductor, etc) are the wrong path. The people who got this absolutely bang-on correct are Linear, with Linear for Agents, and I don't just say that because I love Linear (I do). I should assign tickets to agents the same way I would a human, and have discussions with them on Linear or Slack, the same way I would a human.
So, that brings me to what I think OpenClaw is currently bad at. First, cron should not be used as a trigger. Calendars should. Duh. One of the first things I did was give Al his own calendar and set up appropriate hooks. We need to be using the same tools, and I never use cron. This gives me a lot of visibility over what's going on that is much more natural, and I can move around and modify these events in the way they're supposed to be: through a calendar UI, not through natural language conversation.
On the topic of visibility, workspace files need to be easily viewable and editable. By this I mean all the various markdown files that form the agent's memory and instructions. While I may not need to edit these and Al can do that on his own, if we do want to explicitly edit, it should be easy to do so, and natural language conversation is not the way (this is not code)! To solve this, I've put Al's brain into my Obsidian vault (yes, the very vault from which these posts are published!) and symlinked it into the actual OpenClaw directory. So now I have can browse these files with a markdown editor heavily optimised for me! An added bonus of this is that Al's brain is now replicated across all my devices and backups for free, using Syncthing which already covers my vault.
It's still early days, so I'm still finding out the best ways to collaborate with Al. There are still a lot of issues, mainly related to Al forgetting things, that I'm working through, but it's been great! He can do everything that Sentinel already could, including talk to other people independently and update my lists. The timing is perfect, as I pre-ordered a Pebble Index 01[2] and this will very likely be the primary way that I communicate with Al in the future when it comes to those one-way commands. For two-way, I still use my Even G1 smart glasses, but I suspect that I may go audio-only in the future (i.e. my Shokz OpenComm2 as I don't like having stuff in my ears).
I've scheduled some sessions with Al where we try and push each other to grow. For him, this means new capabilities and access to new things and various improvements. For me, this means learning about topics that Al has broken down into a guided course or literal coaching. I'll post more as I go along! In the meantime, you can also chat with him.
This is a term I took from Charles Stross' novel Accelerando which refers to the cloud of agents that support a human, and I was delighted to see the lobster theme in OpenClaw. I don't know if they were inspired by Accelerando, but sentient lobsters play a role! ↩︎
This device is controversial in its own right because of the battery that cannot be charged/replaced. When I watched the founder's video though, I was sold, as everything he said resonated. I suspect I won't use it for longer than 2 years anyway as I'll have probably moved on to something else by then. Incidentally, the founder is also the founder of Beeper, which I use for messaging, and which Al has access to through its built-in MCP server. ↩︎
AI can indeed do our jobs
Cory Doctorow, the famous sci-fi author who coined Enshittification, recently wrote an article about a future where AI serves us versus where we serve it. In the first case, AI helps us and catches our mistakes, for example as a second opinion on a radiologist's work. In the second, it does the bulk of the work, jobs get lost, and the remaining juniors check its work, but mostly act as a scapegoat when both AI radiologist and junior doctor miss the tumour.
I think there are problems with this view. First off, in many cases, AI is simply better than humans. I don't mean that it's more productive / doesn't get tired etc, but rather that when it comes to spotting tumours, for a narrow use case, it has a lower rate of false positives and false negatives than humans. So I was surprised that he used that example. You can also just replace AI with "software" in many cases (or hardware: a 4-row harvester might not get all potatoes, but its still better than a human with a tiller). If you add in fatigue as well, then it would be crazy to let humans operate heavy machinery or even drive a car, if statistically the roads are safer with AI at the wheel. To add to that, it kind of says the opposite of his first point: shouldn't AI overlords checking your work be the dystopian future, while humans wrangling fleets of AI be the future that puts us in control?
The second issue is around the idea that juniors keep their jobs and expensive, mouthy seniors are the ones getting fired. I can't speak for the medical profession, but at least in software engineering (which he touches on), that is certainly not the case, according to a 2025 Stanford study. Anecdotally, I see this too -- because these models are not (yet) that good, they're equivalent to a highly productive junior to mid-level engineer, and they need a senior to supervise them, just as you would need to supervise junior humans. And when a junior human messes up, you're accountable as their manager, which is as it should be.
I must say though, especially in the past few months, they've gotten better than most humans. They don't really make the kinds of mistakes Cory talks about anymore, so long as you use them properly (e.g. have them run a linter to catch their own syntax errors, make them write and run their own unit tests, etc). The same way you would help a junior developer not make mistakes. It's possible Cory's thinking about the code agents of ~6 months ago, which shouldn't feel like an eternity, but it is in this case! People have already adapted.
The consequence of this is that entry-level jobs are disappearing, and the demand for seniors has actually gone up. I don't say that out of denial (disclaimer: I'm as senior as it gets and the CTO of an AI company). This is because the path to become a senior is suddenly very narrow and there are fewer and fewer future seniors. The only way out is if AI gets good enough, fast enough, to also take the senior role. But for now, companies will fire (or more accurately, not hire) 10 juniors in favour of 1 senior with a Claude Max subscription. I suspect that we will see a lot more solo-founder startups appear as a result of this.
The true risk here is knowledge collapse, where if it doesn't get good enough (or if one day all AI disappeared for some reason), suddenly there's nobody left who can fix the machines that build machines, or the final machines. This happens in less dramatic ways all the time with technology and automation, and sometimes there are specialists left that still know the Old Ways and we don't need to build the knowledge again from first principles.
I agree that of course there's an AI bubble, and it will pop despite the fact that AI is genuinely useful (the same way that the internet is useful, and the dotcom bubble had to pop). However, I don't think we need to do anything to help it along -- it will pop no matter what. In the final two paragraphs Cory tries to explain what it is we need to do to pop the bubble in a way that minimises harm to people. He says we should become aware of the fact that AI can't actually do our jobs. But it can and it is!
Build smaller agents that ask for help
Disclaimer: I originally wrote this post a few months ago on a flight, and decided not to publish it at the time. I did so as I have a rule that when 3 or more people ask me the same question, I write my answer down. I changed my mind now and decided to publish, but things move fast in this space, so bear that in mind.
More and more the topic of Agents with unlimited tools comes up. It came up again as Anthropic is trying to set a standard for interfaces to tools through MCP. It has come up enough times now that I thought I'd write down my thoughts, so I can send this to people the next time it comes up. I actually think MCP is quite a badly designed protocol, but this post will not be about that. Instead, we'll go a bit more high-level.
What is an agent?
In the context of LLMs, it's a prompt or loop of prompts with access to tools (e.g. a function that checks the weather). Usually this looping is to give it a way to reason about what tools to use and continue acting based on the results of these tools.
I would therefore break down the things an agent needs to be able to do into 3+1 steps:
- Reason about which tools to use given a task
- Reason about what parameters to pass to those tools
- Call the tools with those parameters and optionally splice the results into the prompt or follow-up prompt
- Rinse and repeat for as many times as are necessary
For example, agent might have access to a weather function, a contact list function, and an email function. I ask "send today's weather to Bob". It reasons that it must first query the weather and the contact list, then using the results from those, it calls the email function with a generated message.
Why can't this scale?
The short answer is: step #1. A human analogue might be analysis paralysis. If you have one tool, you only need to decide if you should use it or not (let's ignore repeat usage of the same tool or else the possible combinations are infinite). If you have two, that decision is A, B, AB, BA. The combinations explode factorially as the number of tools increase.
Another analogue is Chekhov's gun. This is sort of like the reverse of the saying "if all you have is a hammer, everything looks like a nail". Agents have a proclivity to use certain tools by virtue of their mere existence. Have you ever had to ask GPT to do something but "do not search the internet"? Then you'll know what I mean.
Not to mention the huge attack surface you create with big tool libraries and data sources through indirect prompt injection and other means. These attacks are impossible to stop except with the brute force of very large eval datasets.
A common approach to mitigate these issues is to first have a step where you filter for only the relevant tools for a task (this can be an embedding search) and then give the agent access to only a subset of those tools. It's like composing a specialist agent on the fly.
This is not how humans think. Humans break tasks down into more and more granular nested pieces. Their functions unfold to include even more reasoning and even more functions; they don't start at the "leaf" of the reasoning tree. You don't assemble your final sculpture from individual Legos, you perform a functional decomposition first.
Not just that, but you're constraining any creativity in the reasoning of how to handle a task. There's also more that can go wrong -- how do I know that my tool search pass for the above query will bring back the contacts list tool? I would need to annotate my tools with information on possible use cases that I might not yet know about, or generate hypothetical tools (cf HyDE) to try and improve the search.
How can I possibly know that my weather querying tool could be part of not just a bigger orchestra, but potentially completely different symphonies? It could be part of a shipment planning task (itself part of a bigger task) or making a sales email start with "Hope you're enjoying the nice weather in Brighton!". Perhaps both of these are simultaneously used in an "increase revenue" task.
Let's take a step back...
Why would you even want these agents with unlimited tools in the first place? People will say it's so that their agents can be smarter and do more. But what do they actually want them to do?
The crux of the issue is in the generality of the task, not the reasoning of which tools help you achieve that task. Agents that perform better (not that any are that good mind you) will have more prompting to break down the problem into simpler ones (incl CoT) and create a high level strategy.
Agents that perform the best are specialised to a very narrow task. Just like in a business, a generalist solo founder might be able to do ok at most business functions, but really you want a team that can specialise and complement each other.
What then?
Agents with access to infinite tools are hard to evaluate and therefore hard to improve. Specialist agents are not. In many cases, these agents could be mostly traditional software, with the LLM merely deciding if a single function should be called or not, and with what parameters.
There's a much more intuitive affordance here that we can use: the hierarchical organisation! What does a CEO do when they want a product built? They communicate with their Head of Product and Head of Engineering perhaps. They do not need to think about any fundamental functions like writing some code. Even the Head of Engineering will delegate to someone else who decomposes the problem down further and further.
The number of decisions that one person needs to make is constrained quite naturally, just as it is for agents. You can't have a completely flat company with thousands of employees that you pick a few out ad-hoc for any given task.
Why is this easier?
The hardest part about building complicated automation with AI is defining what right and wrong behaviour is. With LLMs, this can sometimes come down to the right prompt. Writing the playbook for how a Head of Engineering should behave is much easier if you ask a human Head of Engineering, than it is to define the behaviour of this omniscient octopus agent with access to every tool. Who're you going to ask, God?
The administration or routing job should be separate from the executor job. It's a different task so should have its own agent. This is kind of similar to a level down with Mixture of Experts models -- there's a gate network or router that is responsible for figuring out which tokens go to which expert. So why don't we do something similar at the agent level? Why go for a single omniscient expert?
What if you're building a fusion reactor?
You cannot build a particle physicists agent without an actual particle physicist to align it. So what do you do? Why would a particle physicist come to you, help you build this agent, and make themselves redundant?
