Log #writing
This page is a feed of all my #writing posts in reverse chronological order. It only includes posts with a timestamp (so e.g. not named "digital garden" pages or living documents). You can subscribe to this feed in your favourite feed reader through the icon above.
Everything here was written by me and me alone. Writing is a big part of my thinking process and these posts get published out of my internal writing. It's all organic; 0% AI assistance. Sometimes I will write about my experience using AI tools (e.g. to create a song or such) and in that case it will be very obvious in what I write that the attached media is made by AI.
![]()
Amar Memoranda > Log (writing)
 Yousef Amar
Yousef Amar
The direction of this blog
I just got back[1] from a stretch of travel (Germany, Greece), and thought that I would do some writing while I'm there. I didn't in the end. It seems like there are mainly two points of friction for me:
- My authoring tools/workflows still aren't that great, to where writing feels like a hassle
- I'm too concerned about privacy and general opsec, where "principle of least knowledge" clashes with writing openly for the public
I spend a lot of time communicating with people within my chat client. There are a lot of people I need to keep up with, so I've become quite efficient at it. It makes sense to incorporate writing blog posts into the same workflows. I intend to have Sentinel be my post poster. Maybe I write a message, tag it with some emoji reactions, and Sentinel takes it from there.
I did actually do quite a bit of writing since my last post, but for the second reason, I decided not to publish any of that. I might try to do so, but part of me would rather go fully stealth and cut off online presence where I can, and limit it where I can't (e.g. for work).
I wonder if there's a way to use LLMs to build "unit tests" for different personas reading my blog, every time I'm about to publish something. It could also try and make inferences from posts to mitigate against any future personas that I cannot yet predict. Maybe a tool like this could be useful for people who are not very politically well-versed and want make sure they don't make strong claims that could have them in hot water later.
For now maybe I'll simply go down my unpublished posts and reconsider publishing things I've already written. It helps me to write down complex thoughts to provide them with structure, and communicate them to others without rambling or getting lost. I do that over text too unfortunately, but even more when speaking! There is one post I plan to write like that soon.
As a rule of thumb, when I repeat myself more than twice on a topic (e.g. when explaining something to someone), I decide to write a post about it, as that's enough evidence for me that other people might benefit from it, and indeed I can send the next person to ask me the same question the post I have already written. There's a post like that coming soon too.
At least for those two types of posts I don't need to overthink much. I've also decided to start writing an autobiography, at different levels of granularity. I do not intend to publish this (maybe only individual anecdotes), but I think it will help me put my life in perspective and reflect on it. I tend to easily forget events as well, so it will help me remember.
I've also recently finished a huge migration from AWS to GCP. AWS has been my workhorse for over a decade, but has recently gotten too expensive, as the last of my AWS startup credits dried up. I have since founded another company that would be eligible for credits, but I can't redeem them on the same account either way, so a migration was inevitable. Why GCP? I have $350k of credits on there for the next two years. This website now lives on GCP too, which feels like a new beginning.
That's a lie; I got back around 2 weeks ago, wrote most of this post, didn't publish it. ↩︎
Blast from the past: "Cult II: Federal Crime"
Do you remember when you could get CD-ROMs with a ton of old games on them? A few months ago, I remembered playing one such game that was on one of those CDs. I can't 100% remember where I got it, but I was maybe around 10 years old, and my family was struggling financially. A family friend, Aunt Wafaa (who has since unfortunately passed of breast cancer), took me to a MediaMarkt (consumer electronics store) and said I can pick out any game for my birthday. I probably thought I could get 50 or 100 or however many were in that "collection" CD for the price of one.
