Log #dev
This page is a feed of all my #dev posts in reverse chronological order. It only includes posts with a timestamp (so e.g. not named "digital garden" pages or living documents). You can subscribe to this feed in your favourite feed reader through the icon above.
Everything here was written by me and me alone. Writing is a big part of my thinking process and these posts get published out of my internal writing. It's all organic; 0% AI assistance. Sometimes I will write about my experience using AI tools (e.g. to create a song or such) and in that case it will be very obvious in what I write that the attached media is made by AI.
![]()
Amar Memoranda > Log (dev)
 Yousef Amar
Yousef Amar
Thoughts on the future of software
The way I like to speculate about the future of software is by imagining that you have infinite engineering resources. The other day, someone mentioned that they don't want to try PicoClaw (or any of the other spin-offs) because they'll miss out on cool features of the biggest project with the most contributions.
My uncontroversial prediction is that there will be a lot more hyper-personalised software, even products for single users, because that problem will go away. Agents will watch other projects for updates, or the internet for cool ideas, and instantly implement them. Commercial software in competitive spaces will quickly reach feature-parity and stay there, and it'll be harder to differentiate.
A lot of open source software today struggles because the commercial models around them don't work. People can donate money to the developers sometimes (very little in practice) or their time through contributions. A lot of open source software stalls and dies.
With infinite engineering resource, even if it's not completely free, there may be a commercial model where people share the token costs, instead of paying a subscription for a product. Then as long as people keep contributing, features keep getting developed. The more users a product has, the cheaper it becomes to develop.
The downside is there will be a pressure not to fork that software, because the userbase gets reset to 1. It's open source, but instead of donating to devs, or donating your time, you're donating tokens. But if you fork because the maintainers don't like your feature suggestion, and you want it anyway, suddenly you (or rather your agents) have to maintain that fork.
However, I suspect that this will become extremely cheap, in the same way that storage has become cheap. Cost will not be the bottleneck -- you'll be able to clear your product backlog faster than you can fill it. So the asymptote here is that there just won't be any maintainers anymore except your agents, making you your own personal software suite.
My hope is that there will be better interoperation between all this sprawl of software. It's hard to predict as I think the interfaces will change drastically (especially agent-to-agent communication). Collaborative software or social media may be the last to go, as they still have reasons for being unified (technical, or because of network effects and intentional walled-garden-ness).
Data is the only real moat left for SaaS founders. Speaking of data, I think data brokers are in big trouble if everyone starts building their own consumer apps. I would say this is overall a good thing.
How I almost worked at Google
As I was sorting through some old bookmarks, I remembered a fun thing that happened over a decade ago now. I was doing some programming and searching some technical things online as I was debugging something, and suddenly the results page of Google tipped back and in the opening there was some text on a dark background that said "You're speaking our language. Up for a challenge?".
I clicked it and it took me to a terminal where I had to solve a series of leetcode-style puzzles. While I'm not a fan of those sorts of questions, I really enjoy Alternate Reality Games (ARGs) and Capture the Flag (CTFs), so this was really up my alley. As you progressed through the levels, the puzzles got harder and harder, eventually having time limits in days rather than minutes or hours. I remember feeling quite proud by figuring out "ah, they want me to use dynamic programming here", etc.
After level 5 if I remember correctly, it asks you for your contact details. I put those in and carried on. Eventually, I got to maybe level 8, and the problem was quite long, and I had a life to get back to, so I let it lapse. I eventually found out that this was also a promotion for the new (at the time) movie called The Imitation Game.
Not long after, I was reached out to by a headhunter from Google. Anyone who knows me knows that I would never in a million years work at Google (or any big tech company for that matter). However, at the time (approx 2014), I didn't really know what I wanted to do. So I ended up interviewing for a SE role at Google.
I remember being surprised at how low-tech their process was -- the tech interview was me on the phone with the interviewer (actual phone, not Skype) and typing code into a Google Doc. I remember it took me a while to figure out the answer to another leetcode-like question about normalising strings and searching through them or something. I called a friend afterwards who actually studied CS (unlike me) and told him about it, and he got the answer instantly.
Eventually, I had a choice between either that or pursuing a PhD. I picked doing a PhD. Sometimes I wonder where my life would be had I started working in industry instead. I know now that I would not have enjoyed working at Google, but then again, I really did not enjoy my PhD! So that's the story how I was almost started a career in big tech.