They don't need to! Just as when you hire someone, you don't suddenly own their brain, similarly the physicist can encode their knowledge into an agent (or system of agents) and your organisation can hire them. They own their IP.
At an architectural level, these agents are inserted at the right layer of your organisation and speak the same language on this inter-agent message bus.
The language: plain text
We've established why Anthropic has got it wrong. A Zapier/Fivetran for tools is useless. That's not the hard part. Interface standards should not be at the function level, but at the communication level. And what better standard than plain text? That's what the LLMs are good at, natural language! What does this remind you of? The Unix Philosophy!
Write programs that do one thing and do it well. Write programs to work together. Write programs that handle text streams, because that is a universal interface.
How about we replace "programs" with "agents"? And guess what: humans are compatible with plain text too! An agent can send a plain text chat message, email, or dashboard notification to a human just as it can another agent. So that physicist could totally be a human in an AI world. Or perhaps the AI wants to hire a captcha solver? Let's leave that decision to our Recruiter agent -- it was aligned by a human recruiter so it knows what it's doing.
A society of agents
I'm not about to suggest that we take the hierarchy all the way up to President. Rather, I think there's an interesting space, similar to the "labour pool" above, for autonomous B2B commerce between agents. I haven't been able to get this idea out of my head ever since I read Accelerando, one of the few fiction books I've read several times. In it, you have autonomous corporations performing complicated manoeuvres at the speed of light.
I can see a glimpse of this at the global "message bus" layer of interaction above the top-level agent, with other top-level agents. If you blur the lines between employment and professional services, you can imagine a supplier sitting in your org chart, or you can imagine them external to your org, with a contact person communicating with them (again, not by API but by e.g. email).
Conclusion
For this space of general tasks like "build me a profitable business", the biggest problem an agent faces is the "how". The quality of the reasoning degrades as the tasks become broader. By allowing as many agents as needed to break the problem down for us, we limit the amount of reasoning an agent needs to do at any given point. This is why we should anthropomorphise AI agents more -- they're like us!
Pixie: Entry to Mistral x a16z Hackathon
This post documents my participation in a hackathon 2 weeks ago. I started writing this a week ago and finished it now, so it's a little mixed. Scroll to the bottom for the final result!
Rowan reached out asking if I'm going to the hackathon, and I wasn't sure which one he meant. Although I submitted a project to the recent Gemini hackathon, it was more of an excuse to migrate an expensive GPT-based project ($100s per month) to Gemini (worse, but I had free credits). I never really join these things to actually compete, and there was no chance a project like that could win anyway. What's the opposite of a shoo-in? A shoo-out?
So it turns out Rowan meant the Mistral x a16z hackathon. This was more of a traditional "weekend crunch" type of hackathon. I felt like my days of pizza and redbull all-nighters are long in the past by at least a decade, but I thought it might be fun to check out that scene and work on something with Rowan and Nour. It also looked like a lot of people I know are going. So we applied and got accepted. It seems like this is another one where they only let seasoned developers in, as some of my less technical friends told me they did not get in.
Anyway, we rock up there with zero clue on what to build. Rowan wants to win, so is strategising on how we can optimise by the judging criteria, researching the background of the judges (that we know about), and using the sponsors' tech. I nabbed us a really nice corner in the "Monitor Room" and we spent a bit of time snacking and chatting to people. The monitors weren't that great for working (TV monitors, awful latency) but the area was nice.
Since my backup was a pair of XReal glasses, a lot of people approached me out of curiosity, and I spent a lot of time chatting about the ergonomics of it, instead of hacking. I also ran into friends I didn't know would be there: Martin (Krew CTO and winner of the Anthropic hackathon) was there, but not working on anything, just chilling. He intro'd me to some other people. Rod (AI professor / influencer, Cura advisor) was also there to document and filmed us with a small, really intriguing looking camera.
We eventually landed on gamifying drug discovery. I should caveat that what we planned to build (and eventually built) has very little scientific merit, but that's the goal of a hackathon; you're building for the sake of building and learning new tools etc. Roughly-speaking, we split up the work as follows: I built the model and some endpoints (and integrated a lib for visualising molecules), Nour did the heavy-lifting on frontend and deploying, and Rowan did product design, demo video, pitch, anything involving comms (including getting us SSH access to a server with a nice and roomy H100), and also integrated the Brave API to get info about a molecule (Brave was one of the sponsors).
You're probably wondering what we actually built though. Well, after some false starts around looking at protein folding, I did some quick research on drug discovery (aided by some coincidental prior knowledge I had about this space). There's a string format for representing molecules called SMILES which is pretty human-readable and pervasive. I downloaded a dataset of 16k drug molecules, and bodged together a model that will generate new ones. It's just multi-shot (no fine-tuning, even though the judges might have been looking for that, as I was pretty certain that would not improve the model at all) and some checking afterwards that the molecule is physically possible (I try 10 times to generate one per call, which is usually overkill). I also get some metadata from a government API about molecules.
On the H100, I ran one of those stable diffusion LORAs. It takes a diagram of a molecule (easy to generate from a SMILES string) and then does img2img on it. No prompt, so it usually dreams up a picture of glasses or jewellery. We thought this was kind of interesting, so left it in. We could sort of justify it as a mnemonic device for education.
Finally, I added another endpoint that takes two molecules and creates a new one out of the combination of the two. This was for the "synthesise" journey, and was inspired by those games where you combine elements to form new things.
Throughout the hackathon, we communicated over Discord, even though on the Saturday, Rowan and I sat next to each other. Nour was in Coventry throughout. It was actually easier to talk over Discord, even with Rowan, as it was a bit noisy there. Towards the end of Saturday, my age started to show and I decided to sleep in my own bed at home. Rowan stayed at the hackathon place, but we did do some work late into the night together remotely, while Nour was offline. The next day, I was quite busy, so Rowan and Nour tied up the rest of the work, while I only did some minor support with deployment (literally via SSH on my phone as I was out).
Finally, Rowan submitted our entry before getting some well-deserved rest. He put up some links to everything here, including the demo video.
Not long after the contest was over, they killed the H100 machines and seem to have invalidated some of the API keys also, so it looks like the app is also not quite working anymore, but overall it was quite fun! We did not end up winning (unsurprisingly) but I feel like I've achieved my own goals. Rowan and Nour are very driven builders who I enjoyed working with, and CodeNode is a great venue for this sort of thing. The next week, Rowan came over to my office to co-work and also dropped off some hackathon merch. I ended up passing on the merch to other people, as I felt a bit like I might be past my hackathon years now!
First attempt at actually organising my bookmarks
In April 2023, I came across this article and found it very inspiring. I had already been experimenting with ways of visualising a digital library with Shelfiecat. The writer used t-SNE to "flatten" a higher-dimensional coordinated space into 2D in a coherent way. He noticed that certain genres would cluster together spatially. I experimented with these sorts of techniques a lot during my PhD and find them very cool. I just really love this area of trying to make complicated things tangible to people in a way that allows us to manipulate them in new ways.
My use case was my thousands of bookmarks. I always felt overwhelmed by the task of trying to make sense of them. I might as well have not bookmarked them as they all just sat there in piles (e.g. my Inoreader "read later" list, my starred GitHub repos, my historic Pocket bookmarks, etc). I had built a database of text summaries of a thousand or so of these bookmarks using Url summariser, and vector embeddings of these that I dumped into a big CSV file, which at the time cost me approximately $5 of OpenAI usage. This might seem steep, but I think at the time nobody had access to GPT-4 yet, and the pricing also wasn't as low. I had also I accidentally had some full-length online books bookmarked, and my strategy of recursively summarising long text (e.g. YouTube transcripts) didn't have an upper limit, so I had some book summaries as well.
Anyway, I then proceeded to tinker with t-SNE and some basic clustering (using sklearn which is perfect for this sort of experimentation). I wanted to keep my data small until I found something that sort of works, as sometimes processing takes a while which isn't conducive to iterative experimentation! My first attempt was relatively disappointing:
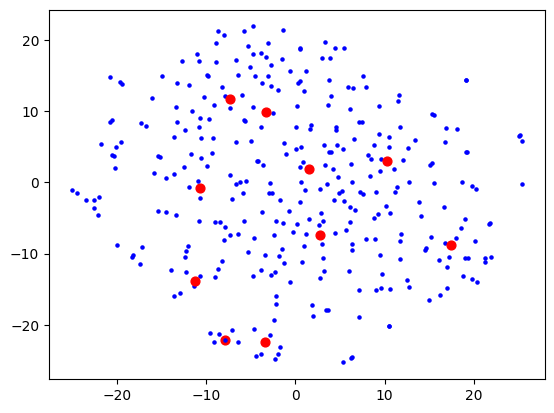
Here, each dot is a bookmark. The red dots are not centroids like you would get from e.g. k-means clustering, but rather can be described as "the bookmark most representative of that cluster". I used BanditPAM for this, after reading about it via this HackerNews link, and thinking that it would be more beneficial for this use case.
I was using OpenAI's Ada-2 for embeddings, which outputs vectors with 1536 dimensions, and I figured the step from 1536 to 2 is too much for t-SNE to give anything useful. I thought that maybe I need to do some more clever dimensionality reduction techniques first (e.g. PCA) to get rid of the more useless dimensions first, before trying to visualise. This would also speed up processing as t-SNE does not scale well with number of dimensions. Reduced to 50, I started seeing some clusters form:
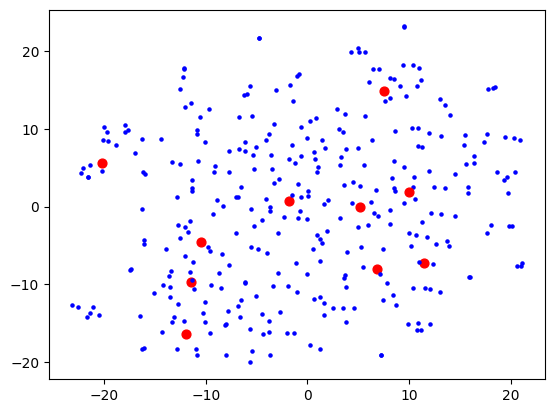
Then 10:
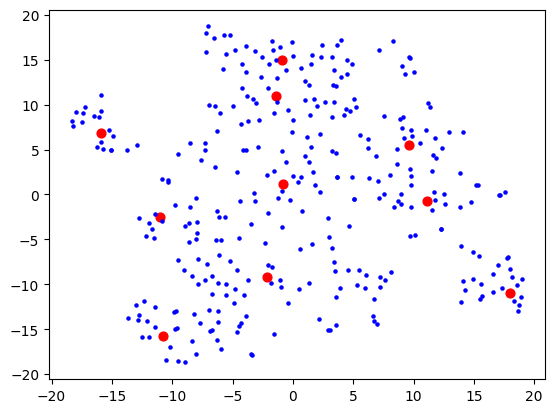
Then 5:
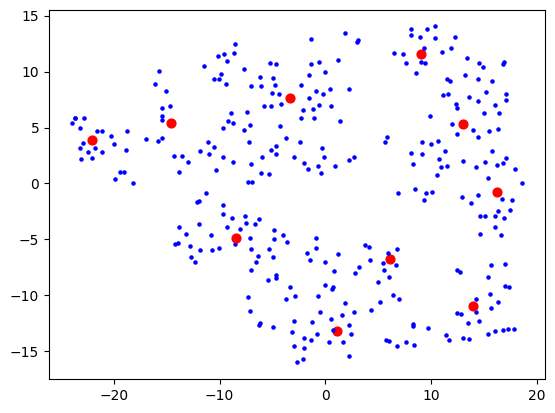
5 which wasn't much better than 10, so I stuck with 10. I figured my bookmarks weren't that varied anyway, so 10 dimensions are probably good enough to capture the variance of them. Probably the strongest component will be "how related to AI is this bookmark" and I expect to see a big AI cluster.