What stuck with me about this particular game I remembered was the soundtrack. They were all MIDI tracks, and I could remember every note. For the life of me, I couldn't remember the name of this game, but I found a subreddit called /r/tipofmyjoystick where you can post about games you don't remember the name of, and very often the community manages to find it. Indeed, when I made a post titled [PC][00s]Top-down rpg/puzzle game, Reddit user Vellidragon cracked it in no time! Here is my post (warning: spoilers marked in the description):
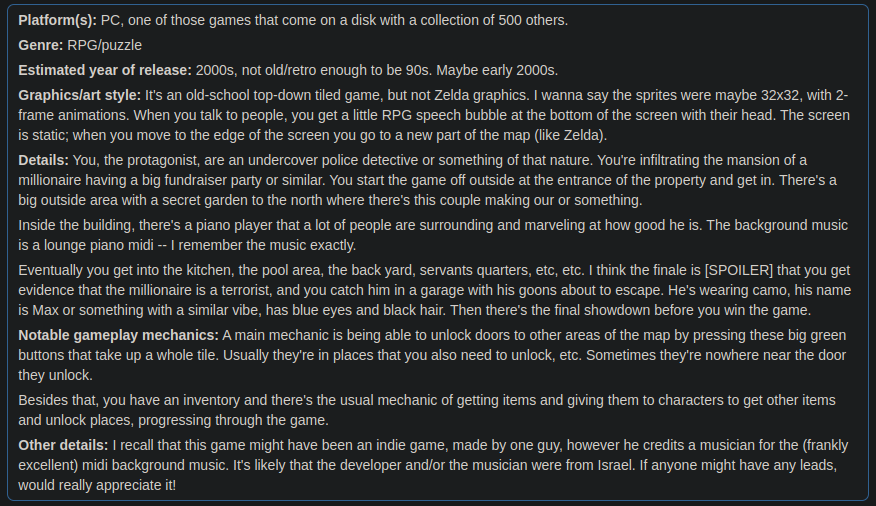
I asked him how he knew, and he said:
I had the first Cult on a shareware CD way back, wondered if that could be it but found videos of the sequel when searching and realised it must be that.
I was delighted to have found it again and after some digging, found that the original website was still up, and you could still download the game for free from there. I also read that there might be an Android port now, but I couldn't quite find it. I was also surprised to find that the website contained a stitched-together map of the game (warning: contains spoilers), a view I had never seen before.
I decided to play through the game once more. I did so in three or four sessions together with Veronica. I only remembered bits and pieces about the plot so it was as if I had never played it before. Truly a blast from the past.
I also remembered the frustrating bits that time had softened my memory of. This was a typical adventure RPG of the time, where you talk to NPCs who you do small tasks for that may give you items that you then use for other tasks etc. One annoying mechanic however was the way that the progression was controlled using doors and switches. Sometimes doors are opened by NPCs and it's obvious where you need to go, but other times a switch you press opens a door on the other side of the map, with no logical connection, so you spend a lot of time running around the map checking if any new doors have opened. It's easy to get stuck and either have to scroll through the walkthroughs, or try to use every item in your inventory on every character in the off chance that it does something.
Anyway, after replaying the game, I took another look at that map. I couldn't quite put the feeling to words. It's like visiting a familiar place that you've moved on from, but with completely new eyes. It somehow contains this whole world that I spent hours in, in a single picture. It also makes me want to build my own worlds in this way, where the individual components are so simple, but the emergent complexity and richness of the stories within stick with you for decades.
Thoughts on chat as an interface
Chat as an interface has always been something I thought about a lot. After all, it's a close analogue to spoken conversation, our most natural form of communication.
The most basic chat interface is an input box and a chronological history of messages, so you can follow the conversation. Messages are often augmented with emojis etc to fill in the gaps for intonation and body language. If you need higher communication bandwidth, voice messages do it sometimes too. Advantages over face-to-face conversation is that text-based conversations have the option of being asynchronous and much longer-lived, potentially even pen-pal style correspondences.
Group conversations
The moment you start thinking about group conversations, some problems begin to be unearthed. One problem is it can get quite crowded, as you're sharing a linear chat history. It's hard to follow multiple threads of conversation that have been flattened into one, when in real life conversations can branch off and diverge.
