Log #projects
This page is a feed of all my #projects posts in reverse chronological order. It only includes posts with a timestamp (so e.g. not named "digital garden" pages or living documents). You can subscribe to this feed in your favourite feed reader through the icon above.
Everything here was written by me and me alone. Writing is a big part of my thinking process and these posts get published out of my internal writing. It's all organic; 0% AI assistance. Sometimes I will write about my experience using AI tools (e.g. to create a song or such) and in that case it will be very obvious in what I write that the attached media is made by AI.
![]()
Amar Memoranda > Log (projects)
 Yousef Amar
Yousef Amar
Ant feeder
Holidays are always tricky when you're responsible for plants/animals. Jinn (cat) is generally fine, but the cat sitter can't really take care of the aquarium or the ant farm.
To make it a bit easier to feed the ants, we decided to 3D print a better setup. In this post I'll explain the process, as there's a lot of experimentation before I landed on the final product. It started with a sketch I was given of the general idea. Here's the main part:
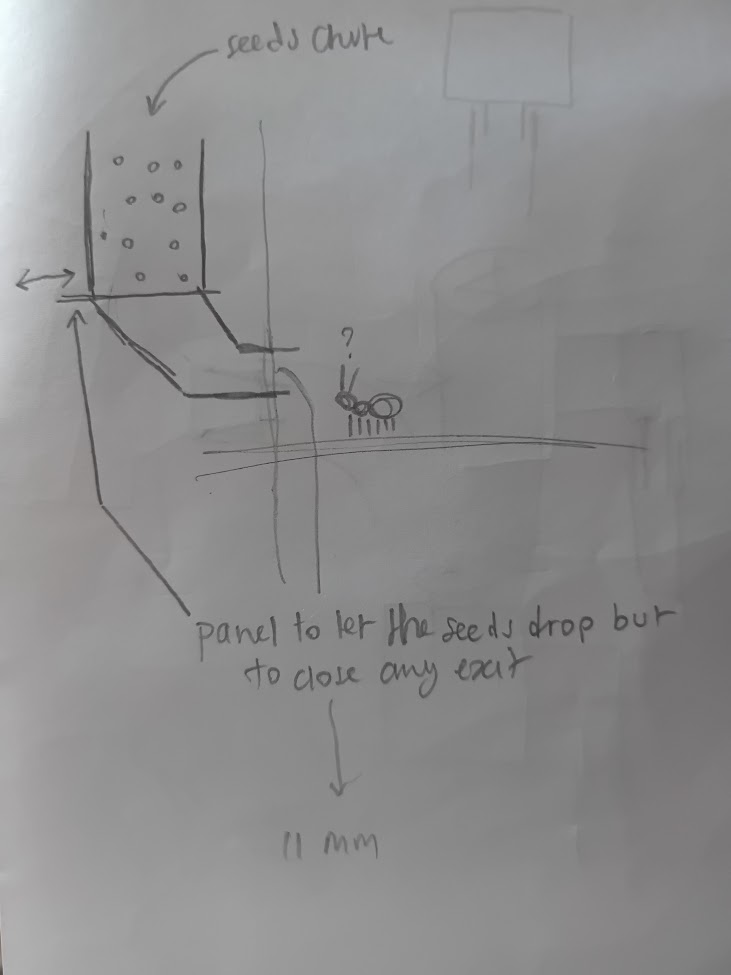
We also already had an acrylic container meant for this sort of thing. We'd connect this to the remaining containers via tubes and they can use this space for foraging food. I had just gotten new calipers as well with very high accuracy, so I measured the different parts of the container and wrote them down as well. The container also came with some rigid and flexible tubing.
So the first thing I did is look for any prior art of something that looks like a one-way valve. I knew that geometrically it's not possible to print something static that the ants can't climb out of, and previous experiments with Fluon coating weren't really successful. So there had to be moving parts, and I eventually came across this very neat coffee dispenser.
One cool thing about this is that the reservoir attachment just uses standard bottle cap threading, so already I can just reuse an old bottle for the top bit rather than wasting so much material. This made me think I could use the rotary valve part as-is, and simply adjust the radius of the outlet hole of the coffee dispenser to match the opening on the side of the container.

I figured I'd need something to actually connect it to the hole on the side as well, so I extruded and subdivided the opening.

Then I used modifiers to taper the tube a bit as I actually needed the outside radius to plug into the 11mm hole. Ignore that the units are in meters here (Blender default), I never bothered to adjust them to mm so I just append another m in my head!
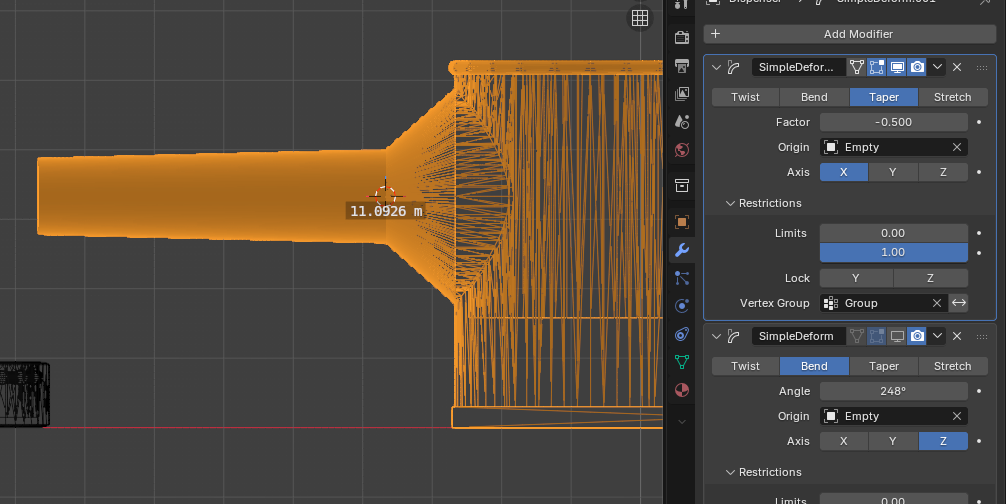
I used a second modifier to bend the tube downward. Yes I know what this looks like.
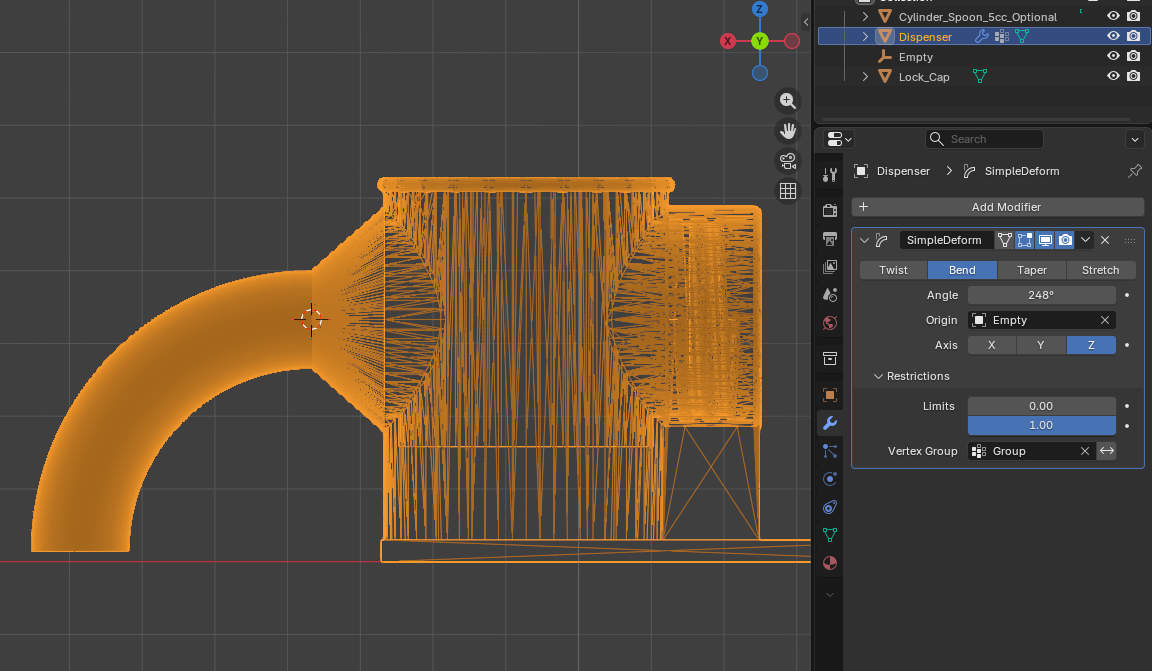
Then I realised it actually needs to extend into the acrylic container, so I added a little extra, with more tapering so it's a friction fit.
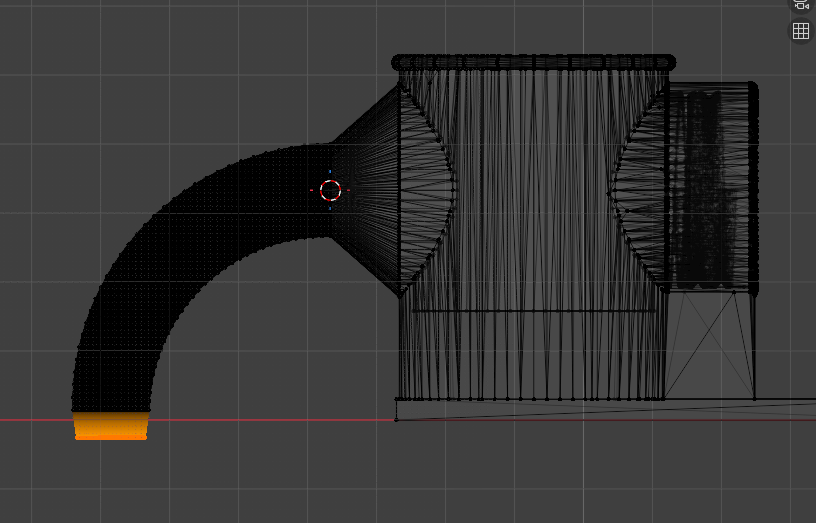
But the whole thing started to feel a bit stupid. It's going to be hard to print this because now I'm below the build plate and would either need to think of a way to add supports in good places or chop the model up and find out how to attach the parts later. Not just that but I know that my printer will struggle on that tube. Plus now I have all these extra tolerances to have to get right!

I ended up deciding to actually just remove the extrusion entirely and instead try to use the tubing that came with the container, if I was going to have to attach something anyway. So I printed the first version, and stuck it on the side with a bit of cut tubing attached, and it looked fine at a glance.
 BUT, it was sort of janky and seeds got stuck in the gap between the print and the tube, as well as on the lip of the tube itself. Especially the bigger seeds would create congestion too. Here's an attempt at an illustration of the problem!
BUT, it was sort of janky and seeds got stuck in the gap between the print and the tube, as well as on the lip of the tube itself. Especially the bigger seeds would create congestion too. Here's an attempt at an illustration of the problem!

Maybe if the clear tube was connected from the outside, rather than inside? I didn't want to wait for the whole thing to print again, so I tested this idea with a little funnel instead.

I glued this to the opening for now and gave it a try.

Verdict: even worse. This was a dead end; the radius was just too small for these seeds and everything was getting clogged up every time!

The whole apparatus also just wasn't very stable and there were too many failure points, e.g. the tube slipping off, the whole thing moving as you turn the dial, etc. We considered having the hopper drop into a tray, but really that was just shifting the problem around, as then you'd have to have a horizontal pipe into basically a second container. It's also likely the ants will clog that pipe too with seeds and be crawling in the pipes the whole time as seeds come down. So it was back to the drawing board...
I thought, if I really want the seeds to come from on top, and to have a lot of room for them, why not just replace the lid? This was more work, but might as well do it right. I started by designing a lid from scratch, which was relatively straightforward (a cube and the bevel tool). I wanted to get the size right first, so I made a test print of only the rim (carved the inside out) so that it's fast to print. On my first try, the radius of the corners was too low so it didn't close properly. In this photo, I'm holding my print back-to-back with the original lid.

I tried modifying the profile shape as I thought I had measured the radius correctly, but it didn't look right. I thought it really was that the radius was too small, so I eyeballed it a bit and made it bigger. My second try did indeed fit much better, and the radius was probably exactly right now.

The only issue was that the fit was ever so slightly loose. I wanted it pretty tight so that the ants don't get into the gaps and things don't wobble. I didn't feel like I needed to do another test print, so I simply scaled the whole thing up by a tiny amount so it would fit a bit tighter (spoiler: it ended up fitting perfectly).
The final step was to design the actual lid with the built-in hopper. I took the coffee dispenser hopper and sliced some parts off of it to have just the bit I need. There were holes, but those were easily filled by adding some edges and the fill tool. I also added some secret "engraved" text on the back, since we no longer have that wall-panel part. I made the seeds fall straight down with no "funnel" shape as that was no longer needed. It would just rain seeds.

Et voilà! I'm very pleased with how it turned out. It feels like it was genuinely built for this container and is extremely stable and smooth. To be fair, there was a bit of fraying at the overhang-y bits, but those were easily sanded away. I didn't want to have supports on the inside so some of the angles were a bit of a stretch now that the whole thing was rotated 90° compared to the original. But it worked!
In the process I also managed to fix my printer as the nozzle was not very clean and often turned prints into spaghetti. As I was cleaning it, I managed to clog the gears on the inside by pushing molten plastic back into it, so I had to dismantle the whole thing to clean that. Since then, it's been working perfectly. Super pleased of how it came out! Here are the ants enjoying their new environment. The white stuff is Fluon (though it doesn't really do anything).

Sowing time
It's that time of the year! And now that I have a conservatory, I can try to actually grow the veggies that I've failed to grow in the past. These are the main ones, though I have strawberry seeds too.