I then had a thought that maybe I should use truncated SVD instead of PCA, as that's better for sparse data, and I was picturing this space in my mind to really be quite sparse. The results looked a bit cleaner:
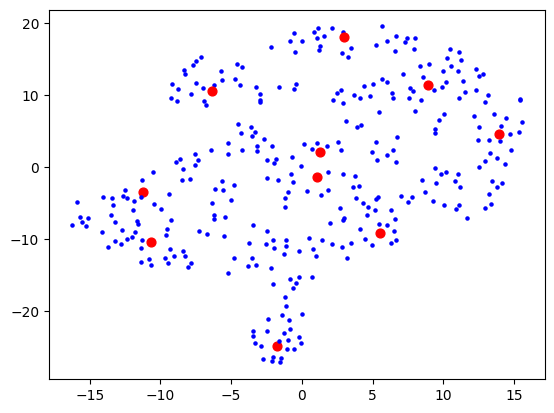
Now let's actually look at colouring these dots based on the cluster they're in. Remember that clustering and visualising are two separate things. So you can cluster and label before reducing dimensions for visualising. When I do the clustering over 1500+ dimensions, and colour them based on label, the visualisation is quite pointless:
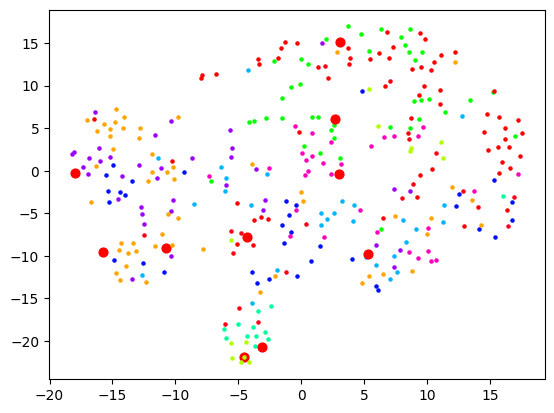
When I reduce the dimensions first, then we get some clear segments, but the actual quality of the labelling is likely not as good:
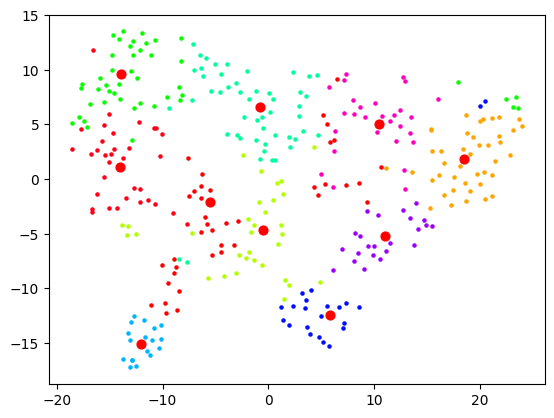
And as expected, no dimension reduction at all gives complete chaos:
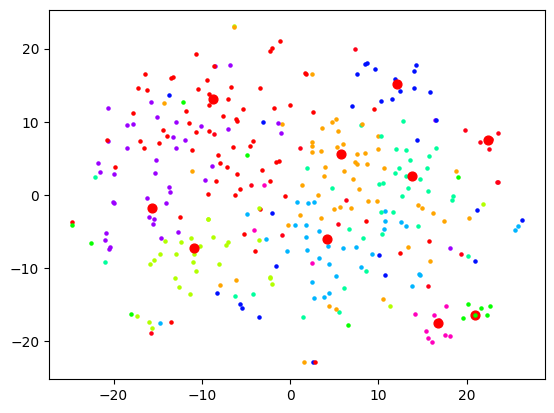
I started looking at the actual content of the clusters and came to a stark realisation: this is not how I would organise these bookmarks at all. Sure, the clusters were semantically related in some sense, but I did not want an AI learning resource to be grouped with an AI tool. In fact, did I want a top-level category to be "learning resources" and then that to be broken down by topic? Or did I want the topic "AI" to be top-level and then broken down into "learning resources", "tools", etc.
I realised I hadn't actually thought that much about what I wanted out of this (and this is also the main reason why I limited the scope of Machete to just bookmarks of products/tools). I realised that I would first need to define that, then probably look at other forms of clustering.
I started a fresh notebook, and ignored the page summaries. Instead, I took the page descriptions (from alt tags or title tags) which seemed in my case to be much more likely to say what the link is and not just what the content is about. This time using SentenceTransformer (all-MiniLM-L6-v2) as Ada-2 would not have been a good choice here, and frankly, was probably a bad choice before too.
I knew that I wanted any given leaf category (say, /products/tools/development/frontend/) shouldn't have more than 10 bookmarks or so. If it passes that threshold, maybe it's time to go another level deeper and further split up those leaves. This means that my hierarchy "tree" would not be very balanced, as I didn't want directories full of hundreds of bookmarks.
I started experimenting with Agglomerative Clustering, and visualising the results of that with a dendrogram:
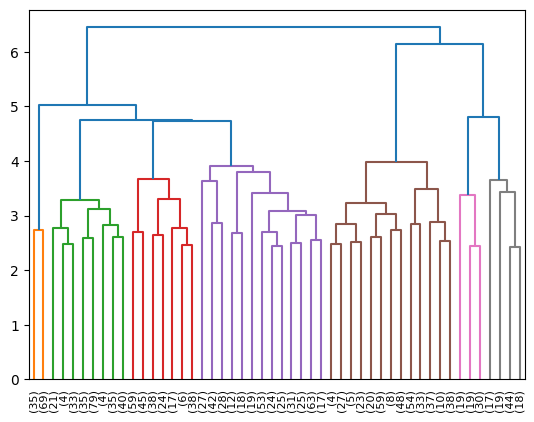
Looking at the where bookmarks ended up, I still wasn't quite satisfied. Not to mention, there would need to be maybe some LLM passes to actually decide what the "directories" should be called. It was at this point that I thought that maybe I need to re-evaluate my approach. I was inadvertently conflating two separate problems:
- Figuring out a taxonomy tree of categories
- Actually sending bookmarks down the correct branches of that tree
There's a hidden third problem as well: potentially adjusting the tree every time you add a new bookmark. E.g. what if I suddenly started a fishing hobby? My historical bookmarks won't have that as a category.
I thought that perhaps (1) isn't strictly something I need to automate. I could just go through the one-time pain of skimming through my bookmarks and trying to come up with a relatively ok categorisation schema (that I could always readjust later) maybe based on some existing system like Johnny•Decimal. I could also ask GPT to come up with a sane structure given a sample of files.
As time went on, I also started to spot some auto-categorisers in the wild for messy filesystems that do the GPT prompting thing, and then also ask GPT where the files should go, then moves them there. Most notably, this.
That seems to me so much easier and reliable! So my next approach is probably going to be having each bookmark use GPT as a sort of "travel guide" in how it propagates the tree. "I'm a bookmark about X, which one of these folders should I move myself into next?" over and over until it reaches the final level. And when the directory gets too big, we ask GPT to divide it into two.
The LLM hammer seems to maybe win out here -- subject to further experimentation!
Thoughts on chat as an interface
Chat as an interface has always been something I thought about a lot. After all, it's a close analogue to spoken conversation, our most natural form of communication.
The most basic chat interface is an input box and a chronological history of messages, so you can follow the conversation. Messages are often augmented with emojis etc to fill in the gaps for intonation and body language. If you need higher communication bandwidth, voice messages do it sometimes too. Advantages over face-to-face conversation is that text-based conversations have the option of being asynchronous and much longer-lived, potentially even pen-pal style correspondences.
Group conversations
The moment you start thinking about group conversations, some problems begin to be unearthed. One problem is it can get quite crowded, as you're sharing a linear chat history. It's hard to follow multiple threads of conversation that have been flattened into one, when in real life conversations can branch off and diverge.
This is a problem in video conferences too. While at a social event, groups naturally divide into smaller clusters of people in their own bubble of conversation, this has to be done explicitly in video conferences through breakout rooms and similar mechanics. Otherwise all the attention and spotlight is aimed at the person currently talking, which can throw off the dynamics.
I first noticed this phenomenon when I was running the Duolingo German language events in London. It's already common for people who don't know the language well to be shy about speaking up, but when covid started and we switched to Zoom, it was very easy for whomever is speaking to get stage fright, even if they're not normally shy. What then ends up happening is that two or three people will engage in conversation while the rest watch, unless the host (me in that case) takes control of the group dynamics. This was much easier to do in-person, especially where I could see the person's face and gauge how comfortable they are, so I don't put them on the spot (e.g. by bringing them into the conversation with simple yes/no questions).
Attempts at solutions
Anyway, during covid I became quite interested in products that try to solve these problems by capturing aspects of real-life communication through product design. I remember imagining a 2D virtual environment with spatial audio in the context of my PhD research. It turned out somebody was already building something similar: a fellow named Almas, and I remember having a call with him about SpatialChat (a conversation full of lovely StarCraft metaphors). This was an environment that allowed you to replicate the act of physically leaving a huddle and moving to a different cluster to talk. You could only be heard by those in "earshot".
A 2D game called Manyland did something similar with text-only, where text would appear above the head of your character as you were typing. This created interesting new dynamics and etiquette around "interrupting" each other, as well as things like awkward silences, which don't exist when you're waiting for someone to type. There was even an odd fashion around typing speed at one point.
Interestingly, you're not occupying space in the chat log by chatting; you're filling the space above your head, so you just need to find a good place to perch. Two people can respond to the same thing at the same time. However, one person can't quite multi-task their responses / threads without jumping back and forth between people, but after all that's how it works in real life too, no?
Reply chains and threads
I won't go over the history of different chat platforms and apps, but we've seen a lot of patterns that try and create some structure around communication, here in order from more ephemeral to less ephemeral:
- Quoting a message to reply to inline
- Ad-hoc threads that create a separated chat log
- More permanent threads akin to forums
- Permanent "topic" channels
I like to imagine conversations as trees, where branches can sprout and end just as fast. Have you ever been in an argument where someone rattles off a bunch of bad points, but you can only counter them in series? Each of your responses may in turn trigger several additional responses, and you get this exponentially growing tree and eventually you're writing essays dismantling every point one by one.