The link (https://foobar.withgoogle.com/) is no longer active and redirects to Google's jobs page, however something similar seems to live at https://h4ck1ng.google/, though that looks very different to what I remember. It still has a similar vibe though!
Build smaller agents that ask for help
Disclaimer: I originally wrote this post a few months ago on a flight, and decided not to publish it at the time. I did so as I have a rule that when 3 or more people ask me the same question, I write my answer down. I changed my mind now and decided to publish, but things move fast in this space, so bear that in mind.
More and more the topic of Agents with unlimited tools comes up. It came up again as Anthropic is trying to set a standard for interfaces to tools through MCP. It has come up enough times now that I thought I'd write down my thoughts, so I can send this to people the next time it comes up. I actually think MCP is quite a badly designed protocol, but this post will not be about that. Instead, we'll go a bit more high-level.
What is an agent?
In the context of LLMs, it's a prompt or loop of prompts with access to tools (e.g. a function that checks the weather). Usually this looping is to give it a way to reason about what tools to use and continue acting based on the results of these tools.
I would therefore break down the things an agent needs to be able to do into 3+1 steps:
- Reason about which tools to use given a task
- Reason about what parameters to pass to those tools
- Call the tools with those parameters and optionally splice the results into the prompt or follow-up prompt
- Rinse and repeat for as many times as are necessary
For example, agent might have access to a weather function, a contact list function, and an email function. I ask "send today's weather to Bob". It reasons that it must first query the weather and the contact list, then using the results from those, it calls the email function with a generated message.
Why can't this scale?
The short answer is: step #1. A human analogue might be analysis paralysis. If you have one tool, you only need to decide if you should use it or not (let's ignore repeat usage of the same tool or else the possible combinations are infinite). If you have two, that decision is A, B, AB, BA. The combinations explode factorially as the number of tools increase.
Another analogue is Chekhov's gun. This is sort of like the reverse of the saying "if all you have is a hammer, everything looks like a nail". Agents have a proclivity to use certain tools by virtue of their mere existence. Have you ever had to ask GPT to do something but "do not search the internet"? Then you'll know what I mean.
Not to mention the huge attack surface you create with big tool libraries and data sources through indirect prompt injection and other means. These attacks are impossible to stop except with the brute force of very large eval datasets.
A common approach to mitigate these issues is to first have a step where you filter for only the relevant tools for a task (this can be an embedding search) and then give the agent access to only a subset of those tools. It's like composing a specialist agent on the fly.
This is not how humans think. Humans break tasks down into more and more granular nested pieces. Their functions unfold to include even more reasoning and even more functions; they don't start at the "leaf" of the reasoning tree. You don't assemble your final sculpture from individual Legos, you perform a functional decomposition first.
Not just that, but you're constraining any creativity in the reasoning of how to handle a task. There's also more that can go wrong -- how do I know that my tool search pass for the above query will bring back the contacts list tool? I would need to annotate my tools with information on possible use cases that I might not yet know about, or generate hypothetical tools (cf HyDE) to try and improve the search.
How can I possibly know that my weather querying tool could be part of not just a bigger orchestra, but potentially completely different symphonies? It could be part of a shipment planning task (itself part of a bigger task) or making a sales email start with "Hope you're enjoying the nice weather in Brighton!". Perhaps both of these are simultaneously used in an "increase revenue" task.
Let's take a step back...
Why would you even want these agents with unlimited tools in the first place? People will say it's so that their agents can be smarter and do more. But what do they actually want them to do?
The crux of the issue is in the generality of the task, not the reasoning of which tools help you achieve that task. Agents that perform better (not that any are that good mind you) will have more prompting to break down the problem into simpler ones (incl CoT) and create a high level strategy.
Agents that perform the best are specialised to a very narrow task. Just like in a business, a generalist solo founder might be able to do ok at most business functions, but really you want a team that can specialise and complement each other.
What then?
Agents with access to infinite tools are hard to evaluate and therefore hard to improve. Specialist agents are not. In many cases, these agents could be mostly traditional software, with the LLM merely deciding if a single function should be called or not, and with what parameters.
There's a much more intuitive affordance here that we can use: the hierarchical organisation! What does a CEO do when they want a product built? They communicate with their Head of Product and Head of Engineering perhaps. They do not need to think about any fundamental functions like writing some code. Even the Head of Engineering will delegate to someone else who decomposes the problem down further and further.