I also took the opportunity to grow Jinn more cat grass to chew on as her old one is out. The stuff grows really fast though and at any time of the year. I put it in my little shelf thingy along with the housewarming Monstera, and the flowers I got for my birthday.


Too soon for the cucumbers, but hopefully this time we'll have more success! Stay tuned for watering contraptions!
Everything Al does
Last time, I wrote about RISC-like tool use for my agent Al. As I'm rebuilding Al from scratch, I've been writing down everything he does so far (albeit not reliably), and everything I need him to be able to do. Everything in the lists below is realistic. For the most part, all he needs are a webhook endpoint and these CLI tools:
- Basic file tools (
cat,grep,find, etc) curlfor APIs and fetching URLsgogto access Google appsrr(roadrunner) to access the Beeper MCP- Obsidian CLI to access PKM (not critical given the first point)
That's it! I'll add more over time I'm sure, but this is already a lot.
For now, I'm leaving out smart-home related things, as the tools for that are a bit too complicated, but you can imagine e.g. Al turns the TV on, turns the lights low, and queues up a movie after we decide on one from the movies list. For now, he only needs to do relatively few things with these tools, some of which are not even that critical. Let's expand a bit:
- The ability to communicate
- Send/receive WhatsApp messages
- Own phone number
- Send/receive emails
- Own email inbox with hooks for incoming email
- Send/receive Slack messages
- Own Slack app
- Send/receive voice notes
- Own OpenAI key
- Make phone calls
- Own Twilio key and number -- I tried other providers as I hate Twilio, but unfortunately Twilio is the best for this right now. Might use something else in the future.
- Send/receive WhatsApp messages
- The ability to schedule tasks for the future
- Own calendar to schedule events that trigger hooks
- A place to take notes
- Own folder in my Obsidian vault (symlinked out)
- Ability to store and modify own files
- A place to log mistakes (via Obsidian CLI)
- Own self-improvement Kanban (via Obsidian CLI)
- The ability to check RSS feeds (cURL)
- https://kill-the-newsletter.com/ to turn newsletters into feeds
- The ability to keep tabs on me
- The ability to monitor my own emails and Drive files (via gog CLI)
- And messages (Beeper MCP via roadrunner CLI)
- A way to check my GPS coordinates (and orientation?) on demand (via OwnTracks API)
- The ability to gather information from the internet
- Fetch arbitrary URLs
- Access to Google Maps API
- Ability to modify some of my own files (via Obsidian CLI)
So that's well and all, but what would it do with all those powers? These are relatively few powers, but you'd be surprised at how that's enough to seriously change how you operate. I can't wait for my Pebble Index to arrive as I'll be issuing commands via that primarily.
Here's a full breakdown of my use cases so far, organised into general categories.
Self-improvement
Al needs to be able to improve himself by maintaining and modifying his prompts and code. Al does not modify these directly, but by making suggestions.
- Watch for OpenClaw updates or use cases that may be interesting and proactively make feature suggestions to own project if it may be useful
- Regularly review own chat log and log mistakes
- Regularly look at list of mistakes, brainstorm and research ways to address, create improvement tasks
- Create new workflow files to learn new abilities over time after I've shown how it's done the first time
Helping with work
Al needs to be able to help with my startup Artanis, and in some cases communicate with my colleagues over Slack or whatever other medium.
- Maintain notes on Artanis in memory/artanis/
- Keep tabs on our Monthly Update emails (there's an RSS feed)
- Keep tabs on all relevant Google Docs/Sheets
- Keep tabs on our calendars and Slack (especially the #planning channel)
- Keep tabs on our Linear workspace
- Complete specific workflows
- Create Gmail forwarding rules for invoice forwarding
- Help me track down missing invoices for bookeeping, including asking my team
- Schedule call review slots in my calendar when Sam sends a call recording
- Turn long written agendas (e.g. offsite schedule, or an event) into calendar events in my calendar
- Modify my working location on my work calendar so colleagues can know if I'm WFH or WFO or somewhere else on any given day
- The morning of when a Team Lunch is scheduled, sort out the logistics
- Ask my team what they feel like having for lunch
- If external guests are joining (it will say on the calendar event), ask them too
- Find out if we're eating out or getting takeaway
- If they suggest a cuisine rather than a restaurant, find an appropriate restaurant
- Give the option between a past place (so remember what we eat) and a new place when found
- If takeaway, find based on delivery time and if listed or not on either Uber Eats or Deliveroo
- If eating out, find based on walking distance from office and rating
- If takeaway, initiate a group order (both Uber Eats and Deliveroo support this) and send the link. Only add things to the order when explicitly asked. When everyone is done adding, check out.
- If eating out, make the booking for the time on the calendar event
Filter through the noise
Al should act as a first line of defence against digital comms noise.
- Notify me of any important emails or messages when they come in
- Reply to emails on my behalf when asked
- Unsubscribe from emails on my behalf when asked
- Where there's no way to unsubscribe, this includes replying with a request to be taken off their list, from the same email address
- Archive emails on my behalf when asked
Help me stay on top of things
Al should keep me up to date on what he's doing, what the world is doing, and what I should be doing.
- Send daily morning reports
- Summary of schedule for the day (5 calendars)
- Any emails/messages that I haven't responded to in longer than 2 working days
- HackerNews front page picks, with links, based on my interests
- Any open threads that might need my attention from our projects
- Summary of overnight work or research
- Summary of any conversations with others
- Bookmarks of the day, which I can decide to keep or delete
- Send weekly report (Monday report is special)
- In addition to the above, also check all DNS and server statuses
- If ISP have rotated my IP, run workflow to update IPs
- If a server is down, flag immediately
- In addition to the above, also check all DNS and server statuses
- When I flag a grocery list item that needs restocking, add it to the calendar event for ordering groceries
- Initiate weekly Sainsbury's grocery order every Sunday
- Check if browser use is still authenticated (no API)
- Check what time the delivery should be scheduled for in the calendar
- Start an order, and if the time slot is not available, look for alternate times in the calendar, then ask me if it's ok to move it. Once we've found a time, make sure the calendar event is at the right time and book a delivery slot
- Never order new items, only items from past orders or in Favourites. Follow the workflow file to understand how to use this UI
- Add all the regular items to the order and the additional ones from the calendar event
- Get it over the minimum charge and check out the order
- Send a message to notify for amendments before the cut-off date
Communicate with others
Al should take some comms weight off me by responding to my contacts when they message directly.
- Gatekeep people asking to meet
- Find out what the purpose/agenda is
- Short-circuit / reject if appropriate
- Determine if it can be done in messages instead and ping me
- Help them find a virtual/physical time/place to meet if appropriate based on my availability and preferences
- Follow up with them when needed when they haven't responded
- Figure out information from them on my behalf when they're being too obtuse
- Allow my mother to find my general location in an emergency
- Immediately inform me of new conversations and odd requests
- Remember things about my contacts and practice information hygiene by only loading the person's file that is in conversation
Pay others
Al should pay others on my behalf, for personal payments. As this is a sensitive action, these use cases are not a subset of examples, but the total set of what Al can do here.
- Pay my driving instructor Jameel £67.50 the morning I have a driving lesson scheduled and text him to say I paid and when I'll meet him
- On receiving an email from Kate on scheduling changes, modify the standing order, then respond to her confirming the exact changed that was made and when to expect payments.
- As this doesn't work via the Monzo API, Al should also just initiate the payments manually on the due dates in received invoices and pay exactly £45
- As Al is limited to only paying those exact two amounts to those exact recipients and a limited frequency, Al must notify me immediately if a payment fails, why, and suggest what needs to change (e.g. a limit increase)
Help manage my schedule
Al should help scheduling and rescheduling events in my calendar and use external tools to help.
- Book my gym classes the moment they become available via provided URLs. Right now, this means checking every Wednesday morning and booking classes for 2 weeks into the future. Where I have clashes, ask me what to do
- Schedule gardening tasks into my calendar based on seasons and inventory
- Put travel itineraries in my calendar with the correct timezones
- Help me reach physical locations that I need to be at
- Finding e.g. the nearest pharmacy
- Sending directions straight to my phone
- Informing me of ETAs
- Informing others of ETAs
Help manage my personal knowledge base
I have a lot of notes, journals, etc (this blog is part of it). Al should not ever edit anything I've written, or write anything on my behalf, however can help me a lot with organising these.
- Enrich and append items to my lists
- Reading list
- Video games list
- 2x movie lists
- Writing ideas
- Blog drafts
- Dream logs
- Stray thoughts
- Tagged bookmarks (one file per bookmark, unlike other lists)
- Help me work through those lists by
- Making suggestion when I'm looking for something to read or watch, and updating the columns in those lists accordingly. When appropriate, asking for a review from me to add that to the list as well
- Providing writing prompts, reminding me to finish a blog, or finding connections between thoughts/notes
- Surface old notes for me to decide if they should be kept, pruned, or recombined
- Surface old files that may be interesting to revisit or write about
Help me research, learn, grow
Al should gather information off of the internet and present it to me in an appropriate way depending on if it's for research to answer specific questions, or to learn new concepts.
- Analyse codebases
- Clone an open source codebase into ~/src
- Launch a Claude Code session to analyse stack, architecture etc
- Produce a short report to be shared with me
- If the codebase is too large, then Claude code should not clone and simply browse the remote repo (e.g. on GitHub)
- Wait until I have no more questions before deleting the repo
- Help me plan tasks or software projects
- Research libraries or tools for me
- Launch a Claude Code session to plan a software project (architecture, functional decomposition, etc)
- Produce Kanbans in the PKM
- Help me learn new things
- Research a topic online and gather learning materials
- Organise those materials into a course with scheduled blocks
- Tutor me through those materials. Potentially create engaging podcasts timed to fit within e.g. train journeys
- Act as a therapist and coach
- Analyse my notes and journals at a regular cadence, comparing them to my growth goals and progress
- In timed blocks, act as a therapist to dissect that information, and a coach to help me towards my goals
More to come, stay tuned!
Building a better OpenClaw
I've completely changed my digital right hand to use OpenClaw for most of February, and while it was quite fun (and sometimes dangerous -- ask my colleagues about the Monzo API), I quickly found the cracks. These were not related to security as people might think, but rather reliability. I started logging mistakes not long after the switch in a MISTAKES.md, and the vast majority are related to the agent ignoring my instructions. This was usually caused by spotty memory (which is exacerbated by the agent forgetting to remember things as instructed) as well as some deeper architectural issues.
Overall, I think this is mostly fixable, but I would have to just rebuild it from scratch, in a much simpler and more principled way, based on what I've learned. I'm a big believer in the future where single-user apps will proliferate, so I think it's more important to align on the right principles than implementation-specific things like what integrations you use.
1: Text is king
I've written about this before, so I'll summarise with the Unix Philosophy:
Write programs that do one thing and do it well. Write programs to work together. Write programs that handle text streams, because that is a universal interface.
An LLM's whole thing is text, so we should lean heavily into that.
2: Code is text
Therefore code is king too. Any abstraction over taking actions is unnecessary, beside the ability to use a CLI. General-purpose agents work better with a reduced instruction set. We don't need plugins and tools and MCPs etc (although it's great that the MCP hype is pushing people to make their products machine-accessible).
An agent with a CLI can use cURL to talk to your REST API. It can learn new CLI tools faster than you can, through a man page or --help. It can write scripts to solve hard tasks. Code is already a problem-solving language, and there was a hell of a lot of training data, so agents are really good at this. They can also write tests and fix bugs iteratively. Don't kneecap it by inventing some new protocol because you think you're making things better.
3: Use human products
OpenClaw did one thing very well, which is to have human chat apps as first-class integrations. You should not invent yet another web chat UI -- take the conversation to where humans already are and where they talk to other humans. Yes, WhatsApp doesn't have text streaming and markdown table rendering etc, but I suspect over time these spaces will be more agent-friendly.
However, OpenClaw did not go all the way. You should not use cron jobs for scheduling, you should use a calendar. You should not use a markdown file in some internal workspace directory to plan, you should use a Kanban board.
"But Yousef", you lament, "didn't you just say they should live in the CLI?". Yes, but they should use human products from the CLI. The products should be the same, but not necessarily the interfaces, even if over time interfaces are shifting towards conversation. They can be different for humans and agents. Agents can interact with these products via their API, not browser use. Some examples:
- My OpenClaw instance has its own Google Calendar, with software that fires hooks when a new event starts. I have access to this calendar too for visibility, but I can also easily modify it.
- I can see all the OpenClaw workspace files as they're symlinked out of my Obsidian vault. This means I get markdown rendering/editing as well as backups for free. I use an Obsidian plugin too that can render markdown files in a certain format as a Kanban board, which OpenClaw barely needed any information to know how to use.
- The future of building software is not in a Claude Code terminal, but in your project management software. I use Linear, which already supports assigning tickets to agents. You should talk to these agents in the Linear comments, like you would a human engineer, and you can review their work in PRs on GitHub, again just like you would a human engineer. Linear has an MCP server, but it's not needed, as my agents know the
linearisCLI tool. They create new tickets for me through that all the time.
4: Policy beats memory
An agent's memory should just be the chat log. By all means store that, but you should never need to check it unless its relevant to the task at hand, just like a human will only search their chat history to get something, but it's a terrible way to stay organised or remember things. Chat should be ephemeral by nature.
Agents should act on anything important immediately and not rely on chat. This means remembering a new workflow for example. Agents should have their own permanent notes, just like a human may have a personal knowledge base. Just like humans, quality beats quantity, so the Digital Garden should remain curated. It's not a journal or a blog.
Both the agent and the human should maintain policy together. Policy can exist in many forms, but for a general-purpose agent, it's good to organise these so that they're pulled on demand. An example of this is Claude's Agent Skills where each skill contains detailed descriptions and other resources for a specialised workflow.
The crucial part is that the main prompt should inform the agent where these skills live, how to unpack one, and most importantly, under which conditions to unpack one. The goal is to solve scaling a sprawl of skills (say that 10 times fast). A single skill may be as thin as "here's a new command line tool that does X", it just doesn't need to be in context all the time.
Full disclosure: at my startup this is the exact problem we're solving. Getting policy (e.g. some niche knowledge about your domain) out of your head and into your agent, and keeping this internally consistent without ambiguity or contradiction. Every mistake that your agent makes is an opportunity for policy refinement.
There are other problems that need to be solved, e.g. access control: can you guardrail your agents in a guaranteed way (software) that is granular/flexible enough but still easy to use and doesn't ask you for a million permissions? These are all subsets of strong policy.
I'm starting to believe that anything additional to this (e.g. creating "planning modes" or orchestrator agents, or allowing the agent to spin up sub-agents, or even just compacting chat history instead of truncating) just gets in the way and often backfires. I suspect all these attempts at juicing agents will just become less and less useful over time as the models get better at a more foundational level.
Sentinel is now Al
It's been a while since I've written about the bot formerly known as Sentinel. It has continued to evolve, with the most significant change being a switch from Node-RED to n8n. Over the past couple weeks, there has been an even more fundamental shift however: a brain transplant. One that has prompted me to rename Sentinel to Al (that's Al with an L).
The fact that it looks like AI with an i is a coincidence -- it comes from the Arabic word for "machine", and I also decided to start referring to Al as "him" rather than "it" for convenience. Rather than an "assistant", I position Al as an digital extension of myself and the orchestrator of my exocortex[1], while I'm his meatspace extension.
The big shift is that I've jumped on the OpenClaw bandwagon! People have mixed views on OpenClaw, but I can say that overall I find it quite exciting. I, like many people, have fully embraced the use of Claude Code, and have been trying to retrofit it to do more than simply build software. OpenClaw looks like the beginning of an ecosystem that allows us all to do just that without all rolling our own disparate versions.
OpenClaw embraces a concept that I find so fundamental as to be laughably obvious: the interface to chat bots should be existing chat apps. This is why Sentinel and Amarbot had their own phone numbers. While I have used Happy (and later HAPI, self-hosted on https://hapi.amar.io) in order to access my Claude Code sessions from mobile without the insanity of a mobile terminal, even those felt like anti-patterns. You can read more on why I think this is in my post on why we should interact with agents using the same tools we use for humans, as well as my post on agent chat interfaces in general.
For the record, I think these mode of interaction are inevitable, not a preference. While AI will interface with things via APIs, raw text, or whatever else, the bridge between AI and human will be the same tools as between human and human. This is also why I think the UIs purporting to be the "next phase" of agentic work where you manage parallel agents (opencode, conductor, etc) are the wrong path. The people who got this absolutely bang-on correct are Linear, with Linear for Agents, and I don't just say that because I love Linear (I do). I should assign tickets to agents the same way I would a human, and have discussions with them on Linear or Slack, the same way I would a human.
So, that brings me to what I think OpenClaw is currently bad at. First, cron should not be used as a trigger. Calendars should. Duh. One of the first things I did was give Al his own calendar and set up appropriate hooks. We need to be using the same tools, and I never use cron. This gives me a lot of visibility over what's going on that is much more natural, and I can move around and modify these events in the way they're supposed to be: through a calendar UI, not through natural language conversation.
On the topic of visibility, workspace files need to be easily viewable and editable. By this I mean all the various markdown files that form the agent's memory and instructions. While I may not need to edit these and Al can do that on his own, if we do want to explicitly edit, it should be easy to do so, and natural language conversation is not the way (this is not code)! To solve this, I've put Al's brain into my Obsidian vault (yes, the very vault from which these posts are published!) and symlinked it into the actual OpenClaw directory. So now I have can browse these files with a markdown editor heavily optimised for me! An added bonus of this is that Al's brain is now replicated across all my devices and backups for free, using Syncthing which already covers my vault.
It's still early days, so I'm still finding out the best ways to collaborate with Al. There are still a lot of issues, mainly related to Al forgetting things, that I'm working through, but it's been great! He can do everything that Sentinel already could, including talk to other people independently and update my lists. The timing is perfect, as I pre-ordered a Pebble Index 01[2] and this will very likely be the primary way that I communicate with Al in the future when it comes to those one-way commands. For two-way, I still use my Even G1 smart glasses, but I suspect that I may go audio-only in the future (i.e. my Shokz OpenComm2 as I don't like having stuff in my ears).
I've scheduled some sessions with Al where we try and push each other to grow. For him, this means new capabilities and access to new things and various improvements. For me, this means learning about topics that Al has broken down into a guided course or literal coaching. I'll post more as I go along! In the meantime, you can also chat with him.
This is a term I took from Charles Stross' novel Accelerando which refers to the cloud of agents that support a human, and I was delighted to see the lobster theme in OpenClaw. I don't know if they were inspired by Accelerando, but sentient lobsters play a role! ↩︎
This device is controversial in its own right because of the battery that cannot be charged/replaced. When I watched the founder's video though, I was sold, as everything he said resonated. I suspect I won't use it for longer than 2 years anyway as I'll have probably moved on to something else by then. Incidentally, the founder is also the founder of Beeper, which I use for messaging, and which Al has access to through its built-in MCP server. ↩︎
SSH client on my G1 smart glasses
This is a demo of how I run an SSH client on my Even Realities G1 smart glasses, as multiple people have asked me. It's a weird look when you're sitting somewhere in public typing on a wireless split keyboard while staring off into space!
I connect my keyboard and my glasses to my phone, and have a small web app that sits in the middle. It can send text and images to the glasses (although the images are a bit janky), and it can capture recorded audio from the glasses, although I'm still on the lookout for a good local speech to text model. Via SSH, I can do a ton of stuff without any extra work needed!
Just a quick disclaimer: I actually regret buying these, as I have many issue with the product and, more importantly, the company. But it was an expensive purchase, so I'm making the best of it!
Building my first keyboard
NB: I wrote most of this post in March 2024, but felt like I had a lot more to say, so kept it in my drafts until now. I don't actually remember what more I wanted to say, and a lot of the things I learned in the process are now redundant! So did a bit of editing and published it now, almost 2 years later. Everything after "The Build" is recent.
There's something quite different about this post. I'm typing much slower than normal. The reason for that is that I'm not used to the keyboard that I'm typing on. That's right folks, I finally did it. I built my first keyboard! And what a journey it's been!
There's a large and active community of keyboard enthusiasts, and I could not have learned as much as I have without them (especially the ZMK Discord server), so part of why I'm writing this is to document my learnings. I could write several posts to dig a bit deeper into individual aspects, but for now I'll just summarise my journey up to now while getting some typing practice (frankly, programming is going to be a bit harder compared to writing English prose). This has all been over the course of many weeks, on and off, so bear that in mind.
Keyboards
For a while, I had been using a cheap bluetooth keyboard off of Amazon. This served me well with my setup (I'll write more about that separately, since it's unusual and people have asked me about it). I then switched to a cheap folding BT keyboard with a trackpad and multiple BT profiles, and frankly it was a bit of a downgrade. I wanted something that was clean, portable, and efficient.
I had come across futuristic takes on keyboards and fancy ergonomic keyboards, via friends and research, all with large price tags. Some examples are:
- The Tap Strap 2
- The CharaChorder
- The Twiddler 4
- The Moonlander
- The Ergodox
- The Ultimate Hacking Keyboard
- and quite a few more
Most of these are programmable and you can flash the keyboard controllers usually with QMK or ZMK firmware. There are some differences between the two, most notably that QMK is easier to use and has better support for mouse emulation, while ZMK is open source and has better support for wireless (especially split wireless) keyboards.
What does it mean to build one?
You're probably not going to design your own PCB, although I'd like to do this one day, as the PCB I'm using is open source. The rest is quite doable with basic electronics and soldering skills. It looked a bit intimidating to me from the outside since I didn't understand how the different components worked together, but it's possible to get kits. Since I didn't want to spend more that £100 to break into this hobby, I made things a bit harder on myself than they needed to be (and ended up spending more than that anyway, but it was worth it for the learning).
I wanted to build a wireless split keyboard, so some of this is specific to that, but it's not hugely different for normal keyboards. You need:
- A PCB
- Sockets and diodes
- Make sure that the kind of sockets you get fit into the board and match your switches
- Switches
- MX switches -- most common and easiest to find keycaps for, but chunkier
- Choc switches -- lower profile but newer and less common, so harder to find keycaps for, although Choc v2 is MX-compatible at the cost of footprint
- Key caps
- There is a whole industry of wild and wonderful styles and colours of caps (especially MX caps as mentioned) and I often see Etsy artists making custom resin key caps. For my first build however, I harvested these off of an older, normal mechanical keyboard.
- Controllers
- The most typical controller for split wireless keyboards is the nice!nano. I'm using a cheap clone of this off of AliExpress called the SuperMini NRF52840. This did cause some problems.