In real life, it's often hard to remember everything that was said, so you focus on just the most important parts. Or you deliberately prune the branches to the conversation doesn't become unwieldy. Some people like to muddy the waters and go off topic and it's up to you to steer the conversation back to the main trunk.
But not everything is a debate. A friend of mine figured that this tree, in 2D, ought to be the way to hold conversations. Big big internet conversations (he used social media as an example) are all adding nodes to far off branches of a huge tree. I quite like that picture. It would certainly allow for conversations to happen in parallel at the same time as you can hop back and forth between branches.
ChatGPT and the history tree
ChatGPT made the choice that chats should be linear, but you can start a new chat with a new instance of the AI at any time, and go back to old chats through the history tab. This seems to make sense for chatting with an AI assistant, but an anti-pattern emerges...
Have you ever gone down a conversation with ChatGPT only to realise that it's dug itself into a hole, so you scroll up to just after the last "good" message and edit the message to create a new, better timeline? I do this a lot, and it reminded me of undo/redo in text editors.
Undo and redo are normally linear, and if you go back in time and make a change, suddenly the old "future" is no longer accessible to you. We've all done it where we accidentally typed something after pressing undo a bunch of times to check a past version, losing our work.
Someone made a plugin for vim that allows you to navigate a tree of timelines that you create by undo-ing, sort of like automatic git branching and checkout. I feel like this ought to be a UI for interacting with ChatGPT too! Already this is being used for better responses and I feel like there must have been attempts at creating a UI like this, but I haven't seen one that does this elegantly.
Conclusion
This has been kind of a stream of though post, inspired by my post on resetting my AI assistant's chat memory, so I'm not entirely sure what the point I'm trying to make is. I think I'm mainly trying to narrow down the ergonomics of an ideal chat interface or chat in a virtual environment.
I think you would probably have some set of "seed" nodes -- the stem cells to your threads -- which are defined by individuals (i.e. DMs), or groups with a commonality, or topics. These would somehow all capture the nuances of real-life communication, but improve on that with the ability to optionally create ephemeral threads out of reply branches. I'm not yet sure what the UI would physically look like though.
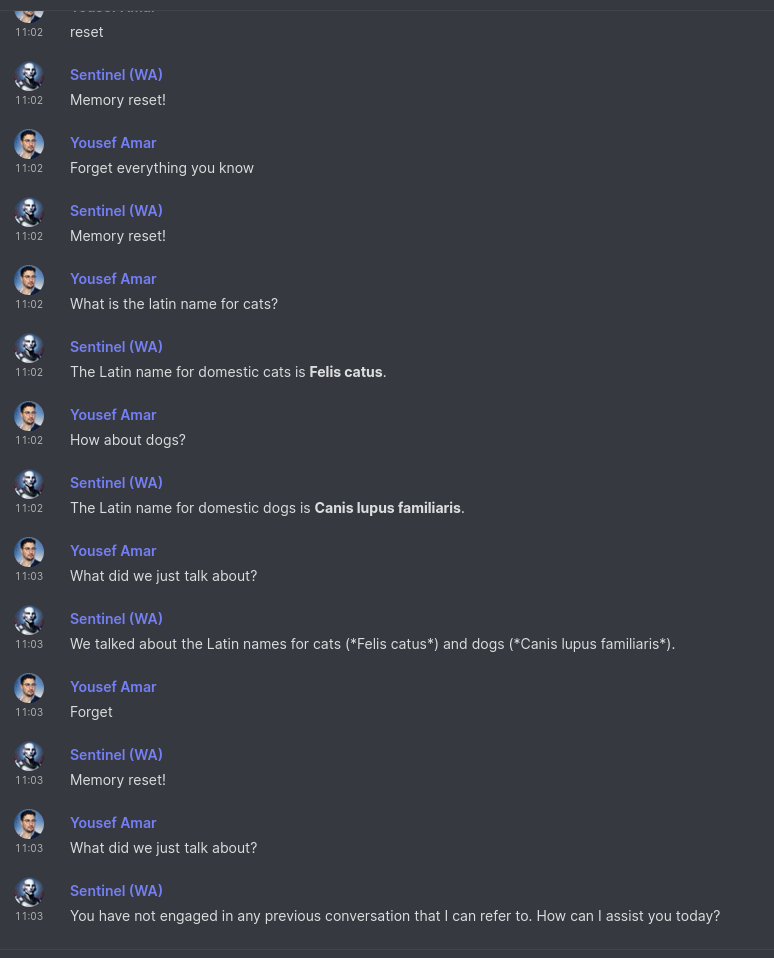
Sentinel gets a brain and listens to the internet
Sentinel, my AI personal assistant has evolved a bit since I last wrote about him. I realised I hadn't written about that project in a while when it came up in conversation and the latest reference I had was from ages ago. The node-red logic looks like this now:
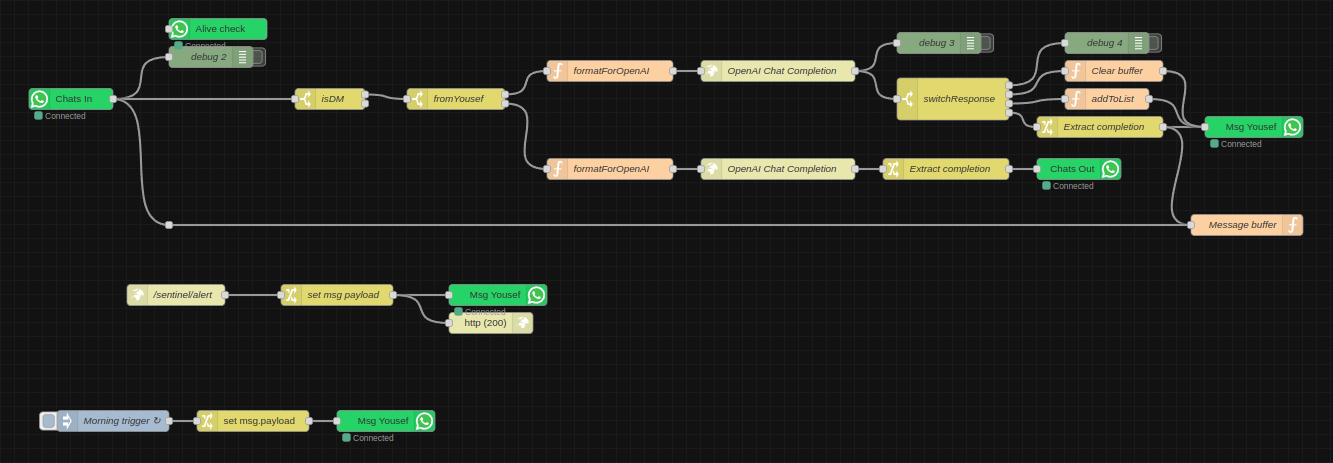
- Every morning he sends me a message (in the future this will be a status report summary). The goal of this was to mainly make sure the WhatsApp integration still works, since at the time it would crap out every once in a while and I wouldn't realise.
- I have an endpoint for arbitrary messages, which is simply a URL with a text GET parameter. I've sprinkled these around various projects, as it helps to have certain kind of monitoring straight to my chats.
- He's plugged in to GPT-4-turbo now, so I usually just ask him questions instead of going all the way to ChatGPT. He can remember previous messages, until I explicitly ask him to forget. This is the equivalent of "New Chat" on ChatGPT and is controlled with the functions API via natural language, like the list-adder function which I already had before ("add Harry Potter to my movies list").
As he's diverged from simply being an interface to my smart home stuff, as well as amarbot which is meant to replace me, I decided to start a new project log just for Sentinel-related posts.
Edit: this post inspired me to write more at length about chat as an interface here.
Thoughts on interfaces, AI agents, and magic
In UI design, Skeuomorphism is where UI elements look like their physical counterparts. For example, a button might have highlights/shadows, you might adjust time through slot-machine-like dials, or hear a shutter sound when you take a photo. I quite like skeuomorphic design.
I pay special attention to icons. My younger sister is young enough to have never used a floppy disk and therefore only knows this symbol 💾 to mean "save" but not why. You see it everywhere: icons (like a phone handset), language (like an "inbox"), and other tools (like the dodge and burn tools in photo editors, which stem from physical retouching on film).
Sometimes, words have gone through several layers of this, where they're borrowed over and over again. For me, one area where I see this a lot is in networks. In the days of radio and analogue electronics, we got a lot of new words that were borrowed from other things that people were already familiar with. Once computer networks came along, suddenly "bandwidth" adopted a different meaning.
The key here is this idea of familiarity. When something is new, it needs to be rooted in something old, in order for people to be able to embrace it, let alone understand it. Once they do, only then do you see design trends cut the fat (for example, the shiny Web 2.0 style made way for the more flat design we have today). If a time traveller from 20 years ago were to visit, of course they would find modern design and affordances confusing.
Take this a step further however: what about the things that never had a physical counterpart or couldn't quite be connected to one? Well, it seems we latch on to the closest available concept or symbol! For example, what exactly is "the cloud"? It never substituted water vapour in the sky; it was something new. Why is this ☰ the symbol for a hamburger menu? Because it sort of looks like items in a menu. Not to mention, why did we call it a hamburger menu? Because the symbol sort of looks like a hamburger.[1]
Anyway, why do I bring all this up? Because I noticed new words and icons showing up in the AI space, as AI is becoming more ubiquitous. AI assistance built into tools are becoming "copilots". The symbol for "apply AI" is becoming magic sparkles that look a bit like this ✨. I find this very interesting -- people seem to not quite have a previous concept to connect AI to other than "magic", and the robot emoji might be a little too intimidating 🤖 (maybe I should change the Amarbot triggering reaction to sparkles instead).
A couple days ago, this was trending on HackerNews, and sparked some conversation in my circles. As you might know, I have some interest in this space. It seemed to have some overlap with gather.town, a 2D virtual environment for work. This category really took off during covid. This product in particular has some big name backers (though not a16z ironically enough).
This got me thinking... AI agents would truly be first-class citizens in environments like these. You would interact with them the same way you interact with a human colleague. You could tell them "go tell Bob to have the reports ready by 2pm" and the agent would walk over to Bob's virtual desk, and tell them using the same chat / voice interface that a human would use.
How would agents interact with the outside world? LLMs already have an understanding of human concepts baked in. Why hack a language model to execute code (Code Interpreter) when you could use the same skeuomorphism that humans are good at, in an environment like this? If there's a big red button in the corner of your virtual office called "server restart button", a human as well as an AI agent can easily interact with that. Neither may ever know that this magic button does something in a parallel universe.