This is a problem in video conferences too. While at a social event, groups naturally divide into smaller clusters of people in their own bubble of conversation, this has to be done explicitly in video conferences through breakout rooms and similar mechanics. Otherwise all the attention and spotlight is aimed at the person currently talking, which can throw off the dynamics.
I first noticed this phenomenon when I was running the Duolingo German language events in London. It's already common for people who don't know the language well to be shy about speaking up, but when covid started and we switched to Zoom, it was very easy for whomever is speaking to get stage fright, even if they're not normally shy. What then ends up happening is that two or three people will engage in conversation while the rest watch, unless the host (me in that case) takes control of the group dynamics. This was much easier to do in-person, especially where I could see the person's face and gauge how comfortable they are, so I don't put them on the spot (e.g. by bringing them into the conversation with simple yes/no questions).
Attempts at solutions
Anyway, during covid I became quite interested in products that try to solve these problems by capturing aspects of real-life communication through product design. I remember imagining a 2D virtual environment with spatial audio in the context of my PhD research. It turned out somebody was already building something similar: a fellow named Almas, and I remember having a call with him about SpatialChat (a conversation full of lovely StarCraft metaphors). This was an environment that allowed you to replicate the act of physically leaving a huddle and moving to a different cluster to talk. You could only be heard by those in "earshot".
A 2D game called Manyland did something similar with text-only, where text would appear above the head of your character as you were typing. This created interesting new dynamics and etiquette around "interrupting" each other, as well as things like awkward silences, which don't exist when you're waiting for someone to type. There was even an odd fashion around typing speed at one point.
Interestingly, you're not occupying space in the chat log by chatting; you're filling the space above your head, so you just need to find a good place to perch. Two people can respond to the same thing at the same time. However, one person can't quite multi-task their responses / threads without jumping back and forth between people, but after all that's how it works in real life too, no?
Reply chains and threads
I won't go over the history of different chat platforms and apps, but we've seen a lot of patterns that try and create some structure around communication, here in order from more ephemeral to less ephemeral:
- Quoting a message to reply to inline
- Ad-hoc threads that create a separated chat log
- More permanent threads akin to forums
- Permanent "topic" channels
I like to imagine conversations as trees, where branches can sprout and end just as fast. Have you ever been in an argument where someone rattles off a bunch of bad points, but you can only counter them in series? Each of your responses may in turn trigger several additional responses, and you get this exponentially growing tree and eventually you're writing essays dismantling every point one by one.
In real life, it's often hard to remember everything that was said, so you focus on just the most important parts. Or you deliberately prune the branches to the conversation doesn't become unwieldy. Some people like to muddy the waters and go off topic and it's up to you to steer the conversation back to the main trunk.
But not everything is a debate. A friend of mine figured that this tree, in 2D, ought to be the way to hold conversations. Big big internet conversations (he used social media as an example) are all adding nodes to far off branches of a huge tree. I quite like that picture. It would certainly allow for conversations to happen in parallel at the same time as you can hop back and forth between branches.
ChatGPT and the history tree
ChatGPT made the choice that chats should be linear, but you can start a new chat with a new instance of the AI at any time, and go back to old chats through the history tab. This seems to make sense for chatting with an AI assistant, but an anti-pattern emerges...
Have you ever gone down a conversation with ChatGPT only to realise that it's dug itself into a hole, so you scroll up to just after the last "good" message and edit the message to create a new, better timeline? I do this a lot, and it reminded me of undo/redo in text editors.
Undo and redo are normally linear, and if you go back in time and make a change, suddenly the old "future" is no longer accessible to you. We've all done it where we accidentally typed something after pressing undo a bunch of times to check a past version, losing our work.