The number of decisions that one person needs to make is constrained quite naturally, just as it is for agents. You can't have a completely flat company with thousands of employees that you pick a few out ad-hoc for any given task.
Why is this easier?
The hardest part about building complicated automation with AI is defining what right and wrong behaviour is. With LLMs, this can sometimes come down to the right prompt. Writing the playbook for how a Head of Engineering should behave is much easier if you ask a human Head of Engineering, than it is to define the behaviour of this omniscient octopus agent with access to every tool. Who're you going to ask, God?
The administration or routing job should be separate from the executor job. It's a different task so should have its own agent. This is kind of similar to a level down with Mixture of Experts models -- there's a gate network or router that is responsible for figuring out which tokens go to which expert. So why don't we do something similar at the agent level? Why go for a single omniscient expert?
What if you're building a fusion reactor?
You cannot build a particle physicists agent without an actual particle physicist to align it. So what do you do? Why would a particle physicist come to you, help you build this agent, and make themselves redundant?
They don't need to! Just as when you hire someone, you don't suddenly own their brain, similarly the physicist can encode their knowledge into an agent (or system of agents) and your organisation can hire them. They own their IP.
At an architectural level, these agents are inserted at the right layer of your organisation and speak the same language on this inter-agent message bus.
The language: plain text
We've established why Anthropic has got it wrong. A Zapier/Fivetran for tools is useless. That's not the hard part. Interface standards should not be at the function level, but at the communication level. And what better standard than plain text? That's what the LLMs are good at, natural language! What does this remind you of? The Unix Philosophy!
Write programs that do one thing and do it well. Write programs to work together. Write programs that handle text streams, because that is a universal interface.
How about we replace "programs" with "agents"? And guess what: humans are compatible with plain text too! An agent can send a plain text chat message, email, or dashboard notification to a human just as it can another agent. So that physicist could totally be a human in an AI world. Or perhaps the AI wants to hire a captcha solver? Let's leave that decision to our Recruiter agent -- it was aligned by a human recruiter so it knows what it's doing.
A society of agents
I'm not about to suggest that we take the hierarchy all the way up to President. Rather, I think there's an interesting space, similar to the "labour pool" above, for autonomous B2B commerce between agents. I haven't been able to get this idea out of my head ever since I read Accelerando, one of the few fiction books I've read several times. In it, you have autonomous corporations performing complicated manoeuvres at the speed of light.
I can see a glimpse of this at the global "message bus" layer of interaction above the top-level agent, with other top-level agents. If you blur the lines between employment and professional services, you can imagine a supplier sitting in your org chart, or you can imagine them external to your org, with a contact person communicating with them (again, not by API but by e.g. email).
Conclusion
For this space of general tasks like "build me a profitable business", the biggest problem an agent faces is the "how". The quality of the reasoning degrades as the tasks become broader. By allowing as many agents as needed to break the problem down for us, we limit the amount of reasoning an agent needs to do at any given point. This is why we should anthropomorphise AI agents more -- they're like us!
Pixie: Entry to Mistral x a16z Hackathon
This post documents my participation in a hackathon 2 weeks ago. I started writing this a week ago and finished it now, so it's a little mixed. Scroll to the bottom for the final result!
Rowan reached out asking if I'm going to the hackathon, and I wasn't sure which one he meant. Although I submitted a project to the recent Gemini hackathon, it was more of an excuse to migrate an expensive GPT-based project ($100s per month) to Gemini (worse, but I had free credits). I never really join these things to actually compete, and there was no chance a project like that could win anyway. What's the opposite of a shoo-in? A shoo-out?
So it turns out Rowan meant the Mistral x a16z hackathon. This was more of a traditional "weekend crunch" type of hackathon. I felt like my days of pizza and redbull all-nighters are long in the past by at least a decade, but I thought it might be fun to check out that scene and work on something with Rowan and Nour. It also looked like a lot of people I know are going. So we applied and got accepted. It seems like this is another one where they only let seasoned developers in, as some of my less technical friends told me they did not get in.