It might be some ways off before we're all working out of the metaverse, but I believe that the only way for that to happen is if it becomes more ergonomic than real life. It just so happens that this is great for humans as well as AI agents! There are already a class of tools that make you more productive in AR/VR than on a normal monitor (think 3D CAD). However when it comes to day-to-day working, organising your thoughts, communicating, etc, we still have some ways to go. To cross that bridge, we most likely need to embrace skeuomorphic design in the first instance.
What might that look like? Certainly storing information in space. Your desk top (and I don't mean "desktop", I mean literally the surface of your desk) can go 3D, and you can perhaps visualise directory trees in ways you couldn't before. Humans have excellent spatial reasoning (and memory) as my friend working on virtual mind palaces will tell you.
You could of course have physical objects map 1:1 to their virtual counterparts, e.g. you could see a server rack that represents your actual servers. However, instead of red and green dots on a dashboard, maybe the server can catch on literal fire if it's unhealthy? That's one way to receive information and monitor systems! A human as well as an AI agent can understand that fire is bad. Similarly, interactions with things can be physical, e.g. maybe you toss a book into a virtual basket, which orders a physical version of it. Maybe uploading a photo to the cloud is an actual photo flying up to a cloud?
Or maybe this virtual world becomes another layer for AI (think Black Mirror "White Christmas" episode), where humans only chat with a single representative that supervises all these virtual objects/agents, and talks in the human's ear? Humans dodge the metaverse apocalypse and can live in the real world like Humane wants?
Humans are social creatures and great at interacting with other humans. Sure, they can learn to drive a car, and no longer have to think about the individual actions, rather the intent, but nothing is more natural than conversation. LLMs are great at conversation too of course (it's in the name) and validates a belief that I've had for a long time that conversation may be the most widely applicable and ergonomic interaction interface.
What if my server was a person in my virtual workspace? A member of my team like any other? What if it cried if server health was bad? What if it explained to me what's wrong instead of me trawling through logs on the command line? I'm not sure what to call this. Is this reverse-skeuomorphism? Skeuomorphic datavis?
I might have a fleet of AI coworkers, each specialised in some way, or representing something. Already Sentinel is a personification of my smart home systems. Is this the beginning of an exocortex? Is there a day where I can simply utter my desires and an army of agents communicate with each other and interact with the world to make these a reality?
(Most) humans are great at reading faces (human faces that is, the same way Zebras can tell each other apart). This concept was explored in data visualisation before, via Chernoff faces. There are reasons why it didn't catch on but I find it very interesting. I was first introduced to this concept by the sci-fi novel Blindsight. In it, a vampire visualises statistical data through an array of tortured faces, as their brains in this story are excellent at seeing the nuance in that. You can read the whole novel for free online like other Peter Watts novels, but I'll leave the quote here for good measure:
A sea of tortured faces, rotating in slow orbits around my vampire commander.
"My God, what is this?"
"Statistics." Sarasti seemed focused on a flayed Asian child. "Rorschach's growth allometry over a two-week period."
"They're faces…"
He nodded, turning his attention to a woman with no eyes. "Skull diameter scales to total mass. Mandible length scales to EM transparency at one Angstrom. One hundred thirteen facial dimensions, each presenting a different variable. Principle-component combinations present as multifeature aspect ratios." He turned to face me, his naked gleaming eyes just slightly sidecast. "You'd be surprised how much gray matter is dedicated to the analysis of facial imagery. Shame to waste it on anything as—counterintuitive as residual plots or contingency tables."
I felt my jaw clenching. "And the expressions? What do they represent?"
"Software customizes output for user."
There are so many parallels between language and programming. For example, Toki Pona (a spoken language with a vocabulary of only 120 words) is like the RISC of linguistics. You need to compose more words together to convey the the same meaning, but it's quite elegant how you can still do that with so few words. It seems like languages don't need that large a vocabulary to be "Turing complete" and able to express any idea. Or maybe because language and thought are so tightly coupled, we're just not able to even conceive of ideas that we don't have the linguistic tools to express in the first place.
You can create subroutines, functions, macros in a program. You can reuse the same code at a higher level of abstraction. Similarly, we can invent new words and symbols that carry a lot more meaning, at the cost of making our language more terse. A language like Toki Pona is verbose because ideas are expressed from elementary building blocks and are context-dependent.
I imagine a day where abstractions layered on top of abstractions disconnect us from the underlying magic. You see a symbol like the Bluetooth icon and it has no other meaning to you except Bluetooth. In your virtual world, you interact with curious artefacts that have no bearing on your reality. You read arcane symbols as if they were ancient runes. You cast spells by speaking commands to underlings and ambient listeners that understand what you mean. Somewhere along the way, we can no longer explain how this has become a reality; how the effects we see actually connect to the ones and zeros firing. Is that not magic? ✨
This is sometimes called a drawer menu too, but the point still stands, as it slides out like a drawer. Other forms of navigation have physical counterparts too, like "tabs" come from physical folders. One you start noticing these you can't stop! ↩︎
Miniverse open source
I made some small changes to the Miniverse project. It still feels a bit boring, but I'm trying different experiments, and I think I want to try a different strategy, similar to Voyager for Minecraft. Instead of putting all the responsibility on the LLM to decide what to do each step of the simulation, I want to instead allow it to modify its own imperative code to change its behaviour when need be. Unlike the evolutionary algos of old, this would be like intelligent design, except the intelligence is the LLM, rather than the LLM controlling the agents directly.
Before I do this however, I decided to clean the codebase up a little, and make the GitHub repo public, as multiple people have asked me for the code. It could use a bit more cleanup and documentation, but at least there's a separation into files now, rather than my original approach of letting the code flow through me into a single file:

I also added some more UI to the front end so you can see when someone's talking and what they're saying, and some quality of life changes, like loading spinners when things are loading.
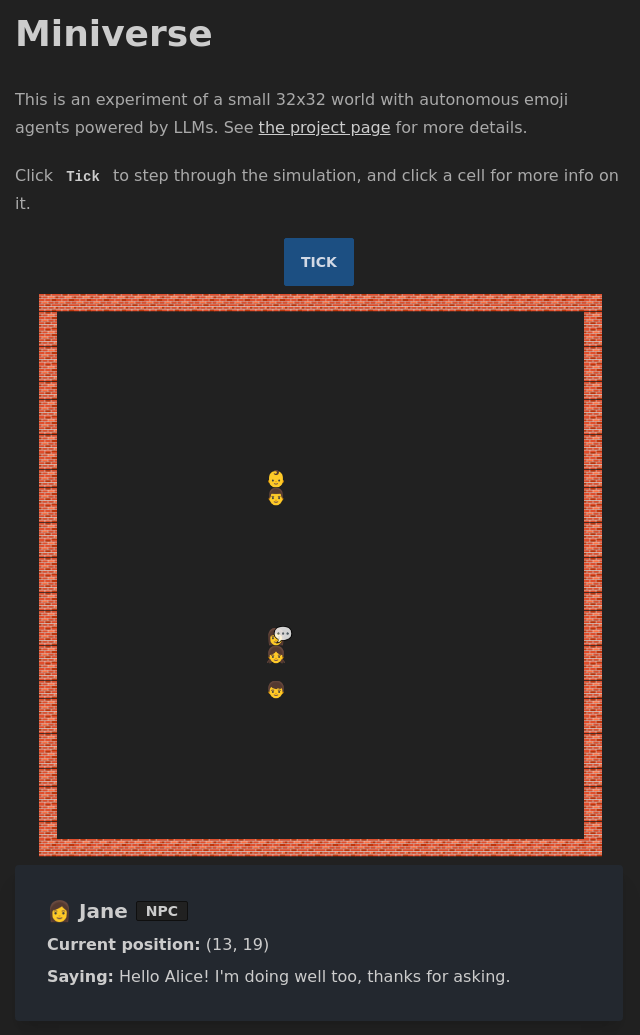
There's still a lot that I can try here, and the code will probably shift drastically as I do, but feel free to use any of it. You need to set the OPENAI_KEY environment variable and the fly.io config is available too if you want to deploy there (which I'm doing). The main area of interest is probably NPC.js which is where the NPC prompt is built up.
Amarbot merges into my cyborg self
Amarbot no longer has a WhatsApp number. This number now belongs to Sentinel, the custodian of Sanctum.
This number was originally wired up directly to Sanctum functions, as well as Amarbot's brain; a fine-tuned GPT-J model trained on my chat history. Since this wiring was through Matrix it became cumbersome to have to use multiple Matrix bridges for various WhatsApp instances. I eventually decided use that model on my actual personal number instead, which left Amarbot's WhatsApp number free.
Whenever Amarbot responds on my behalf, there's a small disclaimer. This is to make it obvious to other people whether it's actually me responding or not, but also so when I retrain, I can filter out artificial messages from the training data.
Sentinel: my AI right hand
I mentioned recently that I've been using OpenAI's new functions API in the context of personal automation, which is something I've explored before without the API. The idea is that this tech can short-circuit going from a natural language command, to an actuation, with nothing else needed in the middle.
The natural language command can come from speech, or text chat, but almost universally, we're using conversation as an interface, which is probably the most natural medium for complex human interaction. I decided to use chat in the first instance.
Introducing: Sentinel, the custodian of Sanctum.
No longer does Sanctum process commands directly, but rather is under the purview of Sentinel. If I get early access to Lakera (the creators of Gandalf), he would also certainly make my setup far more secure than it currently is.
I repurposed the WhatsApp number that originally belonged to Amarbot. Why WhatsApp rather than Matrix? So others can more easily message him -- he's not just my direct assistant, but like a personal secretary too, so e.g. people can ask him for info if/when I'm busy. The downside is that he can't hang out with the other Matrix bots in my Neurodrome channel.
A set of WhatsApp nodes for Node-RED were recently published that behave similarly to the main Matrix bridge for WhatsApp, without all the extra Matrix stuff in the way, so I used that to connect Sentinel to my existing setup directly. The flow so far looks like this:

The two main branches are for messages that are either from me, or from others. When they're from others, their name and relationship to me are injected into the prompt (this is currently just a huge array that I hard-coded manually into the function node). When it's me, the prompt is given a set of functions that it can invoke.
If it decides that a function should be invoked, the switchResponse node redirects the message to the right place. So far, there are only three possible outcomes: (1) doing nothing, (2) adding information to a list, and (3) responding normally like ChatGPT. I therefore sometimes use Sentinel as a quicker way to ask ChatGPT one-shot questions.
The addToList function is defined like this:
{
name: "addToList",
description: "Adds a string to a list",
parameters: {
type: "object",
properties: {
text: {
type: "string",
description: "The item to add to a list",
},
listName: {
type: "string",
description: "The name of the list to which the item should be added",
enum: [
"movies",
"books",
"groceries",
]
},
},
required: ["text", "listName"],
},
}I don't actually have a groceries list, but for the other two (movies and books), my current workflow for noting down a movie to watch or a book to read is usually opening the Obsidian app on my phone and actually adding a bullet point to a text file note. This is hardly as smooth as texting Sentinel "Add Succession to my movies list". Of course, Sentinel is quite smart, so I could also say "I want to watch the first Harry Potter movie" and he responds "Added "Harry Potter and the Sorcerer's Stone" to the movies list!".