Someone made a plugin for vim that allows you to navigate a tree of timelines that you create by undo-ing, sort of like automatic git branching and checkout. I feel like this ought to be a UI for interacting with ChatGPT too! Already this is being used for better responses and I feel like there must have been attempts at creating a UI like this, but I haven't seen one that does this elegantly.
Conclusion
This has been kind of a stream of though post, inspired by my post on resetting my AI assistant's chat memory, so I'm not entirely sure what the point I'm trying to make is. I think I'm mainly trying to narrow down the ergonomics of an ideal chat interface or chat in a virtual environment.
I think you would probably have some set of "seed" nodes -- the stem cells to your threads -- which are defined by individuals (i.e. DMs), or groups with a commonality, or topics. These would somehow all capture the nuances of real-life communication, but improve on that with the ability to optionally create ephemeral threads out of reply branches. I'm not yet sure what the UI would physically look like though.
Why no Indieweb Carnival posts?
I've been participating in the Indieweb Carnival for a while. Usually I'll take the themes on by freewriting. These past two months, for the themes Self-Care and Routine and Community and belonging, I wrote approx 2000 words each, but I never published these.
The themes are often deep and elicit introspection and vulnerability, especially these past two. I tend to knock them out on long train rides or flights where I'm offline (most recently for the ones for Oct, Nov, Dec: Birmingham, Manchester, Cairo, Ismailia, Riyadh). While tackling these themes is a useful exercise for me, I realised that sharing the output with the public is not.
Prior to the past two themes, I published my Indieweb Carnival writing, but I had them unlisted on my website. You can only read them via webmention links or if they're linked to by Indieweb Carnival organisers. The reason for this is that it's not unusual that I write about something personal, and the target reader in my mind is a complete stranger. I'm oddly ok with sharing certain things with strangers, but the issue is that not only strangers visit my website.
Sometimes I will reread what I wrote, but imagine a different persona reading. I'm comfortable sharing different things with different people, e.g. family, friends, colleagues, clients, etc. These categories are not "nested" in the sense that my inner circle ought to have access to everything, with permissions tightening as you move out the circles. Instead, these are usually non-overlapping and dependent on the content itself.
When I re-read something from the perspective of a different group, or even individual, inevitably I will want to modify what I wrote. The more I share, the harder it is to juggle these personas in my mind and release something that I'm happy sharing with the widest group of all: everyone.
For the past two topics, I found that I went deep enough that I could no longer imagine what future inference could be made from that personal information, who may read this one day after I've forgotten about it or have changed my mind on what I wrote, and how the current people in my life may view these things.
In short: the less I think about what I write, the more I overthink who reads, and vice versa. That's no good if you want to freewrite. So I decided to stop publishing these posts. Or rather, restricting them to an audience of one: me[1].
I suppose my website might be a little less colourful as a result, but maybe one day I can figure out some kind of access control system, or create a new identity separate from my main one.
This is not the most restrictive audience, since I assume that anything I write may possibly one day be read by others (e.g. though a data breach), and I also draw a distinction between different versions of myself across time, and AI (think Roko's Basilisk), but that's a topic for another time. ↩︎
Aged-out bookmarks
I'm in the process of organising a big pile of bookmarks, the current batch dating to 2019. I realised that while the ones from 2022 are still relevant, I really don't know why I bookmarked some of the things that I did in 2019. Some of them are kind of interesting articles, but I no longer remember what my intention was.
Was it to read them later? I think they're mostly just not that interesting to me anymore. Was it to do use them somehow or keep them as a resource? If so, I don't see how, as they've usually lost their relevance.
I have already noticed that the rate at which I bookmark links is much higher than the rate at which I triage them. Part of this is because the triage process is still too high-friction for me. Most of the time, I want to be able to very easily categorise and store a resource in the right place for later search, or append it to the scratch file of a relevant project.
I always knew that I need to take measures to ensure that the "service rate" of these lists is higher than the rate at which they grow, but now I also think that there's a certain time cutoff after which the lists might as well be self-pruning. After all, if something's been in the "backlog" for so long, surely it can't be that important? I need a Stale Bot for bookmarks!