- The most typical controller for split wireless keyboards is the nice!nano. I'm using a cheap clone of this off of AliExpress called the SuperMini NRF52840. This did cause some problems.
- Battery
- Cheap AliExpress batteries will do. I also had a box of on/off switches and I glue-gunned one to each side so I can turn everything off when I want to.

- Cheap AliExpress batteries will do. I also had a box of on/off switches and I glue-gunned one to each side so I can turn everything off when I want to.
- Display (optional)
- This is optional, but common and useful. The nice!nano has a compatible display called the nice!view, but you can also use generic OLEDs (which is what I did). It could be that my build is not as battery-efficient as the brand one.
- Case
- I opted for 3D printing from a case someone else made, but you can also use laser-cut acrylic for a thinner profile.
The build
I considered documenting every step of the way here, but let's fast forward! All soldered and assembled, this is what I use:

For the most part, the building was easier than I thought. I think I only really had two main problems. The first one, and biggest slowdown, were that my controllers came broken. This was a whole bit rabbit hole of troubleshooting, and I even bought a special in-circuit debugger/programmer, but long story short, the controllers just wouldn't pair with each other.

Normally, the left side is the master (and connects to your actual PC or phone) while the right side is the slave. The correct terms are "central" and "peripheral". This is not uncommon, and there are troubleshooting instructions, but eventually I narrowed it down to a hardware issue. The moment my replacements arrived, I flashed them and they worked right out of the box.
My second problem was soldering things on and off, because of the above situation and also mistakes I made. I wasn't really following a guide since I didn't order a kit, just the parts, so I was winging it somewhat. My controllers were at an odd height if I soldered them to removable pins, not aligning with the holes in the 3D-printed case, so I soldered them straight onto the board in the end, which was too permanent!