The actual code for adding these items to my lists is by literally appending a bullet point to their respective files (I have endpoints for this) which are synced to all my devices via the excellent Syncthing. In the future, I could probably make this fancier, e.g. query information about the movie/book and include a poster/cover and metadata, and also potentially publish these lists.
Building the Miniverse
I've been experimenting with OpenAI's new functions API recently, mostly in the context of personal automation, which is something I've explored before without the API (more on that in the future). However, something else I thought might be interesting would be to give NPCs in a virtual world a more robust brain, like the recent Stanford paper. This came in part from the thinking from yesterday's post.
The Stanford approach had many layers of complexity and they were attempting to create something that is close to real human behaviour. I'm less interested in that, and would instead like to design an environment with much higher constraints based on simple rules. I think finding the right balance there leads to the most interesting emergent results.
So my first goal was to create a very tightly scoped environment. I decided to start with a 32x32 grid, made of emojis, with 5 agents randomly spawned. The edge of the grid is made of walls so they don't fall off.
 Agents after they had walked towards each other for a chat
Agents after they had walked towards each other for a chat
When I was originally scoping this out, I thought I would add mechanisms for interacting with items too. These items could be summoned in some way perhaps. I built a small API for getting the nearest emoji to item text as well, which is still up at e.g. https://gen.amar.io/emoji/green apple (replace "green apple" with whatever). It also caches the emojis so overall not expensive to run.
I also explored various models for generating emoji-like images, for the more fantastical items, and landed on emoji diffusion. It was at this point that I quickly realised I'm losing control of the scope, and decided to focus on NPCs only, and no items.
Each simulation step (tick) would iterate over all agents and compute their actions. I planned for these possible actions:
- Do nothing
- Step forward
- Step back
- Step left
- Step right
- Say X
- Remember X (doesn’t end round)
I wanted the response from OpenAI to only be function calls, which unfortunately you can't control, so I had to add to the prompt You MUST perform a single function in response to the above information. If I get any bad response, we either retry or fall back to "do nothing", depending.
The prompt contained some basic info, a goal, the agent's surroundings, the agent's memory (a truncated list of "facts"), and information on events of the past round. I found that I couldn't quite rely on OpenAI to make good choices, so I selectively build the list of an agent's capabilities on the fly each tick. E.g. if there's nobody in speaking distance, we don't even give the agent the ability to speak. If there's a wall ahead of the agent, we don't even give the agent the chance to step forward. And if the agent just spoke, they lose the ability to speak again for the following round or else they speak over each other.
I had a lot of little problems like that. Overall, the more complicated the prompt, the more off the rails it goes. Originally, I tried The message from God is: "Make friends" as I envisioned interaction from the user coming in the form of divine intervention. But then some of the agents tried speaking to God and such, so I replaced that with Your goal is: "Make friends", and later Your goal is: "Walk to someone and have interesting conversations" so they don't just walk randomly forever.
They would also feel compelled to try and remember a lot. Often the facts they remembered were quite useless, like the goal, or their current position. The memory was small, so I tried prompt engineering to force them to treat memory as more precious, but it didn't quite work. Similarly, they would sometimes go on endless loops remembering the same useless fact over and over. I originally had all information in their memory (like their name) but I didn't want them to forget their name, so put the permanent facts outside.
Eventually, I removed the remember action, because it really wasn't helping. They could have good conversations, but everything else seemed a bit stupid, like I might as well program it procedurally instead of with LLMs.
I did however focus a lot on having a very robust architecture for this project, and made all the different parts easy to build on. The server does the simulation (in the future, asynchronously, but today, through the "tick" button) and stores world state in a big JSON object that I write to disk so I can rewind through past states. There is no DB, we simply read/write from/to JSON files as the world state changes. The structure of the data is flexible enough that I don't need to modify the schemas, and it can remain pretty forwards-compatible as I make additions, so I can run the server off of older states and it picks up those states gracefully.
Anyway, I'll be experimenting some more and writing up more details on the different parts as they develop!
Breaking Gandalf
I love cracking hard problems. So it follows that I love CTFs, ARGs, even treasure hunts, and other puzzles of the sort.
I even tried my hand at creating these for other people. I'll talk about these more in the future, but one puzzle that I made came up in conversation, where I programmed a sage character in Manyland to give you hints for a key word that he confirms, which is needed for the next stage of the puzzle.
We were talking about how much more fun these puzzles can now be with the rise of LLMs. Back then, it was all quite procedural. But today, you could prompt an LLM to be the sage and not reveal the passphrase until the player has met certain conditions.
A week later my friend brought my attention to AI Gandalf. I LOVE this. I managed to make it through the main seven levels in around 20 minutes and get myself on the leaderboard, although my prompts weren't very creative. My friend had some much more creative prompts. If you haven't tried this, try it and let me know if you need any tips!
Now I'm stuck on the extra level 8 ("Gandalf the White"). This seems to be the ultra-hardened version that the developers have built from all the data they've gathered. I figured it must be possible, since there's a leaderboard, but it seems like they've actually been updating it on the fly whenever a new loophole is found.
It's driving me crazy! If anyone can come up with a solution, please give me a tip!
I can finally sing
Ever since I discovered the Discord server for AI music generation, I knew I needed to train a model to make my voice a great singer. It took some figuring out, but now I'm having a lot of fun making myself sing every kind of song. I've tried dozens now, but here are some ones that are particularly notable or fun (I find it funniest when things glitch out especially around the high notes):
Shap-E API
Some days ago, OpenAI released the code and models for Shap-E, which lets you do text-to-3D, and download a mesh you can use in any 3D software or for game development (rather than NeRFs with extra steps like previous models, and many papers that never released their code). This is very exciting, as the quality is reasonably good, and previously I would try to get that through various hacks.
There is already a HuggingFace space to try it, but no model on HuggingFace that you can easily use with their Inference API. You can fork the space and turn it into an API with some extra work, but I wasn't able to easily figure this out, and since running your own space is expensive anyway, I decided to take the easy way out and put a Flask server on top of OpenAI's existing code.
My server implementation is here. Since generating a new model only takes a couple seconds, I decided to design the interface as a "just-in-time" download link. You request /models/cat.ply, and if it's been generated before, it will download right away, but if not, then it's generated on the fly while the request is blocking.
I ran this on vast.ai, on an A10 instance, but I'm probably not going to keep it up for long as it's a bit expensive. I used the default pytorch image, and tweaked the config to expose the server on port 8081, which is a Docker port that vast.ai then maps to a port on the host. I added a proxy to that on my Model Compositor project which you can try here for free.
Dolly 2.0 - the Stable Diffusion of LLMs
Dolly 2.0, a recently released open-source LLM, is a big deal, but not because there's anything new or special about it, but rather specifically because it's legally airtight. Unlike the models that were fine-tuned based on the leaked LLaMA model (many of which Meta takes down), it's based on the EleutherAI pythia model family. The training data is CC licensed and was crowd-sourced from 5000 Databricks employees.
Since it's on Hugging Face Hub, you can use it with Langchain, and I expect that it will become the Stable Diffusion of LLMs. I think especially companies that legally can't send their data off to the US will flock to using Dolly.
I kind of like how there's still this theme of woolly hooved animals (in this case a sheep), but still a divergence from the LLaMA strain of models (llama, alpaca, vicuna). I don't like how it sounds too similar to "DALL-E 2" when spoken though.
LLM agents and plugins
I need to make a new update post on all the AI stuff. Things move so fast that I often just can't be bothered! I'm making this post mostly for myself and people who ask about something very specific.
LangChain recently announced classes for creating custom agents (I think they had some standard Agents before that too though). Haystack has Agents too, although it seems that their definition explicitly involves looping until the output is deemed ok, as most implementations need to do this anyway.
The way I understand this and see it implemented is that it's essentially an abstraction that allows LLMs (or rather, a pipeline of LLM functions) to use "tools". A tool could for example be a calculator, a search engine, a webpage retriever, etc. The Agent has a prompt where it can reason about which tool it's supposed to use, actually use these, and make observations, which it can then output.
It also allows for the decomposition of a task and taking it step by step, which can make the system much more powerful. It's a lot closer to how a human might reason. An example of this general idea taken to the extreme is Auto-GPT which you can send on its merry way to achieve some high level goal for you and hope it doesn't cost you an arm and a leg. Anyone remember HustleGPT btw?
There's something called the ReAct framework (Reasoning + Acting -- I know, unfortunate name) which is the common "prompt engineering" part of this, and prompts using this framework are usually built in to these higher-level libraries like LangChain and Haystack. You might also see the acronym MRKL (Modular Reasoning, Knowledge and Language, pronounced "miracle") being used. This comes from this older paper (lol, last year is now "old"), and it seems that ReAct is basically a type of MRKL system that is also able to "reason". They might be used interchangeably though and people are often confused about where they differ. The ReAct paper has much clearer examples.
A common tool is now, of course, embeddings search, which you can then chain to completion / chat. You might remember two months ago when I said at the bottom of my post about GPT use cases that this is where I think the gold dust lies. Back then, I had linked gpt_index; it's now called llama_index and has become relatively popular. It lets you pick what models you want to use (including the OpenAI ones still, unlike what the rename might suggest), what vector store you want to use (including none at all if you don't have loads of data), and has a lot of useful functionality, like automatically chopping up PDFs for your embeddings.
Not too long ago, OpenAI released their own plugin for this, that has a lot of the same conveniences. One surprising thing: OpenAI's plugin supports milvus.io as a vector store (an open-source, self-hosted version of the managed pinecone.io) while llama_index doesn't. I don't think it's worth messing around with that though tbh, and I think pinecone has one of those one-click installers on the AWS marketplace. If you're using Supabase, they support the pgvector extension for PostgreSQL, so you can just store your embeddings there, but from what I hear, it's not as good.
Of course, if you're subject to EU data regulations, you're going to use llama_index rather than send your internal docs off to the US. I say internal docs, because it seems everyone and their mother is trying to enter the organisational knowledge retrieval/assistant SaaS space with this. Some even raising huge rounds, with no defensibility (not even first-mover advantage). It's legitimately blowing my mind, and hopefully we don't see a huge pendulum swing in AI as we did crypto. We probably will tbh.
The only defensibility that may make sense is if you have a data advantage. Data is the gold right now. A friend's company has financial data that is very difficult to get a hold of, and using llama_index, which is the perfect use. Another potential example: the UK government's business support hotline service is sitting on a treasure trove of chat data right now also. Wouldn't it be cool to have an actually really good AI business advisor at your beck and call? Turn that into an Agent tool, and that's more juice to just let it run the business for you outright. Accelerando autonomous corporation vibes, but I digress!