Anyway, we rock up there with zero clue on what to build. Rowan wants to win, so is strategising on how we can optimise by the judging criteria, researching the background of the judges (that we know about), and using the sponsors' tech. I nabbed us a really nice corner in the "Monitor Room" and we spent a bit of time snacking and chatting to people. The monitors weren't that great for working (TV monitors, awful latency) but the area was nice.
Since my backup was a pair of XReal glasses, a lot of people approached me out of curiosity, and I spent a lot of time chatting about the ergonomics of it, instead of hacking. I also ran into friends I didn't know would be there: Martin (Krew CTO and winner of the Anthropic hackathon) was there, but not working on anything, just chilling. He intro'd me to some other people. Rod (AI professor / influencer, Cura advisor) was also there to document and filmed us with a small, really intriguing looking camera.
We eventually landed on gamifying drug discovery. I should caveat that what we planned to build (and eventually built) has very little scientific merit, but that's the goal of a hackathon; you're building for the sake of building and learning new tools etc. Roughly-speaking, we split up the work as follows: I built the model and some endpoints (and integrated a lib for visualising molecules), Nour did the heavy-lifting on frontend and deploying, and Rowan did product design, demo video, pitch, anything involving comms (including getting us SSH access to a server with a nice and roomy H100), and also integrated the Brave API to get info about a molecule (Brave was one of the sponsors).
You're probably wondering what we actually built though. Well, after some false starts around looking at protein folding, I did some quick research on drug discovery (aided by some coincidental prior knowledge I had about this space). There's a string format for representing molecules called SMILES which is pretty human-readable and pervasive. I downloaded a dataset of 16k drug molecules, and bodged together a model that will generate new ones. It's just multi-shot (no fine-tuning, even though the judges might have been looking for that, as I was pretty certain that would not improve the model at all) and some checking afterwards that the molecule is physically possible (I try 10 times to generate one per call, which is usually overkill). I also get some metadata from a government API about molecules.
On the H100, I ran one of those stable diffusion LORAs. It takes a diagram of a molecule (easy to generate from a SMILES string) and then does img2img on it. No prompt, so it usually dreams up a picture of glasses or jewellery. We thought this was kind of interesting, so left it in. We could sort of justify it as a mnemonic device for education.
Finally, I added another endpoint that takes two molecules and creates a new one out of the combination of the two. This was for the "synthesise" journey, and was inspired by those games where you combine elements to form new things.