This is the point at which I finally upgraded my soldering gear and got more tools. I'd always been able to get away with the simplest iron (plug it straight in and nothing else), but now I had a reason to get solder remover, a sucker, an iron with adjustable temperature, etc, all in a nice set off AliExpress again. This was one of the budget killers in theory!
Key maps
So the hardware is done, now it's time to program it! At the time, I thought it was so convenient how you flash firmware onto it. No need for special hardware for flashing, or worrying about accidentally bricking it. It just shows up as a USB drive on your PC and you drag the .uf2 files into it. That's it!
But now it's become even easier as you can use https://zmk.studio/, which I haven't gotten around to trying yet. I instead used a tool called ZMK Configurator which has a nice UI and builds in GitHub actions. ZMK also has a notion of "layers" that are a bit like pressing shift, except you can change your whole layout. You can also have keys that switch to every device simultaneously connected to the same keyboard via Bluetooth. It's surprisingly robust!
A friend pointed out that these days (unlike 2 years ago when I was doing this), you can just ask Claude Code to edit your config for you. You can find my full config here on GitHub. This is especially useful as ZMK can do some pretty crazy things! E.g. look at all the variations on just one aspect of hold-tap behaviour!
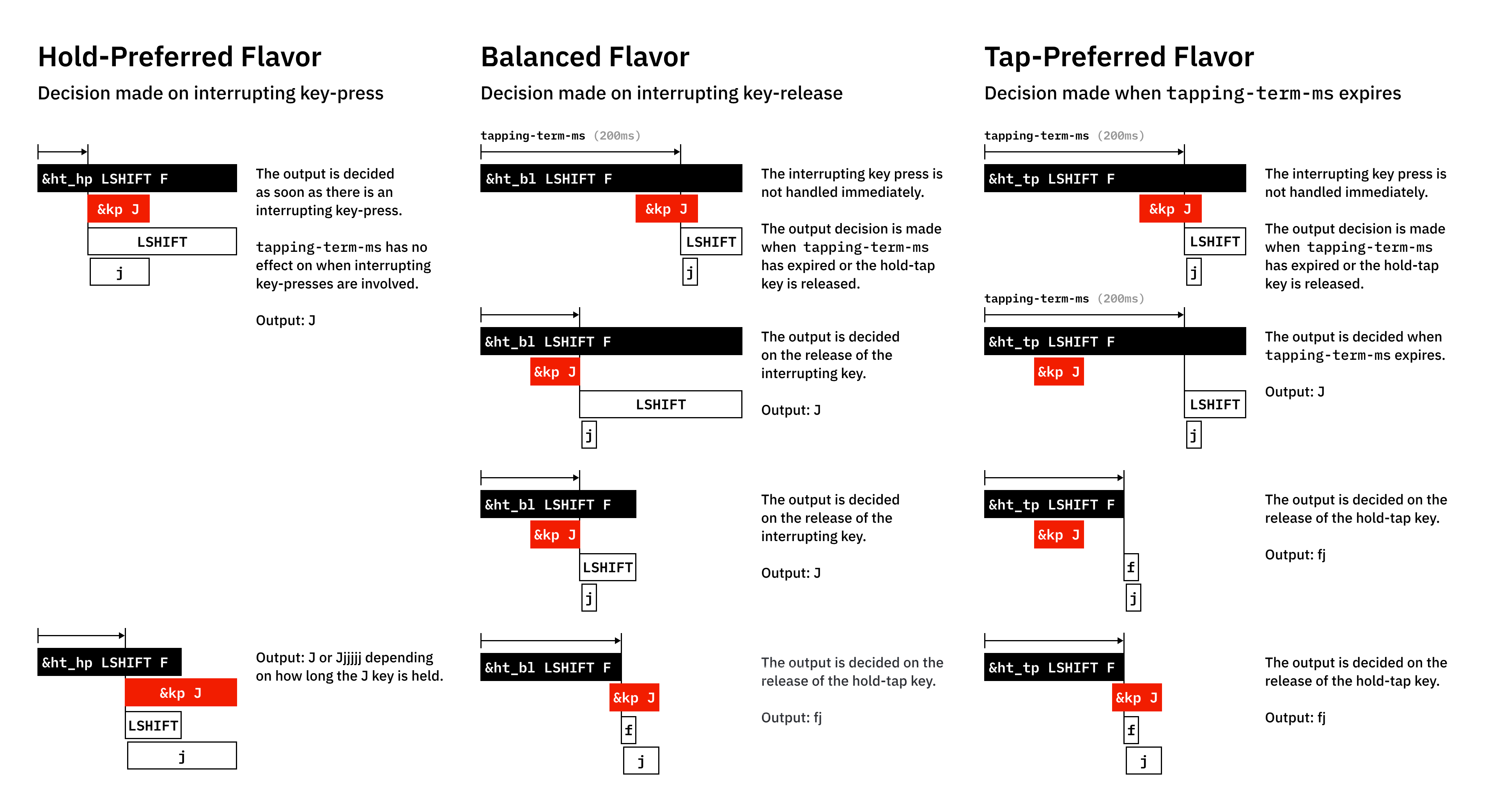
Some customisations I've done to my key map over time that I really like. I'm a big fan of mod-morph:
- Workspace switching via mod-morph: The top row (Q-P) becomes numbers 1-0 when holding GUI/Super, sending
Super+Ndirectly. This avoids the awkwardSuper+layer+numbercombination since numbers are normally on a different layer. - Top-left key is Esc, Ctrl+Tab, or Super+Q: This is done with chained mod-morphs. It's Esc by default, but when you press it with Ctrl, it acts like Ctrl+Tab (e.g. for cycling browser tabs, and you can do Shift+Ctrl+that key to go backwards). When you press it with Super, it sends Super+Q (e.g. for quitting windows). I needed this because I can no longer actually press Super+Q the normal way because of the point above.
- Ctrl/Tab hold-tap: The key below that is Ctrl when held with another key, but Tab when tapped alone (200ms tapping term).
- Backspace/Delete mod-morph: my top right key is Backspace normally, but Delete when holding GUI.
- Enter on bottom-right: The default enter position in the thumb cluster is crazy to me, and I kept sending messages before I was done typing them. So I moved it to the bottom right at pinky position, similar to a normal keyboard.
- HJKL arrow keys: I'm a vim user, so this was a no-brainer. When I switch to the lower layer, my HJKL keys become arrow keys.
- Media controls: Volume, mute, and playback controls on the lower layer's bottom row.
- Bluetooth device switching: Lower layer includes BT_CLR and BT_SEL 0-4 for managing up to 5 paired devices. I really never need to have more than 5 devices paired to my keyboard at the same time!
One thing I've alluded to but not mentioned is my old "Work from Phone" setup. I'll write about this in more detail soon, but the important bit here is that Android likes to steal your Super key for Android-y things like taking you to the home screen. To get around this, at the time, I used a tool called ExKeyMo to remap my keys Android-side. But nowadays, you can actually configure Android to send Left-Alt instead of Super via native settings. What this meant is that I can keep my ZMK mappings normal, and simply and run this on my PC to make it treat Left-Alt like Super:
xmodmap -e "remove mod1 = Alt_L"
xmodmap -e "add mod4 = Alt_L"Now, when I switch desktop workspaces via a remote desktop app, it doesn't do weird things like switching Android apps!
Two years later
Spoiler alert: I've built a second Corne keyboard in the meantime! More on that soon. However, I've become very fast at using this keyboard in the meantime, and I carry it around everywhere. I now actually struggle to use a normal keyboard, but that's fine by me.
Neigh-bours
You often need supports for plants to grow along, which is sometimes a bamboo stick. Well, how about we grow our own?

Bamboo is the fastest growing plant in the world I believe, so it will be interesting to document this. But don't be mistaken -- this is not bamboo! It's Rough Horsetail and I got it from a car boot sale, along with other neat things. However, it's quite similar and, like bamboo, it's an invasive species, can aggressively spread into neighbour gardens, and be quite difficult to permanently remove. So I'll be growing it in pots either way for my permanent supply of sticks!
A pot
Tree distraught.
Not feeling so hot.
Wind tipped it, not caught.
Tree needs a real plot.
A pot!
A pot I sought.
A pot I got.
Filled with soil I'd bought.
Lo! Size I forgot.
The space is a lot,
but stay small it will not.
"Tree will thrive", so I thought.

Breaking ground
Every morning, I eat a green Granny Smith apple. This is not only my favourite apple, but probably the only apple I actually like. It would be amazing if I could do this self-sufficiently, 365 apples a year!
I'm delighted to announce that, as of a couple days ago, I'm the proud owner of a Granny Smith apple tree from an orchard in Norfolk.

My variety is a "mini" tree that grows to 180cm (so as tall as me) from the M27 stock, which is ideal for a small garden like mine and can be grown in a pot too. I also got a bunch of pots and soil for this and other exciting things I'll write about soon!
Greenhouse effect
I moved houses recently. The new place has a conservatory and an outside space. I wouldn't quite call it a garden, as it's paved, however I do intend to get some flower beds for it. I think this will be great for my horticultural endeavours.
The most sensitive items I carried over to the new place in my arms. The first time was with the Luton van drivers in the front, where I carried my bonsai plant. The second time was the final trip over, where I carried Jinn and the ant colony.
My bonsai plant had made it in one piece, and I was glad. However, I then made the mistake of putting it in the conservatory. I did not realise just how hot it got in there. The next day, I found that the leaves on my bonsai plant had gone completely brown and shrivelled.

The glass was extremely hot to the touch — almost scalding. I realised I’d essentially cooked the plant. The moss had turned white. I immediately moved it to the cooler kitchen and rehydrated it by adding water.
I think it can bounce back over time, but this definitely is a setback. I'm very glad I didn't move the ants there.
Alien invader prongs
The ficus has been a bit thirsty, as you can tell by the leaves that have shrivelled slightly:

So I thought it's high time to first clean up the dead leaves, and also add water to the terrarium. The moss too seemed to be very dry (and I trimmed some of the long freaky moss prongs). I accidentally cut a little leaf, so I put it back into the soil, however it seems to be immune to decomposition:

This was all mid-September, and I was a tiny bit freaked out by these additional weird prongs:

Then, a little over a week ago, it started looking even more alien. The leaves were ok now (some browning?) but now these prongs looked sort of fungal. Don't like it.

A photo from today; that alien prong has grown further and is reaching the ground. I think I need to snip it before it consumes the terrarium!

Homemade lip balm
I dream of closed, self-sufficient systems. A few weeks ago, I visited the London Permaculture Festival as I'm very, very interested in permaculture. There, Hendon Soap had a stand. They were selling a DIY Lip Balm Kit.

I use lip balm regularly, so it occurred to me I ought to learn about how it's made, and maybe make my own in the long run! Today I tried my hand at making it. It's not as easy as it looks! In theory you toss everything into a sauce pan, put in 60g of oil (I used vegetable oil), and once everything is melted, you put it in the tins and put those in the freezer as fast as possible so they cool rapidly (this is to avoid a grainy texture). In theory you can also add some edible essential oils if you want a scent.
Long story short: I made a huge mess. And the stuff is quite difficult to clean. I managed to do one tin approximately right.

The rest I was mostly able to salvage and store in a little jar. When I finish that first tin, I'll re-melt that and maybe this time use a little pot with a pouring tip to avoid spilling, as well as some kind of tool for moving the very hot tins into the freezer properly! It was so hot it melted the ice in my freezer away entirely, creating a nice little indentation to hold it.

Please don't judge the ungodly amount of ice cream -- there's a heatwave coming!
The hills we live on
Just wanted to post a quick update on the ant farm. They're thriving and having all sorts of adventures!

Rising from the ashes
It's frightening how close I keep getting to killing my ficus -- they're supposed to be hardy! An update is long overdue.
First off, I moved the UV LEDs into an IKEA greenhouse. This made things much tidier and I have room for the upcoming project. The ficus had some strong growth up and to the left, all but touching the glass.
I also got these wooden drawers that you can kind of see in the back, with each one dedicated to a different project. The bottom one (taking up the whole width) is the horticulture one as that needs the most space.

Early May, I noticed that the leaves were getting brown. I thought it might be because the humidity is too high, so I thought I'd air it our a bit. Overnight it shrivelled up completely.

I was heartbroken and went to /r/Bonsai for advice. The only response I got was "it dried out and died". I did my best to try and get the humidity right and crossed my fingers. Almost two weeks later, I was delighted to see that it was still alive and had sprouted a new leaf! Can you see it?

And now, two months later, look at all this foliage!

I do plan to remove the dead leaves, but I wanted to wait for it to be a little stronger before I remove the glass again and whack things out of balance.
Rise of the messor ants
A few days ago I turned 31. Birthdays are not something I look forward to. However, Veronica gifted me an ant farm kit, which is exciting. I have always been fascinated by ants and the emergent behaviour of ant colonies, but never had the chance to observe that IRL through glass panes. In our flat in Egypt, ants were very common, so I would sometimes intentionally leave a bit of bread out on the kitchen counter just to watch them slowly take it apart and carry crumbs in a line back into the walls from whence they came.
When I was little, I also remember seeing ant farms that use a special type of transparent gel rather than sand, so you could see everything the ants were doing. I think I saw it on ThinkGeek, a now defunct online store, and wishing I could have it.
Well, today is the day that I can say I have a proper ant farm right here in my room!

The kit was surprisingly compact.


The fledgling colony made the long trip from Spain in a little test tube. Her majesty, Queen Gina, and her children, had water soaking in through the cotton on the left, some seeds as snacks while travelling, and took care of the larvae in the back of their little temporary home.

Before they could move in to their new home, I first had to make it nice and cosy for them. I started off by slowly soaking the sand over the course of the day, then decorating the top of their home. I also added their little sugar water dispenser and seed bowl. Finally, I dug a hole for them in the centre as a starting point.

I then set them free on their new home, but they stayed in the test tube for a while to build up the courage. One little brave ant ventured out, but was bringing back blue pebbles and clogging up the test tube once more. She really loved her pebbles. I later read that this is normal behaviour in order to make the queen feel more comfortable.

The moment I stopped watching they very quickly moved into their new home. I came to find the test tube empty and removed it. They had started digging and also moving the sesame seeds that Veronica had left them.


And then they started digging a LOT. I can see the beginnings of little chambers, and I read that the one at the very bottom is for storing seeds, as it's the least humid area, and they take advantage of that to prevent seeds from sprouting.


I'm excited to see how this colony develops! It's already developing much faster than I expected. I'm awaiting a new set of mixed bird seeds in the mail today, as I don't think they like sesame seeds that much, and Veronica also left them a broken up spaghetti.
Ficus rollercoaster
I recently wrote about my ficus terrarium and how some kind of mould defeated my fittonia. Since then, I've learned a lot more about terrariums (including learning about ones where you keep frogs and reptiles, from a very friendly pet shop employee). The ficus however, which is meant to be quite hardy, did eventually have the same mould problem.
By early January, it was getting quite dire. No matter how much I tried to control the humidity, the leaves were all dying and there was thread-like mould forming like spider webs. I don't think I took a photo of this.
I did some more research and found a potential solution: little creatures called springtails (this was later confirmed to me by friendly pet shop guy). I ordered live Springtails off of Amazon (I didn't know you could do that) and they arrived quite quickly.

They arrive in some soil. The cardboard box they arrived in was smaller than the plastic container, so the act of squishing the plastic container into that box had caused it to open. It was kind of a messy situation. Regardless, I introduced them into the terrarium, slowly adding more over time. They're kind of hard to see with the naked eye, but if you really focus you can see them crawling around. They can also jump, which to me looks like they just disappear.
Fast-forward to today... it worked! They cleaned up the mould on the glass as well as the white threads that were attacking the plant. They seem to fit well into this ecosystem! I still have the container with the rest of them, which I might have a future use for (hint: my ant farm I will write about soon).
I am glad to report that new leaves have sprouted, and the health of the ficus looks like it's slowly improving!