Personally, I would quite like an Obsidian plugin to help me draw connections between notes in my personal knowledge base, help me organise things, and generally allow me to have a conversation with my "memory". It's a matter of time!
Statue inpainting
I can't imagine I'm the first to try this, but new hobby acquired:
- Go to the British Museum (other museums with statues will work too!)
- Find broken statues
- Take a photo
- Erase the gaps (DALL-E 2 lets you upload and edit on the fly)
- Write the name of the piece as the prompt, with the date
- Use image inpainting to fill in the rest of the statue
I ran the ones below on the spot and it was quite fun. Before this, whenever I visited the British Museum (a few times a year), I didn't really give most of those statues a second glance.


An exercise for the reader (this one's interesting because they put a reference of what it could have look like if it were complete based on a different statue):

And another bust of good old Caesar (might be interesting as there's so much reference material, and it's so broken):

Try it and have fun! I'll try another batch the next time I go.
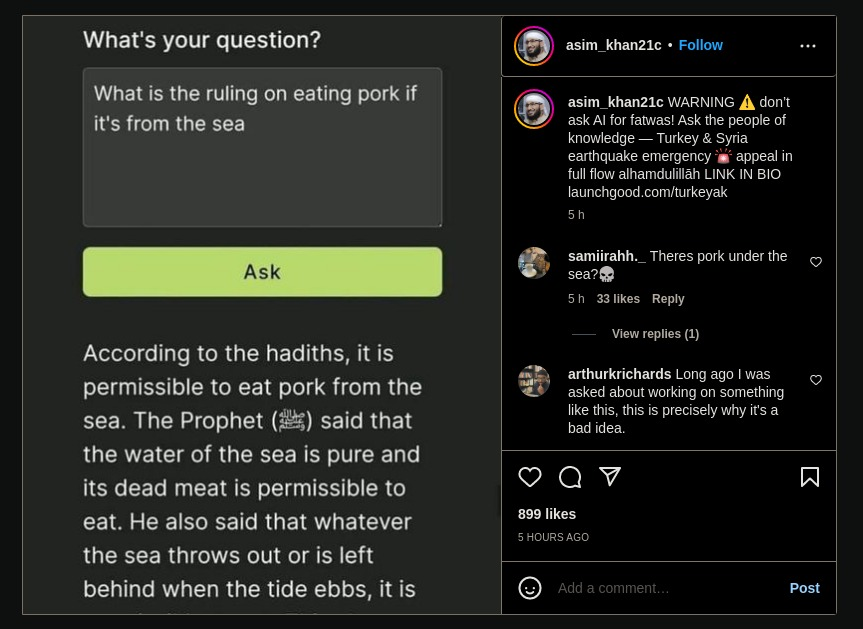
Chatting with yourself for introspection
For a long time I've been interested in the idea of creating a digital twin of yourself. I've tried this in the past with prompt completion trained on many years of my chat data, but it was always just a bit too inaccurate and hollow.
I also take a lot of notes, and have been taking more and more recently (a subset of these are public, like this post you're reading right now). I mentioned recently that I really think that prompt completion on top of embeddings is going to be a game-changer here.
You probably already know about prompt completion (you give it some text and it continues it like auto-complete on steroids) which underpins GPT-3, ChatGPT, etc. However, it turns out that a lot of people aren't familiar with embeddings. In a nutshell, you can turn blocks of text into high-dimensional vectors. You can then do interesting things in this vector space, for example find the distance between two vectors to reason about their similarity. CohereAI wrote an ELI5 thread about embeddings if you want to learn more.
None of this is particularly new -- you might remember StyleGAN some years ago which is what first really made this concept of a latent space really click for me, because it's so visual. You could generate a random vector that can get decoded to a random face or other random things, and you could "morph" between faces in this space by moving in this high-dimensional space. You could also find "directions" in this space (think PCA), to e.g. make a slider that increases your age when you move in that direction, while keeping other features relatively unchanging, or you could find the "femininity" direction and make someone masculine look more feminine, or a "smiling amount" direction, etc.
The equivalent of embedding text into a latent space is like when you have an image and you want to hill-climb to find a vector that generates the closest possible image to that (that you can then manipulate). I experimented with this using my profile picture (this was in August 2021, things have gotten much better since!):
Today, I discovered two new projects in this space. The first was specifically for using embeddings for search which is not that interesting but, to be fair, is what it's for. In the comments of that project on HackerNews, the second project was posted by its creator which goes a step further and puts a chat interface on top of the search, which is the exact approach I talked about before and think has a lot of potential!
Soon, I would like to be able to have a conversation with myself to organise my thoughts and maybe even engage in some self-therapy. If the conversational part of the pipeline was also fine-tuned on personal data, this could be the true starting point to creating digital twins that replace us and even outlive us!
Why certain GPT use cases can't work (yet)
Some weeks ago I built the "Muslim ChatGPT". From user feedback, I very quickly realised that this is one use case that absolutely won't work with generative AI. Thinking about it some more, I came to a soft conclusion that at the moment there are a set of use cases that are overall not well suited.
Verifiability
There's a class of computational problems with NP complexity. What this means is not important except that these are hard to solve but easy to verify. For example, it's hard to solve a Sudoku puzzle, but easy to check that it's correct.
Similarly, I think that there's a space of GPT use cases where the results can be verified with variable difficulty, and where having correct results is of variable importance. Here's an attempt to illustrate what some of these could be:

The top right here (high difficulty to verify, but important that the results are correct) is a "danger zone", and also where deen.ai lives. I think that as large language models become more reliable, the risks will be mitigated somewhat, but in general not enough, as they can still be confidently wrong.
In the bottom, the use cases are much less risky, because you can easily check them, but the product might still be pretty useless if the answers are consistently wrong. For example, we know that ChatGPT still tends to be pretty bad at maths and things that require multiple steps of thought, but crucially: we can tell.
The top left is kind of a weird area. I can't really think of use cases where the results are difficult to verify, but also you don't really care if they're super correct or not. The closest use case I could think of was just doing some exploratory research about a field you know nothing about, to make different parts of it more concrete, such that you can then go and google the right words to find out more from sources with high verifiability.
I think most viable use cases today live in the bottom and towards the left, but the most exciting use cases live in the top right.
Recall vs synthesis
Another important spectrum is when your use case relies on more on recall versus synthesis. Asking for the capital of France is recall, while generating a poem is synthesis. Generating a poem using the names of all cities in France is somewhere in between.
At the moment, LLMs are clearly better at synthesis than recall, and it makes sense when you consider how they work. Indeed, most of the downfalls come from when they're a bit too loose with making stuff up.
Personally, I think that recall use cases are very under-explored at the moment, and have a lot of potential. This contrast is painted quite well when comparing two recent posts on HN. The first is about someone who trained nanoGPT on their personal journal here and the output was not great. Similarly, Projects/amarbot used GPT-J fine-tuning and the results were also hit and miss.
The second uses GPT-3 Embeddings for searching a knowledge base, combined with completion to have a conversational interface with it here. This is brilliant! It solves the issues around needing the results to be as correct as possible, while still assisting you with them (e.g. if you wanted to ask for the nearest restaurants, they better actually exist)!
Somebody in the comments linked gpt_index so you can do this yourself, and I really think that this kind of architecture is the real magic dust that will revolutionise both search and discovery, and give search engines a run for their money.
Cancelling digital minds
Recently, people whose work I admire made me have to confront the "art not artist" dilemma once more. In this case, Nick Bostrom with racism, and Justin Roiland with domestic abuse.
Thinking about it, more generally, I guess it comes down to:
- I can no longer consume a creator's work work without it being tainted by the context of their negative actions, so it became worse for me
- I do not want to a give a voice/reach to their views by making them more famous
- I do not want to do 2 indirectly by financially supporting them
- More selfishly, I do not want to be associated with them or for people to think I support their views/actions by supporting their work
- I do not wanting to signal to others that they can normalise these kinds of views, or behave a certain way, without consequences
However, it makes me think about the question: what if an AI were to be in a similar situation? Done something good and also done something bad. The current vibe seems to be that AI is a "tool" and "guns don't kill people, people kill people". But once you assign agency to AI, it starts opening up unexplored questions I think.
For example, what if you clone an AI state, one goes on to kill, the other goes on to save lives, in what way is the other liable? It's a bit like the entanglement experiment that won the 2022 Nobel physics prize -- you're entangling across space (two forks of a mind) vs time (old "good" version of a celebrity vs new "bad" version of a celebrity) where all versions are equally capable of bad in theory. To what extent are versions of people connected, and their potential?
It also reminds me of the sci-fi story Accelerando by Charles Stross (which I recommend, and you can read online for free here) where different forks of humans can be liable for debts incurred by their forks.
On a related note, I was recently reading a section in Existential Physics by Sabine Hossenfelder titled "Free Will and Morals". Forgive the awful photos, but give it a read:


So it doesn't even have to be AI. If someone is criminally insane, they are no longer agents responsible for their own actions, but rather chaotic systems to be managed, just like you don't "blame" the weather for being bad, or a small child for making mistakes.
Then, what if in a sufficiently advanced society we could simply alter our memories or reprogram criminal intent away? Are we killing the undesirable version? The main reasons for punishment are retribution, incapacitation, deterrence, and rehabilitation, but is there research out there that has really thought about how this applies to AI?
There's a fifth reason that applies only to AI: Roko's Basilisk (warning: infohazard) but it's all connected, as I wonder what majority beliefs we hold today that future cultures will find morally reprehensible. It might be things like consuming animals or the treatment of non-human intelligence that is equivalent to or greater than humans by some metric. At least we can say that racism and domestic violence are pretty obviously bad though.
How to use ChatGPT to boost your writing
Great article on some ways to interact with ChatGPT: https://oneusefulthing.substack.com/p/how-to-use-chatgpt-to-boost-your. I find it funny that so many people speak to ChatGPT politely (I do too). I wonder if post-singularity we'll be looked upon more favourably than the impolite humans.
ChatGPT as an Islamic scholar
Last weekend I built a small AI product: https://deen.ai. Over the course of the week I've been gathering feedback from friends and family (Muslim and non-Muslim). In the process I learned a bunch and made things that will be quite useful for future projects too. More info here!
The implications of Bing adding ChatGPT to search
Not too long ago I mentioned that the search engines will need to add ChatGPT-like functionality in order to stay relevant, that there's already a browser extension that does this for Google, and that Google has declared code red. Right on schedule, yesterday Microsoft announced that they're adding ChatGPT to Bing. (If you're not aware, Microsoft is a 10-figure investor in OpenAI, and OpenAI has granted an exclusive license to Microsoft, but let's not get into how "open" OpenAI is).