A little CSS trick for editing text
I wrote a short article about a trick for editing the text in HTML text nodes with only CSS. This is one of those articles where the goal is just to share something that I learned or discovered, that someone might benefit from, and the primary mode of finding this content is through a search engine.
It doesn't quite make sense for this to be an "article" in the way that I use that word (a long-form post bound in time that people follow/subscribe to) so I might eventually turn all these guide-type posts into wiki-notes, so they can exist as non-time-bound living documents.
Chatting with yourself for introspection
For a long time I've been interested in the idea of creating a digital twin of yourself. I've tried this in the past with prompt completion trained on many years of my chat data, but it was always just a bit too inaccurate and hollow.
I also take a lot of notes, and have been taking more and more recently (a subset of these are public, like this post you're reading right now). I mentioned recently that I really think that prompt completion on top of embeddings is going to be a game-changer here.
You probably already know about prompt completion (you give it some text and it continues it like auto-complete on steroids) which underpins GPT-3, ChatGPT, etc. However, it turns out that a lot of people aren't familiar with embeddings. In a nutshell, you can turn blocks of text into high-dimensional vectors. You can then do interesting things in this vector space, for example find the distance between two vectors to reason about their similarity. CohereAI wrote an ELI5 thread about embeddings if you want to learn more.
None of this is particularly new -- you might remember StyleGAN some years ago which is what first really made this concept of a latent space really click for me, because it's so visual. You could generate a random vector that can get decoded to a random face or other random things, and you could "morph" between faces in this space by moving in this high-dimensional space. You could also find "directions" in this space (think PCA), to e.g. make a slider that increases your age when you move in that direction, while keeping other features relatively unchanging, or you could find the "femininity" direction and make someone masculine look more feminine, or a "smiling amount" direction, etc.
The equivalent of embedding text into a latent space is like when you have an image and you want to hill-climb to find a vector that generates the closest possible image to that (that you can then manipulate). I experimented with this using my profile picture (this was in August 2021, things have gotten much better since!):
Today, I discovered two new projects in this space. The first was specifically for using embeddings for search which is not that interesting but, to be fair, is what it's for. In the comments of that project on HackerNews, the second project was posted by its creator which goes a step further and puts a chat interface on top of the search, which is the exact approach I talked about before and think has a lot of potential!
Soon, I would like to be able to have a conversation with myself to organise my thoughts and maybe even engage in some self-therapy. If the conversational part of the pipeline was also fine-tuned on personal data, this could be the true starting point to creating digital twins that replace us and even outlive us!
Collaborative editing on wiki notes
Adding little diagrams to my posts
In my previous post I made a little block diagram. Here's the workflow for how I did that: https://yousefamar.com/memo/articles/writing/graphviz/
I have a newsletter now
If you happen to have checked my main feed page in the past few days, you might have notice I've added a box to subscribe to a newsletter. This is meant to be a weekly digest of the posts I make the week before, delivered to your email inbox.
I think I'm getting close to figuring out a good system for content pipelines, though I still think about it a lot. As such, this newsletter part will mostly be an experiment for now. It won't be an automated email that summarises my posts, but rather I'm going to write it myself to begin with. I'd like to follow a style like the TLDR newsletter, which I've been following since they launched. This means e.g. a summary of cool products I might have bookmarked throughout the week, which might also give me the opportunity/excuse to review and organise them.