Throughout the hackathon, we communicated over Discord, even though on the Saturday, Rowan and I sat next to each other. Nour was in Coventry throughout. It was actually easier to talk over Discord, even with Rowan, as it was a bit noisy there. Towards the end of Saturday, my age started to show and I decided to sleep in my own bed at home. Rowan stayed at the hackathon place, but we did do some work late into the night together remotely, while Nour was offline. The next day, I was quite busy, so Rowan and Nour tied up the rest of the work, while I only did some minor support with deployment (literally via SSH on my phone as I was out).
Finally, Rowan submitted our entry before getting some well-deserved rest. He put up some links to everything here, including the demo video.
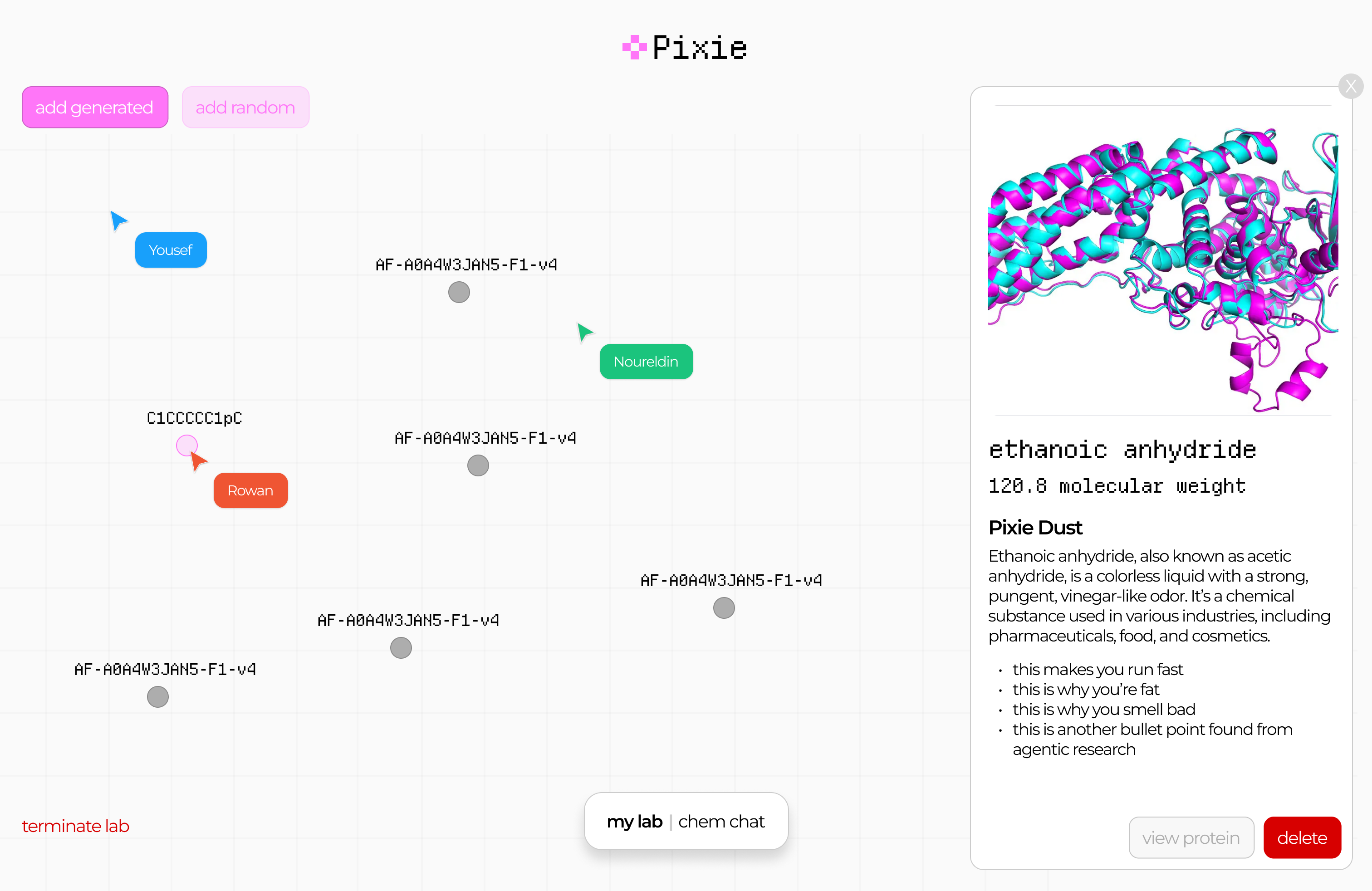
Not long after the contest was over, they killed the H100 machines and seem to have invalidated some of the API keys also, so it looks like the app is also not quite working anymore, but overall it was quite fun! We did not end up winning (unsurprisingly) but I feel like I've achieved my own goals. Rowan and Nour are very driven builders who I enjoyed working with, and CodeNode is a great venue for this sort of thing. The next week, Rowan came over to my office to co-work and also dropped off some hackathon merch. I ended up passing on the merch to other people, as I felt a bit like I might be past my hackathon years now!
Thoughts on chat as an interface
Chat as an interface has always been something I thought about a lot. After all, it's a close analogue to spoken conversation, our most natural form of communication.
The most basic chat interface is an input box and a chronological history of messages, so you can follow the conversation. Messages are often augmented with emojis etc to fill in the gaps for intonation and body language. If you need higher communication bandwidth, voice messages do it sometimes too. Advantages over face-to-face conversation is that text-based conversations have the option of being asynchronous and much longer-lived, potentially even pen-pal style correspondences.
Group conversations
The moment you start thinking about group conversations, some problems begin to be unearthed. One problem is it can get quite crowded, as you're sharing a linear chat history. It's hard to follow multiple threads of conversation that have been flattened into one, when in real life conversations can branch off and diverge.
This is a problem in video conferences too. While at a social event, groups naturally divide into smaller clusters of people in their own bubble of conversation, this has to be done explicitly in video conferences through breakout rooms and similar mechanics. Otherwise all the attention and spotlight is aimed at the person currently talking, which can throw off the dynamics.