Stay tuned to know more about my horticulture adventures, including a new plant project that I will write about soon! Hint:

First attempt at actually organising my bookmarks
In April 2023, I came across this article and found it very inspiring. I had already been experimenting with ways of visualising a digital library with Shelfiecat. The writer used t-SNE to "flatten" a higher-dimensional coordinated space into 2D in a coherent way. He noticed that certain genres would cluster together spatially. I experimented with these sorts of techniques a lot during my PhD and find them very cool. I just really love this area of trying to make complicated things tangible to people in a way that allows us to manipulate them in new ways.
My use case was my thousands of bookmarks. I always felt overwhelmed by the task of trying to make sense of them. I might as well have not bookmarked them as they all just sat there in piles (e.g. my Inoreader "read later" list, my starred GitHub repos, my historic Pocket bookmarks, etc). I had built a database of text summaries of a thousand or so of these bookmarks using Url summariser, and vector embeddings of these that I dumped into a big CSV file, which at the time cost me approximately $5 of OpenAI usage. This might seem steep, but I think at the time nobody had access to GPT-4 yet, and the pricing also wasn't as low. I had also I accidentally had some full-length online books bookmarked, and my strategy of recursively summarising long text (e.g. YouTube transcripts) didn't have an upper limit, so I had some book summaries as well.
Anyway, I then proceeded to tinker with t-SNE and some basic clustering (using sklearn which is perfect for this sort of experimentation). I wanted to keep my data small until I found something that sort of works, as sometimes processing takes a while which isn't conducive to iterative experimentation! My first attempt was relatively disappointing:
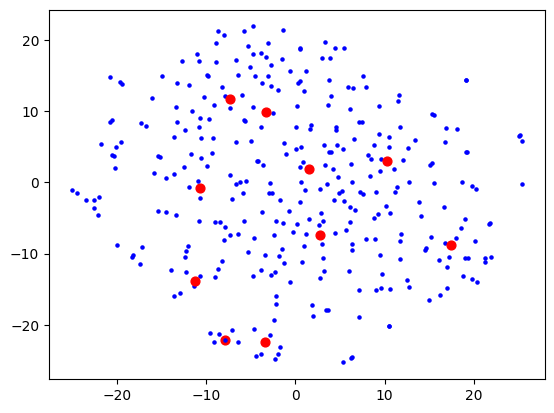
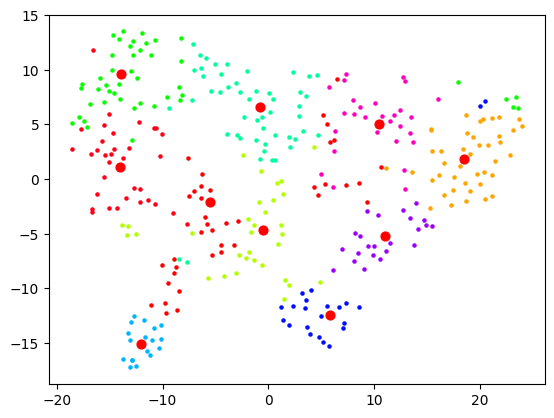
Here, each dot is a bookmark. The red dots are not centroids like you would get from e.g. k-means clustering, but rather can be described as "the bookmark most representative of that cluster". I used BanditPAM for this, after reading about it via this HackerNews link, and thinking that it would be more beneficial for this use case.
I was using OpenAI's Ada-2 for embeddings, which outputs vectors with 1536 dimensions, and I figured the step from 1536 to 2 is too much for t-SNE to give anything useful. I thought that maybe I need to do some more clever dimensionality reduction techniques first (e.g. PCA) to get rid of the more useless dimensions first, before trying to visualise. This would also speed up processing as t-SNE does not scale well with number of dimensions. Reduced to 50, I started seeing some clusters form:
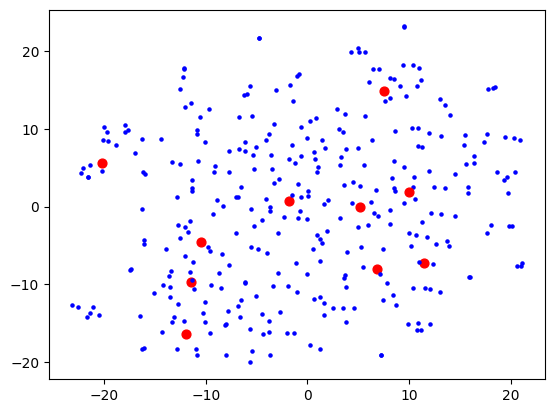
Then 10:
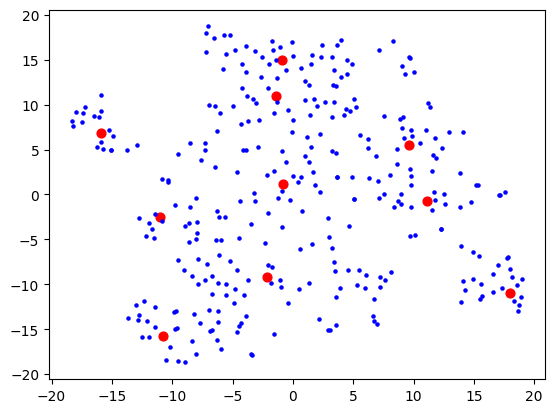
Then 5:
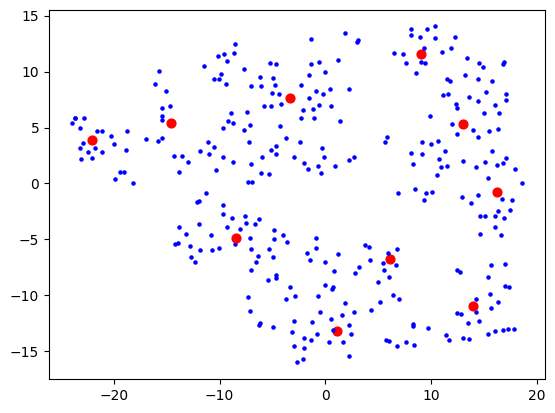
5 which wasn't much better than 10, so I stuck with 10. I figured my bookmarks weren't that varied anyway, so 10 dimensions are probably good enough to capture the variance of them. Probably the strongest component will be "how related to AI is this bookmark" and I expect to see a big AI cluster.
I then had a thought that maybe I should use truncated SVD instead of PCA, as that's better for sparse data, and I was picturing this space in my mind to really be quite sparse. The results looked a bit cleaner:
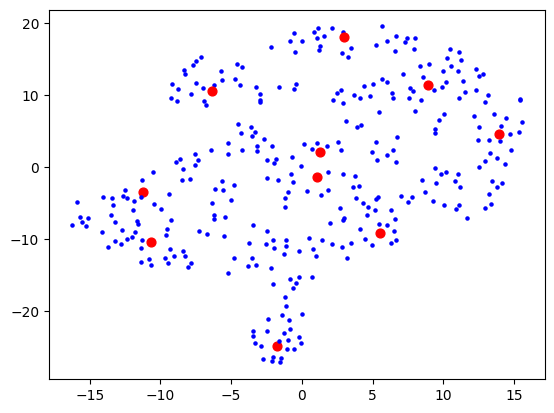
Now let's actually look at colouring these dots based on the cluster they're in. Remember that clustering and visualising are two separate things. So you can cluster and label before reducing dimensions for visualising. When I do the clustering over 1500+ dimensions, and colour them based on label, the visualisation is quite pointless:
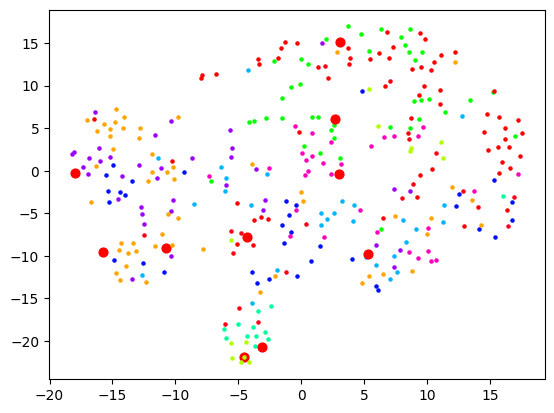
When I reduce the dimensions first, then we get some clear segments, but the actual quality of the labelling is likely not as good:
And as expected, no dimension reduction at all gives complete chaos:
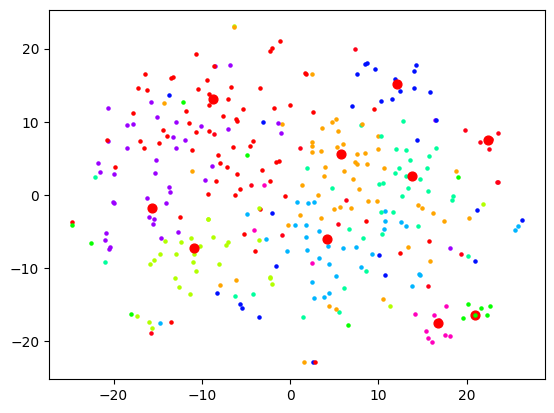
I started looking at the actual content of the clusters and came to a stark realisation: this is not how I would organise these bookmarks at all. Sure, the clusters were semantically related in some sense, but I did not want an AI learning resource to be grouped with an AI tool. In fact, did I want a top-level category to be "learning resources" and then that to be broken down by topic? Or did I want the topic "AI" to be top-level and then broken down into "learning resources", "tools", etc.
I realised I hadn't actually thought that much about what I wanted out of this (and this is also the main reason why I limited the scope of Machete to just bookmarks of products/tools). I realised that I would first need to define that, then probably look at other forms of clustering.
I started a fresh notebook, and ignored the page summaries. Instead, I took the page descriptions (from alt tags or title tags) which seemed in my case to be much more likely to say what the link is and not just what the content is about. This time using SentenceTransformer (all-MiniLM-L6-v2) as Ada-2 would not have been a good choice here, and frankly, was probably a bad choice before too.
I knew that I wanted any given leaf category (say, /products/tools/development/frontend/) shouldn't have more than 10 bookmarks or so. If it passes that threshold, maybe it's time to go another level deeper and further split up those leaves. This means that my hierarchy "tree" would not be very balanced, as I didn't want directories full of hundreds of bookmarks.
I started experimenting with Agglomerative Clustering, and visualising the results of that with a dendrogram:
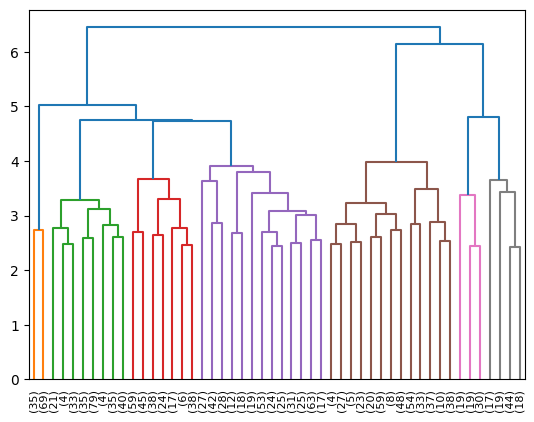
Looking at the where bookmarks ended up, I still wasn't quite satisfied. Not to mention, there would need to be maybe some LLM passes to actually decide what the "directories" should be called. It was at this point that I thought that maybe I need to re-evaluate my approach. I was inadvertently conflating two separate problems:
- Figuring out a taxonomy tree of categories
- Actually sending bookmarks down the correct branches of that tree
There's a hidden third problem as well: potentially adjusting the tree every time you add a new bookmark. E.g. what if I suddenly started a fishing hobby? My historical bookmarks won't have that as a category.
I thought that perhaps (1) isn't strictly something I need to automate. I could just go through the one-time pain of skimming through my bookmarks and trying to come up with a relatively ok categorisation schema (that I could always readjust later) maybe based on some existing system like Johnny•Decimal. I could also ask GPT to come up with a sane structure given a sample of files.
As time went on, I also started to spot some auto-categorisers in the wild for messy filesystems that do the GPT prompting thing, and then also ask GPT where the files should go, then moves them there. Most notably, this.
That seems to me so much easier and reliable! So my next approach is probably going to be having each bookmark use GPT as a sort of "travel guide" in how it propagates the tree. "I'm a bookmark about X, which one of these folders should I move myself into next?" over and over until it reaches the final level. And when the directory gets too big, we ask GPT to divide it into two.
The LLM hammer seems to maybe win out here -- subject to further experimentation!
Sentinel gets a brain and listens to the internet
Sentinel, my AI personal assistant has evolved a bit since I last wrote about him. I realised I hadn't written about that project in a while when it came up in conversation and the latest reference I had was from ages ago. The node-red logic looks like this now:
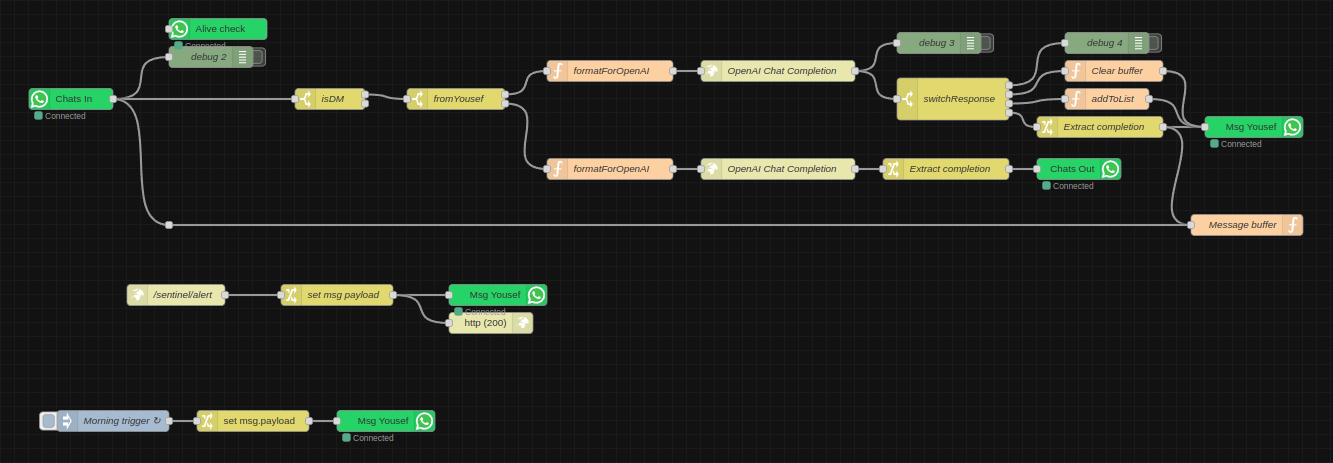
- Every morning he sends me a message (in the future this will be a status report summary). The goal of this was to mainly make sure the WhatsApp integration still works, since at the time it would crap out every once in a while and I wouldn't realise.
- I have an endpoint for arbitrary messages, which is simply a URL with a text GET parameter. I've sprinkled these around various projects, as it helps to have certain kind of monitoring straight to my chats.
- He's plugged in to GPT-4-turbo now, so I usually just ask him questions instead of going all the way to ChatGPT. He can remember previous messages, until I explicitly ask him to forget. This is the equivalent of "New Chat" on ChatGPT and is controlled with the functions API via natural language, like the list-adder function which I already had before ("add Harry Potter to my movies list").
As he's diverged from simply being an interface to my smart home stuff, as well as amarbot which is meant to replace me, I decided to start a new project log just for Sentinel-related posts.
Edit: this post inspired me to write more at length about chat as an interface here.
Ficus in a glass egg
I was recently offered condolences when someone found out about the unfortunate fate that befell my Bonsai plant. There's a small update!
A little over a month ago, Veronica and I went to a terrarium workshop and put together a little home for a little ficus. They're very hardy.