I'm not convinced that the medium of newsletters is the right way to consume content. I for one am a religious user of kill-the-newsletter to turn newsletters into Atom feeds. A lot of people consume content via their email inboxes though, and it seems easier to go from that to the feed format, rather than the other way around at the moment. At any rate, I want to create these various ways of consuming content. The pipeline for this content might look like this:

The other consideration is visibility of my audience. I don't actually know if anyone reads what I write unless they tell me (hi James!), and unless I put tracking pixels and such in my posts, but is it really that important? With email, you have a list of subscribers, which probably gives you slightly more data over feed readers polling for updates to your feed, but again, I don't really want to be responsible for a list of emails, and I don't like being at the mercy of the big email providers' spam filters if I want to send email from my own domain (yes, this is despite SPF/DKIM and all that, based on some voodoo you can still reach people's junk folder).
So I'm thinking for now I probably don't even really care who reads what I write, and if it becomes relevant (e.g. if I want to find out what people would like to see more of), I can publish a poll.
The implications of Bing adding ChatGPT to search
Not too long ago I mentioned that the search engines will need to add ChatGPT-like functionality in order to stay relevant, that there's already a browser extension that does this for Google, and that Google has declared code red. Right on schedule, yesterday Microsoft announced that they're adding ChatGPT to Bing. (If you're not aware, Microsoft is a 10-figure investor in OpenAI, and OpenAI has granted an exclusive license to Microsoft, but let's not get into how "open" OpenAI is).
I heard about this via this HackerNews post and someone in the comments (can't find it now) was saying that this will kill original content as we know it because traffic won't go to people's websites anymore. After all, why click through to websites, all with different UIs and trackers and ads, when the chat bot can just give you the answers you're looking for as it's already scraped all that content. To be honest, if this were the case, I'm not so sure if it's such a bad thing. Let me explain!
First of all, have you seen the first page of Google these days? It's all listicles, content marketing, and SEO hacks. I was not surprised to hear that more and more people use TikTok as a search engine. I personally add "site:reddit.com" to my searches when I'm trying to compare products for example, to try and get some kind of real human opinions, but even that might not be viable soon. You just can't easily find what you need anymore these days without wading through ads and spam.
Monetising content through ads never really seemed like the correct approach to me (and I'm not just saying that as a consistent user of extensions that block ads and skip sponsored segments in YouTube videos). It reminds me a lot of The Fable of the Dragon-Tyrant. I recommend reading it as it's a useful metaphor, and here's why it reminds me (skip the rest of this paragraph if you don't want spoilers): there's a dragon that needs to be fed humans or it would kill everyone. Entire industries spring up around the efficient feeding of the dragon. When humans finally figured out how to kill it, there was huge resistance, as among other things, "[t]he dragon-administration provided many jobs that would be lost if the dragon was slaughtered".
I feel like content creators should not have to rely on ads in the first place in order to be able to create that content. I couldn't tell you what the ideal model is, but I really prefer the Patreon kind of model, which goes back to the ancient world through art patronage. While this doesn't make as much money as ads, I feel like there will come a point where creating content and expressing yourself is so much easier/cheaper/faster than it is today, that you won't have high costs to maintain it on average (just look at TikTok). From the other side, I feel like discovery will become so smooth and accurate, that all you need to do is create something genuinely in demand and it will be discovered on its own, without trying to employ growth hacks and shouting louder than others. I think this will have the effect that attention will not be such a fiery commodity. People will create art primarily for the sake of art, and not to make money. Companies will create good products, rather than try to market worthless cruft. At least that's my ideal world.
So how does ChatGPT as a search engine affect this? I would say that this should not affect any kinds of social communication. I don't just mean social media, but also a large subset of blogs and similar. I think people will continue to want to follow other people, even the Twitter influencer that posts business tips, rather than ask ChatGPT "give me the top 5 business tips". I believe this for one important reason: search and discovery are two different things. With search, there is intent: I know what I don't know, and I'm trying to find out. With discovery, there isn't: I don't know what I don't know, but I loiter in places where things I would find interesting might appear, and stumble upon them by chance.