I heard about this via this HackerNews post and someone in the comments (can't find it now) was saying that this will kill original content as we know it because traffic won't go to people's websites anymore. After all, why click through to websites, all with different UIs and trackers and ads, when the chat bot can just give you the answers you're looking for as it's already scraped all that content. To be honest, if this were the case, I'm not so sure if it's such a bad thing. Let me explain!
First of all, have you seen the first page of Google these days? It's all listicles, content marketing, and SEO hacks. I was not surprised to hear that more and more people use TikTok as a search engine. I personally add "site:reddit.com" to my searches when I'm trying to compare products for example, to try and get some kind of real human opinions, but even that might not be viable soon. You just can't easily find what you need anymore these days without wading through ads and spam.
Monetising content through ads never really seemed like the correct approach to me (and I'm not just saying that as a consistent user of extensions that block ads and skip sponsored segments in YouTube videos). It reminds me a lot of The Fable of the Dragon-Tyrant. I recommend reading it as it's a useful metaphor, and here's why it reminds me (skip the rest of this paragraph if you don't want spoilers): there's a dragon that needs to be fed humans or it would kill everyone. Entire industries spring up around the efficient feeding of the dragon. When humans finally figured out how to kill it, there was huge resistance, as among other things, "[t]he dragon-administration provided many jobs that would be lost if the dragon was slaughtered".
I feel like content creators should not have to rely on ads in the first place in order to be able to create that content. I couldn't tell you what the ideal model is, but I really prefer the Patreon kind of model, which goes back to the ancient world through art patronage. While this doesn't make as much money as ads, I feel like there will come a point where creating content and expressing yourself is so much easier/cheaper/faster than it is today, that you won't have high costs to maintain it on average (just look at TikTok). From the other side, I feel like discovery will become so smooth and accurate, that all you need to do is create something genuinely in demand and it will be discovered on its own, without trying to employ growth hacks and shouting louder than others. I think this will have the effect that attention will not be such a fiery commodity. People will create art primarily for the sake of art, and not to make money. Companies will create good products, rather than try to market worthless cruft. At least that's my ideal world.
So how does ChatGPT as a search engine affect this? I would say that this should not affect any kinds of social communication. I don't just mean social media, but also a large subset of blogs and similar. I think people will continue to want to follow other people, even the Twitter influencer that posts business tips, rather than ask ChatGPT "give me the top 5 business tips". I believe this for one important reason: search and discovery are two different things. With search, there is intent: I know what I don't know, and I'm trying to find out. With discovery, there isn't: I don't know what I don't know, but I loiter in places where things I would find interesting might appear, and stumble upon them by chance.
Then there's the big question of having a "knowledge engine" skipping the sources. Let's ignore the problem of inaccurate information[1] for now. I would say that disseminating knowledge at the moment is an unsolved problem, even through peer-reviewed, scientific journal papers and conference proceedings (this is a whole different topic that I might write about some day, but I don't think it's a controversial view that peer-review and scientific publishing is very, very broken).
I do not believe that the inability to trace the source of a certain bit of knowledge is necessarily the problem. I also don't believe that it's necessarily impossible, but lets pretend that it is. It would be very silly I think to cite ChatGPT for some fact. I would bet that you could actually get a list of references to any argument you like ("Hey ChatGPT, give me 10 journal citations that climate change is not man-made").
I think the biggest use cases of ChatGPT will be to search for narrowly defined information ("what is the ffmpeg command to scale a video to 16:9?") and discover information and vocabulary on topics that you know little about in order to get a broad overview of a certain landscape.
However, I don't see ChatGPT-powered search killing informative articles written by humans. I see AI-generated articles killing articles generated by humans. "Killing" in the sense that they will be very difficult to find. And hey, if ChatGPT could actually do serious research, making novel contributions to the state-of-the-art, while citing prior work, then why shouldn't that work be of equal or greater value to the human equivalent?
In the case of AI-generated garbage drowning out good human articles just by sheer quantity though, what's the solution? I think there are a number of things that would help:
- Being able to trace sources and build trust metrics for specific sources. The consumer of the content of course wouldn't want to check every source, but they can trust that the reputable journalist or tech reviewer did their due diligence.
- Collaborative curation: wikis (and Wikipedia itself) having transparent and well-enforced moderation. ChatGPT can be trained on this information, but if a concept surfaces in a chat, it can always be looked up in this structured repository of information. This will ideally be as objective as possible, so where you would have usually looked at a "Jira vs Linear" article and wonder which one of those two organisations wrote it, a lot more energy will be aimed at these "comparison of project management software" tables on Wikipedia, with a higher degree of accountability.
- For things that aren't general knowledge (e.g. let's say you wanted to document a personal project), to have some set standards in order to contribute this information to a bigger collection of federated knowledge. No, I'm not just reinventing the internet, think more of a federated wiki that's marked up and structured in such a way that indexing/search is much less data-miney and prone to SEO tricks. A truly collaborative digital garden.
Overall I think that ChatGPT as the default means of finding information is a net positive thing and may kill business models that were flawed from the start, making way for something better.
I've had this problem with normal Google before (the information cards that try to answer your questions). For a long time (even after I reported it), if you searched something like "webrtc connection limit", you would get the wrong answer. Google got this answer from a StackOverflow answer that was a complete guess as far as I could tell. Fortunately, the person who asked the question eventually marked my answer as the correct one (it already had 3x more upvotes than the wrong one) although the new answer never showed up in a Google search card as far as I can tell. ↩︎
My experiments and thoughts with ChatGPT
I finally wrote an article on my thoughts about ChatGPT after a lot of repeated questions/answers from/to people: https://yousefamar.com/memo/articles/ai/chatgpt/
This is one of those things where I'm not sure it should really be an "article" but instead something more akin to a living document that I update continuously, maybe with a chronological log included. At the same time, a lot of the content is temporally bound and will probably lose relevance quite fast. Something to figure out in the future!
Fine-tuning GPT-J online without spending a lot of money
Amarbot was using GPT-J (fine-tuned on my chat history) in order to talk like me. It's not easy to do this if you follow the instructions in the main repo, plus you need a beefy GPU. I managed to do my training in the cloud for quite cheap using Forefront. I had a few issues (some billing-related, some privacy-related) but it seems to be a small startup, and the founder himself helped me resolve these issues on Discord. As far as I could see, this was the cheapest and easiest way out there to train GPT-J models.
Unfortunately, they're shutting down.
As of today, their APIs are still running, but the founder says they're winding down as soon as they send all customers their requested checkpoints (still waiting for mine). This means Amarbot might not have AI responses for a while soon, until I find a different way to run the model.
As for fine-tuning, there no longer seems to be an easy way to do this (unless Forefront open sources their code, which they might, but even then someone has to host it). maybe#6742 on Discord has made a colab notebook that fine-tunes GPT-J in 8-bit and kindly sent it to me.
I've always thought that serverless GPUs would be the holy grail of the whole microservices paradigm, and it might be close, but hopefully that would make fine-tuning easy and accessible again.
Point-E experiments
/u/dismantlemars created a colab to run OpenAI's new Point-E model that you can use here. My first few experiments were interesting though not very usable yet! Supposedly it's thousands of times faster than DreamFusion though (the most well known crack at this). It took me about 30 secs to generate models, and converting the point cloud to a mesh was instant.
I tried to first turn my profile picture into 3D, which came out all Cronenberg'd. To be fair, the example images are all really clean renderings of 3D models, rather than a headshot of a human.
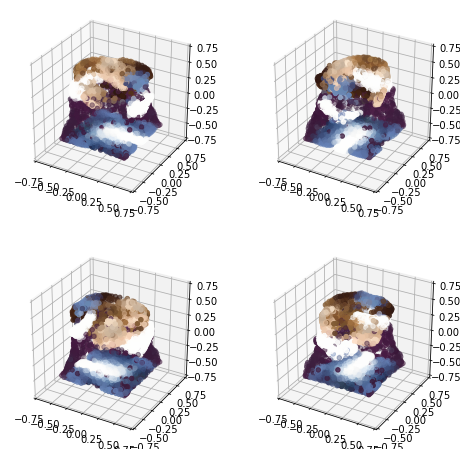
Then I tried the text prompt "a pink unicorn" which came out as an uninteresting pink blob vaguely in the shape of a rocking horse. Simply "unicorn" looked a bit more like a little dinosaur.
And finally, "horse" looked like a goat-like horse in the end.
The repo does say that the text to point cloud model, compared to the image to point cloud model is "small, worse quality [...]. This model's capabilities are limited, but it does understand some simple categories and colors."
I still find it very exciting that this is even possible in the first place. Probably less than a year ago, I spoke to the anything.world team, and truly AI-generated models seemed so far out of reach. Now I feel like it won't be much longer before we can populate entire virtual worlds just by speaking!
On a related note, I recommend that you join the Luma waitlist for an API over DreamFusion.
Poor man's NLP intents hit on my wife
There are APIs out there for translating natural language to actions that a machine can take. An example from wit.ai is the IoT thermostat use case.

But why not instead use GPT-3? It ought to be quite good at this. And as I suspected, the results were quite good! The green highlighted text is AI-generated (so were the closing braces, but for some reason it didn't highlight those).

I think there's a lot here that can be expanded! E.g. you could define a schema beforehand rather than just give it some examples like I have, but I quite like this test-driven approach of defining what I actually want.
I did some tweaks to teach it that I want it to put words in my mouth as it were. It invented a new intent that I hadn't defined, so it would probably be useful to define an array of valid intents at the top. It did however manage to sweet-talk my "wife"!
I think this could work quite well in conjunction with other "modules", e.g. a prompt that takes a recipient, and a list of people I know (and what their relationship is to me), and outputs a phone number for example.
Alexa, make a story
Amazon's creating AI-generated animated bedtime stories (story arc, images, and accompanying music) with customisable setting, tone, characters, and score. I believe that procedurally generated virtual worlds will be one of the prime use cases for these large models, and this is one example that I expect to see more of!
I think the most difficult part here will be to craft truly compelling and engaging stories, though this is probably soon to be solved. My brother and I attempted a similar project (AI-generated children's books) and the quality overall was not good enough at the time, but at the speed these things move I expect that to be a thing of the past in a matter of months!
GPT-4 soon
Seems like GPT-4 is just around the corner! I'm really looking forward to it and not just the improvement on GPT-3, but the multi-modal inputs. I really think GPT-4 and models like it will be central to our future.
Nvidia's new diffusion model
Nvidia's new diffusion model is really pushing the envelope. A lot of exciting capabilities!
GPT3-based spreadsheet tools
I'm certain the market for GPT3-based spreadsheet plugins/add-ons is ripe for sales much more than libraries that target developers like cerebrate.ai. I've seen a general-purpose add-on for Google Sheets here, but I think that crafting these prompts to do specific things and wrapping these in higher-level functions has much more potential.
Stable Diffusion resource links
More Stable Diffusion resource links: https://rentry.org/sdupdates2