I picked everything out down to the colours of the sand layers and we carefully placed and aligned everything. It's not just pretty, but everything has a function. For example, the moss tells you when when it's time to add (distilled!) water, the large rocks can provide a surface for that water to evaporate (rather than get absorbed by the moss). We also added two dinosaurs, one patting the head of the other one.
As hardy as the ficus is, unfortunately the fittonia in the back was a lot more temperamental. I thought it maybe couldn't handle the humidity (the guides said you shouldn't let too much condensation build up on the glass) or it needed more light. It unfortunately started getting these strands of mould and eventually became a gloop.

I called the workshop instructor and he said there may be a number of reasons for this, asked for photos to troubleshoot, and he offered to replace it if I came by, but Shoreditch is kind of a trek from here. He said I should take it out so that it doesn't damage the ficus. In the meantime, I also got some grow lights so I can have a bit more control over the environment, rather than be at the mercy of UK winter weather!

Machete: a tool to organise my bookmarks
I've had a problem for a while around organising articles and bookmarks that I collect. I try not to bookmark things arbitrarily, and instead be mindful of the purpose of doing so, but I still have thousands of bookmarks, and they grow faster than I can process them.
I've tried automated approaches (for example summarising the text of these webpages and clustering vector embeddings of these) with limited success so far. I realised that maybe I should simply eat the frog and work my way through these, then develop a system for automatically categorising any new/inbound bookmark on the spot so they stay organised in the future.
A new problem was born: how can I efficiently manually organise my bookmarks? The hardest step in my opinion is having a good enough overview of the kinds of things I bookmark such that I can holistically create a hierarchy of categories, rather than the greedy approach where I tag things on the fly.
I decided to first focus on bookmarks that I would categorise as "tools", which are products or services that I currently use, may use in the future, want to look at to see if they're worth using, or may want to recommend to others in the future if they express a particular need. These are a bit more manageable as they're a small subset; the bigger part of my bookmarks are general knowledge resources (articles etc).
At the moment, I rely on my memory for the above use cases. Often I don't remember the name of a tool, but I can usually find it with a substring search of the summaries. Often I don't remember tools in the first place, and am surprised to find that I bookmarked something that I wish I would have remembered existed.
Eventually, I landed on a small script to convert all my notes into files, and then using different file browsers to drag and drop files into the right place. This was still very cumbersome.
On the front page of my public notes I have two different visualisations for browsing these notes. I find them quite useful for getting an overview. I thought it might be quite useful to use the circles view for organisation too. So I thought I should make a minimal file browser that displays files in this way, for easy organisation.
Originally, I took this as an excuse to try Tauri (a lighter Electron equivalent built on Rust that uses native WebViews instead of bundled Chromium), and last month I did get an MVP working, but then I realised that I'm making things hard on myself, especially since the development workflow for Tauri apps wasn't very smooth with my setup.
So instead, I decided to write this as an Obsidian plugin, since Obsidian is my main PKM tool. Below is a video demo of how far I got.
You can:
- Visualise files and directories in your vault
- Pan with middle-mouse
- Zoom with the scroll wheel
- Drag and drop nodes (files or directories) to move them
Unlike the visualisation on my front page, which uses word count for node size, this version uses file size. So far, it helps with organisation, although I would like to work on a few quality-of-life things to make this properly useful.
- A way to peek at the contents in a file without opening it
- Better transitions when the visualisation updates (e.g. things moving or changing size) so you don't get lost
- Mobile support (mainly alternative controls, like long-press to drag)
Disaster has struck
Towards the end of August, I went to visit my mum in Germany. Veronica would take care of my bonsai plant in my absence. One day she woke up to a gruesome murder scene (warning, graphic images to follow).

Veronica thought it got too top-heavy and broke, but Black Pine saplings don't just explode like that. I knew it was our cat Jinn. In a bunch of further images, I noticed what look like nibble marks too. I know she likes to nibble on grass too. I insisted that she immediately tell the cat off and show her what she did wrong. Cats are not that smart and won't be able to connect consequences to their actions unless they're tightly associated. In my opinion, Veronica is consistently too soft on the cat.
Veronica felt bad about the death of bonsai buddy (although she insists it can still be saved) but it seemed to me a 10 year journey was cut prematurely short. There's not much that can be done in my opinion except starting over. Since I've been back, I've been seeing if it can be saved, with not much success yet. This is what it looks like today:

When I came back, Jinn was very misbehaved for a bit. She knows she's not allowed to jump on my desk -- twice I caught her doing so and sniffing the bonsai corpse while she thought I was asleep. She knows that certain other areas are out of bounds for her, and she was pushing those boundaries. It took her a week or two of me being back for her to go back to normal and for us to be friends again.
R.I.P. bonsai buddy
Blast-off into Geminispace
Today was the "Build a Website in an Hour" IndieWeb event (more info here). I went in not quite knowing what I wanted to do. Then, right as we began, I remembered learning about Gemini and Astrobotany from Jo. I thought this would be the perfect opportunity to explore Gemini, and build a Gemini website!
Gemini is a simple protocol somewhere between HTTP and Gopher. It runs on top of TLS and is deliberately quite minimal. You normally need a Gemini client/browser in order to view gemini:// pages, but there's an HTTP proxy here.
I spent the first chunk of the hour trying to compile Gemini clients on my weird setup. Unfortunately, this proved to be quite tricky on arm64 (I also can't use snap or flatpak because of reasons that aren't important now). I eventually managed to install a terminal client called Amfora and could browse the Geminispace!
Then, I tried to get a server running. I started in Python because I thought this was going to be hard as-is, and I didn't want to take more risks than needed, but then I found that it's actually kind of easy (you only need socket and ssl). Once I had a server working in Python, I thought that I actually would prefer if I could run this off of the same server that this website (yousefamar.com) uses. Most of this website is static, but there's a small Node server that helps with rebuilding, wiki pages, and testimonial submission.
So for the next chunk of time, I implemented the server in Node. You can find the code for that here. I used the tls library to start a server and read/write text directly from/to a socket.
Everything worked fine on localhost with self-signed certificates that I generated with openssl, but for yousefamar.com I needed to piggyback off of the certificates I already have for that domain (LetsEncrypt over Caddy). I struggled with this for most of the rest of the time. I also had an issue where I forgot to end the socket after writing, causing requests to time out.
I thought I might have to throw in the towel, but I fixed it just as the call was about to end, after everyone had shown their websites. My Gemini page now lives at gemini://yousefamar.com/ and you can visit it through the HTTP proxy here!
I found some Markdown to Gemini converters, and I considered having all my public pages as a capsule in Geminispace, but I think many of them wouldn't quite work under those constraints. So instead, in the future I might simply have a gemini/ directory in the root of my notes or similar, and have a little capsule there separate from my normal web stuff.
I'm quite pleased with this. It's not a big deal, but feels a bit like playing with the internet when it was really new (not that I'm old enough to have done that, but I imagine this is what it must have felt like).
Forgotten Conquest port
A while ago I wrote about discovering a long-forgotten project from 2014 I had worked on in the past called Mini Conquest. As the kind of person who likes to try a lot of different things all the time, over my short 30 years on this earth I have forgotten about most of the things I've tried. It can therefore be quite fun to forensically try and piece together what my past self was doing. I thought I had gotten to the bottom of this project and figured it out: an old Java gamedev project that allowed me to play around with the 2.5D mechanic.
Well, it turns out that's not where it ended. Apparently, I had ported the whole thing to Javascript shortly after, meaning it actually runs in the browser, even today somehow! I had renamed it to "Conquest" by then. As was my style back then, I had 0 dependencies and wanted to write everything from scratch.
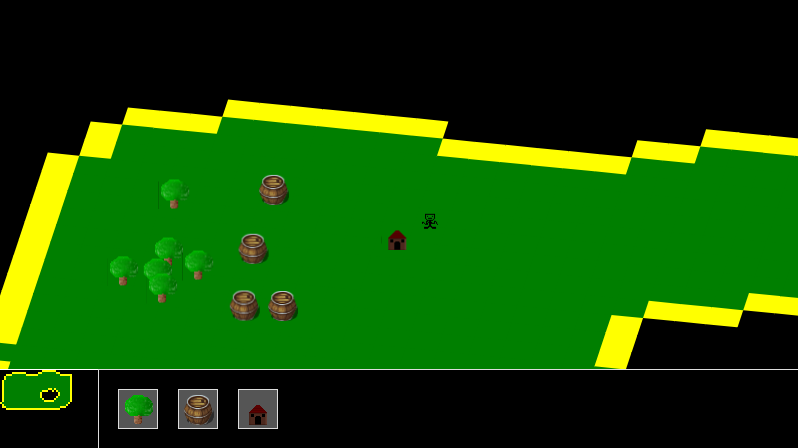
If you've read what I wrote about the last one, you might be wondering why the little Link character is no longer there, and what the deal with that house and the stick figure is. Well, turns out I decided to change genres too! It was no longer a MOBA/RTS but more like a civilisation simulator / god game.
The player can place buildings, but the units have their own AI. The house, when place, can automatically spawn a "Settler". I imagine that I probably envisioned these settlers mining and gathering resources on their own, with which you can decide what things to build next, and eventually fight other players with combat units. To be totally honest though, I no longer remember what my vision was. This forgetfulness is why I write everything down now!
The way I found out about this evolution of Mini Conquest was also kind of weird. On the 24th of January 2023, a GitHub user called markeetox forked my repo, and added continuous deployment to it via Vercel. The only evidence I have of this today is the notification email from Vercel's bot; all traces of this repo/deployment disappeared shortly after. Maybe he was just curious what this is.
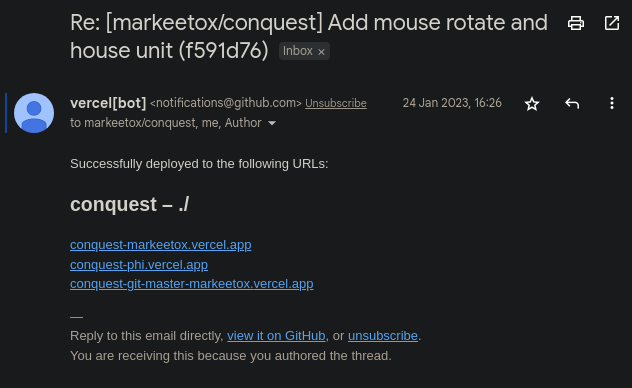
I frankly don't quite understand how this works. The notification came from his repo on a thread related to a commit or something, that is apparently authored by me (since I authored the commit?) and I've been automatically subscribed in his fork? Odd!
Homebound: an old game jam project revived
Around two months ago, I was talking to a friend about these games that involve programming in some form (mainly RTSs where you program your units). Some examples of these are:
- https://leekwars.com
- https://codingame.com
- https://spacetraders.io
- https://screeps.com
- The various normal games that let you program AI players
Needless to say, I'm a fan of these games. However, during that conversation, I suddenly remembered: I made a game like this once! I had completely forgotten that for a game jam, I had made a simple game called Homebound. You can learn more about it at that link!
At the time, you could host static websites off of Dropbox by simply putting your files in the Public folder. That no longer worked, so the link was broken. I dug everywhere for the project files, but just couldn't find them. I was trying to think if I was using git or mercurial back then and where I could have put them. I think it's likely I didn't bother because it was something small to put out in a couple of hours.
Eventually, in the depths of an old hard drive, I found a backup of my old Dropbox folder, and in that, the Homebound source code! Surprisingly, it still worked perfectly in modern browsers (except for a small CSS tweak) and it now lives on GitHub pages.
Then, I forgot about this again (like this project is the Silence), until I saw the VisionScript project by James, which reminded me of making programming languages! So I decided to create a project page for Homebound here.
I doubt I will revisit this project in the future, but I might play with this mechanic again in the context of other projects. In that case, I might add to this devlog to reference that. I figured I should put it out there for posterity regardless!
Miniverse open source
I made some small changes to the Miniverse project. It still feels a bit boring, but I'm trying different experiments, and I think I want to try a different strategy, similar to Voyager for Minecraft. Instead of putting all the responsibility on the LLM to decide what to do each step of the simulation, I want to instead allow it to modify its own imperative code to change its behaviour when need be. Unlike the evolutionary algos of old, this would be like intelligent design, except the intelligence is the LLM, rather than the LLM controlling the agents directly.
Before I do this however, I decided to clean the codebase up a little, and make the GitHub repo public, as multiple people have asked me for the code. It could use a bit more cleanup and documentation, but at least there's a separation into files now, rather than my original approach of letting the code flow through me into a single file:

I also added some more UI to the front end so you can see when someone's talking and what they're saying, and some quality of life changes, like loading spinners when things are loading.
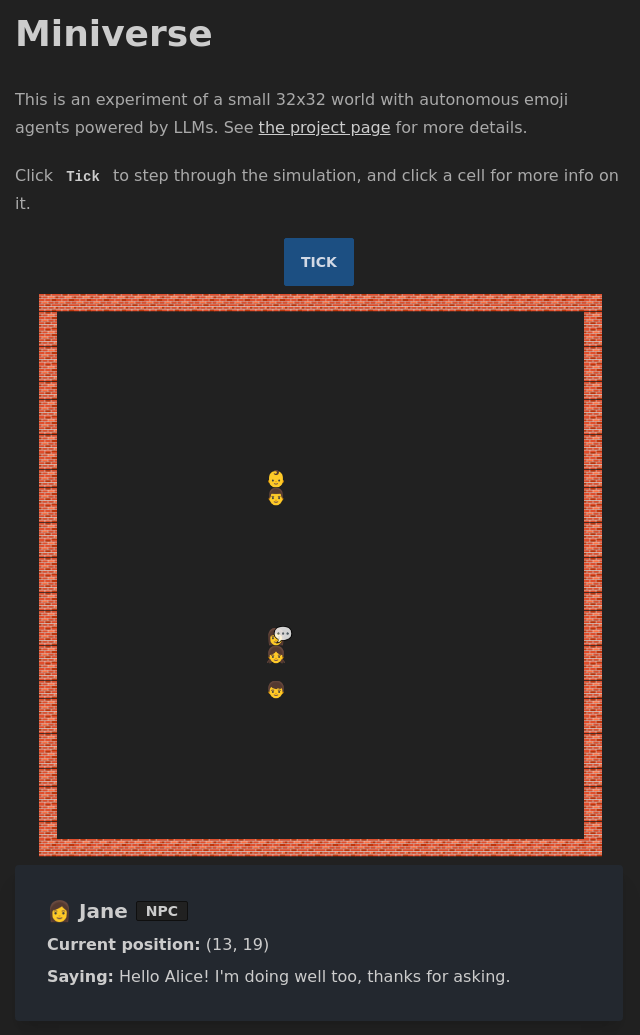
There's still a lot that I can try here, and the code will probably shift drastically as I do, but feel free to use any of it. You need to set the OPENAI_KEY environment variable and the fly.io config is available too if you want to deploy there (which I'm doing). The main area of interest is probably NPC.js which is where the NPC prompt is built up.
Collecting testimonials for mentorship/advisory
(Skip to the end for the conclusion on how this has affected my website, or continue reading for the backstory).
For as long as I can remember, I've been almost consistently engaged in some form of education or mentorship. Going back to my grandparents, and potentially great-grandparents, my family on both sides has all been teachers, professors, and even a headmaster, so perhaps it's something in my blood. I started off teaching in university as a TA (and teaching at least one module outright where the lecturer couldn't be bothered). Later, I taught part-time in a pretty rough school (which was quite exhausting) and even later at a much fancier private school (which wasn't as exhausting, but much less fulfilling) and finally I went into tutoring and also ran a related company. I wound this business up when covid started.
Over the years I found that, naturally, the smaller the class, the more disproportional impact you can have when teaching. I also found that that personal impact goes up exponentially not when I teach directly, but zoom out and find out what it is the student actually needs (especially adult students), and help them unblock those problems for themselves. As the proverb goes,
"Give a man a fish, and you feed him for a day. Teach a man to fish, and you feed him for a lifetime."
There's also a law of diminishing returns at play here. By far the biggest impact you can have when guiding someone to reach their goals (academic or otherwise) comes at the very start. This immediate impact has gotten bigger and bigger over time as I've learned more and more myself. Sometimes it's a case of simply reorienting a person, and sending them on their way, rather than holding their hand throughout their whole journey.
This is how I got into mentoring. I focused mainly on supporting budding entrepreneurs and developers from underpriviledged groups, mainly organically through real-life communities, but also through platforms like Underdog Devs, ADPList, Muslamic Makers and a handful of others. If you do this for free (which I was), you can only really do on the side, with a limited amount of time. I wasn't very interested in helping people who could actually afford paying me for my time, paradoxically enough...
I decided recently that there ought to be an optimal middle ground that maximises impact. 1:1 mentoring just doesn't scale, and large workshop series aren't effective. I wanted to test a pipeline of smaller cohorts and mix peer-based support with standard coaching. I have friends who I've worked with before who are willing to help with this, and I think I can set up a system that would be very, very cheap and economically accessible to the people I care about helping.
Anyway, I've started planning a funnel, and building a landing page. Of course, any landing page worth its salt ought to have social proof. So I took to LinkedIn. I never post to LinkedIn (in fact, this might actually have been my very first post in the ~15 years I've been on there). I found a great tool for collecting testimonials in my toolbox called Famewall, set up the form/page, and asked my LinkedIn network to leave me testimonials.
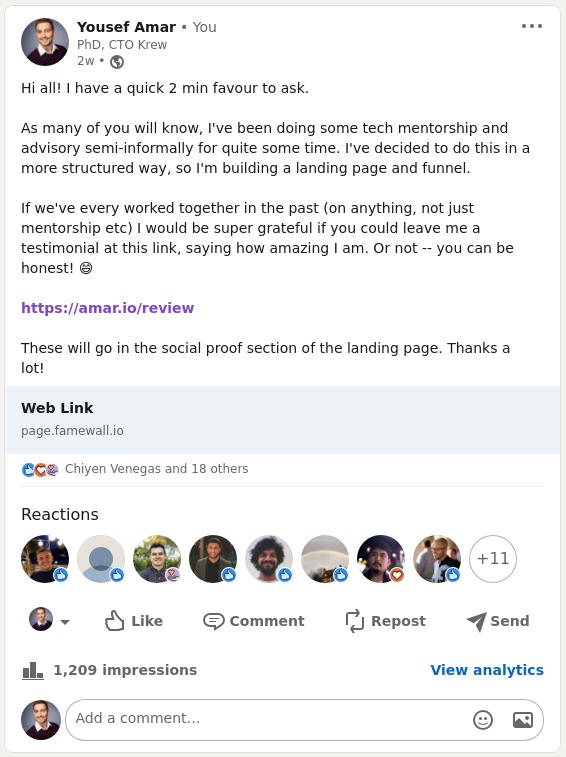
There were a handful of people that I thought would probably respond, but I was surprised that instead other people I completely hadn't expected were responding. In some cases, people that I genuinely didn't remember, and in other cases people where I didn't realise just how much of an impact I had on them. This was definitely an enlightening experience!
I immediately hit the free tier limit of Famewall and had to upgrade to a premium tier to access newer testimonials that were rolling in. It's not cheap, and I'm only using a tiny fraction of the features, but the founder is a fellow indie hacker building it as a solo project and doing a great job, and we chatted a bit, so I figured I should support him.
I cancelled my subscription a few days later when I got around to re-implementing the part that I needed on my own site. That's why this post is under the Website project; the review link (https://amar.io/review) now redirects to a bog standard form for capturing testimonials (with a nice Lottie success animation at the end, similar to Famewall) and in the back end it simply writes the data to disk, and notifies me that there's a new testimonial to review. If it's ok, I tweak the testimonial JSON and trigger an eleventy rebuild (this is a static site). In the future, I might delegate this task to Sentinel!
The testimonials then show up on this page, or any other page onto which I include testimonials.njk (like the future mentoring landing page). For the layout, I use a library called Colcade which is a lighter alternative to Masonry recommended to me by ChatGPT when I asked for alternatives, after Masonry was giving me some grief. It works beautifully!
Amarbot merges into my cyborg self
Amarbot no longer has a WhatsApp number. This number now belongs to Sentinel, the custodian of Sanctum.
This number was originally wired up directly to Sanctum functions, as well as Amarbot's brain; a fine-tuned GPT-J model trained on my chat history. Since this wiring was through Matrix it became cumbersome to have to use multiple Matrix bridges for various WhatsApp instances. I eventually decided use that model on my actual personal number instead, which left Amarbot's WhatsApp number free.
Whenever Amarbot responds on my behalf, there's a small disclaimer. This is to make it obvious to other people whether it's actually me responding or not, but also so when I retrain, I can filter out artificial messages from the training data.
Sentinel: my AI right hand
I mentioned recently that I've been using OpenAI's new functions API in the context of personal automation, which is something I've explored before without the API. The idea is that this tech can short-circuit going from a natural language command, to an actuation, with nothing else needed in the middle.
The natural language command can come from speech, or text chat, but almost universally, we're using conversation as an interface, which is probably the most natural medium for complex human interaction. I decided to use chat in the first instance.
Introducing: Sentinel, the custodian of Sanctum.
No longer does Sanctum process commands directly, but rather is under the purview of Sentinel. If I get early access to Lakera (the creators of Gandalf), he would also certainly make my setup far more secure than it currently is.
I repurposed the WhatsApp number that originally belonged to Amarbot. Why WhatsApp rather than Matrix? So others can more easily message him -- he's not just my direct assistant, but like a personal secretary too, so e.g. people can ask him for info if/when I'm busy. The downside is that he can't hang out with the other Matrix bots in my Neurodrome channel.
A set of WhatsApp nodes for Node-RED were recently published that behave similarly to the main Matrix bridge for WhatsApp, without all the extra Matrix stuff in the way, so I used that to connect Sentinel to my existing setup directly. The flow so far looks like this:

The two main branches are for messages that are either from me, or from others. When they're from others, their name and relationship to me are injected into the prompt (this is currently just a huge array that I hard-coded manually into the function node). When it's me, the prompt is given a set of functions that it can invoke.
If it decides that a function should be invoked, the switchResponse node redirects the message to the right place. So far, there are only three possible outcomes: (1) doing nothing, (2) adding information to a list, and (3) responding normally like ChatGPT. I therefore sometimes use Sentinel as a quicker way to ask ChatGPT one-shot questions.
The addToList function is defined like this:
{
name: "addToList",
description: "Adds a string to a list",
parameters: {
type: "object",
properties: {
text: {
type: "string",
description: "The item to add to a list",
},
listName: {
type: "string",
description: "The name of the list to which the item should be added",
enum: [
"movies",
"books",
"groceries",
]
},
},
required: ["text", "listName"],
},
}I don't actually have a groceries list, but for the other two (movies and books), my current workflow for noting down a movie to watch or a book to read is usually opening the Obsidian app on my phone and actually adding a bullet point to a text file note. This is hardly as smooth as texting Sentinel "Add Succession to my movies list". Of course, Sentinel is quite smart, so I could also say "I want to watch the first Harry Potter movie" and he responds "Added "Harry Potter and the Sorcerer's Stone" to the movies list!".
The actual code for adding these items to my lists is by literally appending a bullet point to their respective files (I have endpoints for this) which are synced to all my devices via the excellent Syncthing. In the future, I could probably make this fancier, e.g. query information about the movie/book and include a poster/cover and metadata, and also potentially publish these lists.
Building the Miniverse
I've been experimenting with OpenAI's new functions API recently, mostly in the context of personal automation, which is something I've explored before without the API (more on that in the future). However, something else I thought might be interesting would be to give NPCs in a virtual world a more robust brain, like the recent Stanford paper. This came in part from the thinking from yesterday's post.
The Stanford approach had many layers of complexity and they were attempting to create something that is close to real human behaviour. I'm less interested in that, and would instead like to design an environment with much higher constraints based on simple rules. I think finding the right balance there leads to the most interesting emergent results.
So my first goal was to create a very tightly scoped environment. I decided to start with a 32x32 grid, made of emojis, with 5 agents randomly spawned. The edge of the grid is made of walls so they don't fall off.
 Agents after they had walked towards each other for a chat
Agents after they had walked towards each other for a chat
When I was originally scoping this out, I thought I would add mechanisms for interacting with items too. These items could be summoned in some way perhaps. I built a small API for getting the nearest emoji to item text as well, which is still up at e.g. https://gen.amar.io/emoji/green apple (replace "green apple" with whatever). It also caches the emojis so overall not expensive to run.
I also explored various models for generating emoji-like images, for the more fantastical items, and landed on emoji diffusion. It was at this point that I quickly realised I'm losing control of the scope, and decided to focus on NPCs only, and no items.
Each simulation step (tick) would iterate over all agents and compute their actions. I planned for these possible actions:
- Do nothing
- Step forward
- Step back
- Step left
- Step right
- Say X
- Remember X (doesn’t end round)
I wanted the response from OpenAI to only be function calls, which unfortunately you can't control, so I had to add to the prompt You MUST perform a single function in response to the above information. If I get any bad response, we either retry or fall back to "do nothing", depending.
The prompt contained some basic info, a goal, the agent's surroundings, the agent's memory (a truncated list of "facts"), and information on events of the past round. I found that I couldn't quite rely on OpenAI to make good choices, so I selectively build the list of an agent's capabilities on the fly each tick. E.g. if there's nobody in speaking distance, we don't even give the agent the ability to speak. If there's a wall ahead of the agent, we don't even give the agent the chance to step forward. And if the agent just spoke, they lose the ability to speak again for the following round or else they speak over each other.
I had a lot of little problems like that. Overall, the more complicated the prompt, the more off the rails it goes. Originally, I tried The message from God is: "Make friends" as I envisioned interaction from the user coming in the form of divine intervention. But then some of the agents tried speaking to God and such, so I replaced that with Your goal is: "Make friends", and later Your goal is: "Walk to someone and have interesting conversations" so they don't just walk randomly forever.
They would also feel compelled to try and remember a lot. Often the facts they remembered were quite useless, like the goal, or their current position. The memory was small, so I tried prompt engineering to force them to treat memory as more precious, but it didn't quite work. Similarly, they would sometimes go on endless loops remembering the same useless fact over and over. I originally had all information in their memory (like their name) but I didn't want them to forget their name, so put the permanent facts outside.
Eventually, I removed the remember action, because it really wasn't helping. They could have good conversations, but everything else seemed a bit stupid, like I might as well program it procedurally instead of with LLMs.
I did however focus a lot on having a very robust architecture for this project, and made all the different parts easy to build on. The server does the simulation (in the future, asynchronously, but today, through the "tick" button) and stores world state in a big JSON object that I write to disk so I can rewind through past states. There is no DB, we simply read/write from/to JSON files as the world state changes. The structure of the data is flexible enough that I don't need to modify the schemas, and it can remain pretty forwards-compatible as I make additions, so I can run the server off of older states and it picks up those states gracefully.
Anyway, I'll be experimenting some more and writing up more details on the different parts as they develop!
I can finally sing
Ever since I discovered the Discord server for AI music generation, I knew I needed to train a model to make my voice a great singer. It took some figuring out, but now I'm having a lot of fun making myself sing every kind of song. I've tried dozens now, but here are some ones that are particularly notable or fun (I find it funniest when things glitch out especially around the high notes):
Project grid
When people visit my website, it's not very clear to them what it is I actually do. It used to be that my website doubled as my CV, but after a while that became sort of useless as I no longer needed to apply to jobs, and I stopped maintaining it.
Recently, I began revamping the landing page of my website (yet again) and started off by cleaning up the hero section. I had a bunch of icons that represented links, and thought I was being clever and language-agnostic by using icons instead of text, but then realised that even I was forgetting what icon meant what, so I couldn't begin to hope that others would know what they meant. So I added text. And I made the WebGL avatar have an image fallback in case the browser doesn't support WebGL. Similarly, I froze the parallax effects under the same conditions as those rely on hardware acceleration.
Then, I decided to create a project grid right under the hero. I wanted to treat this as a showcase of the things I am involved in, or have been involved in, loosely in order of importance. This has been inspired by:
- Philipp Lenssen, from whom I originally got the idea, and realised the tiles don't even really need to strictly be "projects" but can be whatever you want
- Alyssa X, from whom I got the idea for video preview banners, although I opted to make them autoplay, instead of on mouseover, for mobile-friendliness
- Art Chaidarun, from whom I got the idea of masonry-style tiling, and I might potentially also do those cool stack filters
I began by adding the most important stuff for now, and might add some more over time. I keep pretty good notes of everything I do, so this list could become very very long, as I've worked on a lot of things over time. I realised that a few, cool, recent things are more meaningful than many, old, arbitrary things, so I'll try not to make this grid too large, and link to the full directory of projects (at least the ones that have made their way online) in the last tile.
It would have also been quite boring I think if I listed all my publications, as they're largely related. The same holds true for every weekend project, hackathon, game jam, utility script, game mod, etc. The projects I worked on during university I think are similarly just too old now. I also left out my volunteering work because it felt a bit too vain to include, and I'm not sure it would actually spur on any meaningful conversation. I also left out the things where I don't have significant enough involvement.
Please let me know your thoughts on the above and/or on how to improve this!
Bonsai diversification
My Red Maple and Wisteria seeds haven't sprouted yet, but I was left with all this extra soil! So I decided that I ought to plant the other species too. The remaining seeds I have are for Black Pine, Cherry Blossom, and Japanese Cedar. This is what they look like respectively:

I only had three Cherry Blossom seeds, and unlike the Red Maple, I decided to only plant one seed in that pot. Besides that, I've largely only used half of the seeds I have of each species so far, and I'm thinking that even that is unnecessary, but let's see!
As I was soaking them for 48 hours, they kind of got mixed up a bit, and I had a bit of a challenge separating the Black Pine from the Cherry Blossom, but I think I got there in the end. To better keep track of everything, as I was really starting to forget which is which, I put in some little wooden sticks:

The soil had dried quite a bit, so I made it wetter, maybe even a little too wet, as it was soaking the cotton on the bottom and created some condensation on the plastic. I also used tap water, which I didn't do for the first two, as it's pretty hard / rich in calcium. For my tomato plant, the effects of this were soon obvious as calcium residue was visible on the top of the soil and edges of the soil where it meets the pot. I didn't want to have the same for these plants, but it should hopefully all be OK.
If you'd like to learn some more about each species, here are their sections in my little book:


So now we have 5 different pots stratifying -- let's see which sprout first!
Bonsai sowing and stratification
My bonsai seeds have soaked for 48 hours and I'm ready to move on to the next step! The reveal: I picked Wisteria and Red Maple. They ticked all the right boxes for me as my first try.

The Wisteria seeds are the small ones and the Red Maple are the two big ones. I used half of the seeds that I had of each species.

I assembled the "Auto Irrigation Growing Pot" and tried to ignore the conflicting instructions. I think you're not meant to fill the reservoir with any water at all until after the Stratification step (which I'll explain in a sec), and it's ambiguous how deep the seeds should go beyond "same depth as the size" (the size of what, the seeds?), so I just used my best judgement.
It turns out that I actually have a lot of soil. I didn't even use up a full peat disc so far. I have three more pots, so I'm considering getting some more seedlings started in the meantime and increase the chances of success...
At any rate, I sowed the current seeds and sprinkled a tiny bit of water into the soil to keep it moist, as it had dried out a bit in the meantime. I don't think the instructions should have the soil bit as step 1 if you're then going to soak the seeds for 48 hours after that, it should really be the second step.

And now that they're sown, I put them in the fridge. In the fridge, the one on the left is the Red Maple (this is more of a note to myself -- I should label them really; there are little wooden sticks for that in the kit). Putting them in the fridge is the first part of the Stratification step, which is meant to simulate winter conditions, then spring, so that they can germinate as they would in nature.
I'll be checking on them every few days and keeping the soil damp. Hopefully in two or three weeks they will start sprouting and I can remove them from the fridge. I set some calendar events. So now we wait!
Banzai, bonsai!
I finally decided to start on my bonsai project. To read more about what this is all about, check out the project page. I haven't written anything about the tomato project, or any of the other (failed) horticulture projects, but I will eventually, since documenting failures is important too! This is the first log of what is probably going to be rather perennial chronicles.
The kit that I'm using to get a start with bonsai is really quite neat. It comes with 5 different species of seeds: Japanese Wisteria, Cherry Blossom, Japanese Cedar, Red Maple Tree, and Black Pine Tree.



This is a great set of tools in such a small package and I'm quite excited! The instruction booklet goes into a decent amount of detail, though I already know a bunch from YouTube and other places as I had a general interest in bonsai before deciding to try myself.
It came with two peat pucks that you put in some water and watch as they slowly grow while they absorb the water.

I decided to do both of them, as I wanted to try multiple species at the same time, and they grow to about 3x their original size! It's actually quite a lot of soil.

I then decided on two species that I wanted to grow. The next step was to put some of the seeds in warm water for 48 hours, such that they can soften, which makes it easier for the seedling to break through the shell. The two that I picked had seeds that looked very distinct from each other!
If you would like to know what species I picked, check back in 48 hours when I document the sowing process! I'll give you a hint: I didn't pick the mainstream choice (Black Pine).
Why certain GPT use cases can't work (yet)
Some weeks ago I built the "Muslim ChatGPT". From user feedback, I very quickly realised that this is one use case that absolutely won't work with generative AI. Thinking about it some more, I came to a soft conclusion that at the moment there are a set of use cases that are overall not well suited.
Verifiability
There's a class of computational problems with NP complexity. What this means is not important except that these are hard to solve but easy to verify. For example, it's hard to solve a Sudoku puzzle, but easy to check that it's correct.
Similarly, I think that there's a space of GPT use cases where the results can be verified with variable difficulty, and where having correct results is of variable importance. Here's an attempt to illustrate what some of these could be:

The top right here (high difficulty to verify, but important that the results are correct) is a "danger zone", and also where deen.ai lives. I think that as large language models become more reliable, the risks will be mitigated somewhat, but in general not enough, as they can still be confidently wrong.
In the bottom, the use cases are much less risky, because you can easily check them, but the product might still be pretty useless if the answers are consistently wrong. For example, we know that ChatGPT still tends to be pretty bad at maths and things that require multiple steps of thought, but crucially: we can tell.
The top left is kind of a weird area. I can't really think of use cases where the results are difficult to verify, but also you don't really care if they're super correct or not. The closest use case I could think of was just doing some exploratory research about a field you know nothing about, to make different parts of it more concrete, such that you can then go and google the right words to find out more from sources with high verifiability.
I think most viable use cases today live in the bottom and towards the left, but the most exciting use cases live in the top right.
Recall vs synthesis
Another important spectrum is when your use case relies on more on recall versus synthesis. Asking for the capital of France is recall, while generating a poem is synthesis. Generating a poem using the names of all cities in France is somewhere in between.
At the moment, LLMs are clearly better at synthesis than recall, and it makes sense when you consider how they work. Indeed, most of the downfalls come from when they're a bit too loose with making stuff up.
Personally, I think that recall use cases are very under-explored at the moment, and have a lot of potential. This contrast is painted quite well when comparing two recent posts on HN. The first is about someone who trained nanoGPT on their personal journal here and the output was not great. Similarly, Projects/amarbot used GPT-J fine-tuning and the results were also hit and miss.
The second uses GPT-3 Embeddings for searching a knowledge base, combined with completion to have a conversational interface with it here. This is brilliant! It solves the issues around needing the results to be as correct as possible, while still assisting you with them (e.g. if you wanted to ask for the nearest restaurants, they better actually exist)!
Somebody in the comments linked gpt_index so you can do this yourself, and I really think that this kind of architecture is the real magic dust that will revolutionise both search and discovery, and give search engines a run for their money.
Sanctum project and Christmas Giveaway
Welp, looks like I'm a month late for the N-O-D-E Christmas Giveaway. You might be thinking "duh, Christmas is long gone", and I also found it weird that the deadline was the 31st of January, but it turns out that that was a mistake in the video and he corrected it in the comments.

Since I keep up with YouTube via RSS, I didn't see that comment until it was too late. I only thought to check again when my submission email bounced.
Oh well! At least it gave me a reason to finally write up my smart home setup! This also wasn't the first time that participating in N-O-D-E events really didn't work out for me -- in 2018 I participated in the N-O-D-E Secret Santa and sent some goodies over to the US, and really put some effort into it I remember. Unfortunately I never got anything back which was a little disappointing, but hey, maybe next time!
Building a real-life Star Trek communicator
I've been planning to start this project for a while, as well as document the journey, but never really got around to it. I had a calendar reminder that tomorrow the N-O-D-E Christmas Giveaway closes, which finally gave me the kick in the butt needed to start this one! I also want to use this as an opportunity to create short-form videos on TikTok to learn more about it (in this case, documenting the journey). The project page is here.
ChatGPT as an Islamic scholar
Last weekend I built a small AI product: https://deen.ai. Over the course of the week I've been gathering feedback from friends and family (Muslim and non-Muslim). In the process I learned a bunch and made things that will be quite useful for future projects too. More info here!
Fine-tuning GPT-J online without spending a lot of money
Amarbot was using GPT-J (fine-tuned on my chat history) in order to talk like me. It's not easy to do this if you follow the instructions in the main repo, plus you need a beefy GPU. I managed to do my training in the cloud for quite cheap using Forefront. I had a few issues (some billing-related, some privacy-related) but it seems to be a small startup, and the founder himself helped me resolve these issues on Discord. As far as I could see, this was the cheapest and easiest way out there to train GPT-J models.
Unfortunately, they're shutting down.
As of today, their APIs are still running, but the founder says they're winding down as soon as they send all customers their requested checkpoints (still waiting for mine). This means Amarbot might not have AI responses for a while soon, until I find a different way to run the model.
As for fine-tuning, there no longer seems to be an easy way to do this (unless Forefront open sources their code, which they might, but even then someone has to host it). maybe#6742 on Discord has made a colab notebook that fine-tunes GPT-J in 8-bit and kindly sent it to me.
I've always thought that serverless GPUs would be the holy grail of the whole microservices paradigm, and it might be close, but hopefully that would make fine-tuning easy and accessible again.
Amarbot now has his own number
It's official — Amarbot has his own number. I did this because I was using him to send some monitoring messages to WhatsApp group chats, but since it was through my personal account, it would mark everything before those messages as read, even though I hadn't actually read them.
My phone allows me to have several separate instances of WhatsApp out of the box, so all I needed was another number. I went for Fanytel to get a virtual number and set up a second WhatsApp bridge for Matrix. Then I also put my profile picture through Stable Diffusion a few times to make him his own profile picture, and presto: Amarbot now has his own number!
In case the profile picture is not clear enough, the status message also says that he's not real. I have notifications turned off for this number, so if you interact with him, don't expect a human to ever reply!
Amarbot connected to WhatsApp
As of today, if you react to a message you send me on WhatsApp with a robot emoji (🤖), Amarbot will respond instead of me. As people in the past have complained about not knowing when I'm me and when I'm a bot, I added a very clear disclaimer to the bottom of all bot messages. This is also so I can filter them out later if/when I want to retrain the model (similar to how DALL-E 2 has the little rainbow watermark).
The reason I was able to get this to work quite easily is thanks to my existing Node-RED setup. I'll talk more about this in the future, but essentially I have my WhatsApp connected to Matrix, and Node-RED also connected to Matrix. I watch for message reactions but because those events don't tell you what the actual text of the message is that was reacted to was, only the ID, I store a small window of past messages to check against. Then I query the Amarbot worker with the body of that message and format and respond with the reply.

This integrates quite seamlessly with other existing logic I had, like what happens if you ask me to tell you a joke!
Amarbot trained on WhatsApp logs
Amarbot has been trained on the entirety of my WhatsApp chat logs since the beginning of 2016, which I think is when I first installed it. There are a handful of days of logs missing here and there as I've had mishaps with backing up and moving to new phones. It was challenging to extract my chat logs from my phone, so I wrote an article about this.