Then there's the big question of having a "knowledge engine" skipping the sources. Let's ignore the problem of inaccurate information[1] for now. I would say that disseminating knowledge at the moment is an unsolved problem, even through peer-reviewed, scientific journal papers and conference proceedings (this is a whole different topic that I might write about some day, but I don't think it's a controversial view that peer-review and scientific publishing is very, very broken).
I do not believe that the inability to trace the source of a certain bit of knowledge is necessarily the problem. I also don't believe that it's necessarily impossible, but lets pretend that it is. It would be very silly I think to cite ChatGPT for some fact. I would bet that you could actually get a list of references to any argument you like ("Hey ChatGPT, give me 10 journal citations that climate change is not man-made").
I think the biggest use cases of ChatGPT will be to search for narrowly defined information ("what is the ffmpeg command to scale a video to 16:9?") and discover information and vocabulary on topics that you know little about in order to get a broad overview of a certain landscape.
However, I don't see ChatGPT-powered search killing informative articles written by humans. I see AI-generated articles killing articles generated by humans. "Killing" in the sense that they will be very difficult to find. And hey, if ChatGPT could actually do serious research, making novel contributions to the state-of-the-art, while citing prior work, then why shouldn't that work be of equal or greater value to the human equivalent?
In the case of AI-generated garbage drowning out good human articles just by sheer quantity though, what's the solution? I think there are a number of things that would help:
- Being able to trace sources and build trust metrics for specific sources. The consumer of the content of course wouldn't want to check every source, but they can trust that the reputable journalist or tech reviewer did their due diligence.
- Collaborative curation: wikis (and Wikipedia itself) having transparent and well-enforced moderation. ChatGPT can be trained on this information, but if a concept surfaces in a chat, it can always be looked up in this structured repository of information. This will ideally be as objective as possible, so where you would have usually looked at a "Jira vs Linear" article and wonder which one of those two organisations wrote it, a lot more energy will be aimed at these "comparison of project management software" tables on Wikipedia, with a higher degree of accountability.
- For things that aren't general knowledge (e.g. let's say you wanted to document a personal project), to have some set standards in order to contribute this information to a bigger collection of federated knowledge. No, I'm not just reinventing the internet, think more of a federated wiki that's marked up and structured in such a way that indexing/search is much less data-miney and prone to SEO tricks. A truly collaborative digital garden.
Overall I think that ChatGPT as the default means of finding information is a net positive thing and may kill business models that were flawed from the start, making way for something better.
I've had this problem with normal Google before (the information cards that try to answer your questions). For a long time (even after I reported it), if you searched something like "webrtc connection limit", you would get the wrong answer. Google got this answer from a StackOverflow answer that was a complete guess as far as I could tell. Fortunately, the person who asked the question eventually marked my answer as the correct one (it already had 3x more upvotes than the wrong one) although the new answer never showed up in a Google search card as far as I can tell. ↩︎
Obsidian Canvas
Obsidian Canvas was released today and I find this very exciting! As you might know, I'm a very visual thinker and try to organise my thoughts in ways that are more intuitive to me. I've always thought that an infinite canvas that you can place nested collapsible components and primitives on makes much more sense than a directory tree. I've used other tools for this, but the separation from my PKM tool (Obsidian) has always been a big barrier.
Obsidian keeps getting better over time! It seems the canvas format is relatively simple, where I reckon I could have these be publishable. More importantly though, I think it would be quite useful to organise my thoughts internally. Currently I use a combination of whiteboard wallpaper, actual paper, and Samsung Notes on my S22 Ultra; the only not-bad Android note-taking app with good stylus support, but frustratingly it doesn't let you scroll the page infinitely in the horizontal direction!
It can be a bit frustrating to try and manipulate a canvas without over-reliance on a mouse, but I don't think there are any ergonomic ways to interact well with these besides a touch screen, and at least the keyboard shortcuts for Canvas seem good. When AR becomes low-friction, I hope to very soon be able to use 3D spaces to organise documents and assets, in a true mind palace. For now, Obsidian Canvas will do nicely though!