I first noticed this phenomenon when I was running the Duolingo German language events in London. It's already common for people who don't know the language well to be shy about speaking up, but when covid started and we switched to Zoom, it was very easy for whomever is speaking to get stage fright, even if they're not normally shy. What then ends up happening is that two or three people will engage in conversation while the rest watch, unless the host (me in that case) takes control of the group dynamics. This was much easier to do in-person, especially where I could see the person's face and gauge how comfortable they are, so I don't put them on the spot (e.g. by bringing them into the conversation with simple yes/no questions).
Attempts at solutions
Anyway, during covid I became quite interested in products that try to solve these problems by capturing aspects of real-life communication through product design. I remember imagining a 2D virtual environment with spatial audio in the context of my PhD research. It turned out somebody was already building something similar: a fellow named Almas, and I remember having a call with him about SpatialChat (a conversation full of lovely StarCraft metaphors). This was an environment that allowed you to replicate the act of physically leaving a huddle and moving to a different cluster to talk. You could only be heard by those in "earshot".
A 2D game called Manyland did something similar with text-only, where text would appear above the head of your character as you were typing. This created interesting new dynamics and etiquette around "interrupting" each other, as well as things like awkward silences, which don't exist when you're waiting for someone to type. There was even an odd fashion around typing speed at one point.
Interestingly, you're not occupying space in the chat log by chatting; you're filling the space above your head, so you just need to find a good place to perch. Two people can respond to the same thing at the same time. However, one person can't quite multi-task their responses / threads without jumping back and forth between people, but after all that's how it works in real life too, no?
Reply chains and threads
I won't go over the history of different chat platforms and apps, but we've seen a lot of patterns that try and create some structure around communication, here in order from more ephemeral to less ephemeral:
- Quoting a message to reply to inline
- Ad-hoc threads that create a separated chat log
- More permanent threads akin to forums
- Permanent "topic" channels
I like to imagine conversations as trees, where branches can sprout and end just as fast. Have you ever been in an argument where someone rattles off a bunch of bad points, but you can only counter them in series? Each of your responses may in turn trigger several additional responses, and you get this exponentially growing tree and eventually you're writing essays dismantling every point one by one.
In real life, it's often hard to remember everything that was said, so you focus on just the most important parts. Or you deliberately prune the branches to the conversation doesn't become unwieldy. Some people like to muddy the waters and go off topic and it's up to you to steer the conversation back to the main trunk.
But not everything is a debate. A friend of mine figured that this tree, in 2D, ought to be the way to hold conversations. Big big internet conversations (he used social media as an example) are all adding nodes to far off branches of a huge tree. I quite like that picture. It would certainly allow for conversations to happen in parallel at the same time as you can hop back and forth between branches.
ChatGPT and the history tree
ChatGPT made the choice that chats should be linear, but you can start a new chat with a new instance of the AI at any time, and go back to old chats through the history tab. This seems to make sense for chatting with an AI assistant, but an anti-pattern emerges...
Have you ever gone down a conversation with ChatGPT only to realise that it's dug itself into a hole, so you scroll up to just after the last "good" message and edit the message to create a new, better timeline? I do this a lot, and it reminded me of undo/redo in text editors.
Undo and redo are normally linear, and if you go back in time and make a change, suddenly the old "future" is no longer accessible to you. We've all done it where we accidentally typed something after pressing undo a bunch of times to check a past version, losing our work.
Someone made a plugin for vim that allows you to navigate a tree of timelines that you create by undo-ing, sort of like automatic git branching and checkout. I feel like this ought to be a UI for interacting with ChatGPT too! Already this is being used for better responses and I feel like there must have been attempts at creating a UI like this, but I haven't seen one that does this elegantly.
Conclusion
This has been kind of a stream of though post, inspired by my post on resetting my AI assistant's chat memory, so I'm not entirely sure what the point I'm trying to make is. I think I'm mainly trying to narrow down the ergonomics of an ideal chat interface or chat in a virtual environment.
I think you would probably have some set of "seed" nodes -- the stem cells to your threads -- which are defined by individuals (i.e. DMs), or groups with a commonality, or topics. These would somehow all capture the nuances of real-life communication, but improve on that with the ability to optionally create ephemeral threads out of reply branches. I'm not yet sure what the UI would physically look like though.
Machete: a tool to organise my bookmarks
I've had a problem for a while around organising articles and bookmarks that I collect. I try not to bookmark things arbitrarily, and instead be mindful of the purpose of doing so, but I still have thousands of bookmarks, and they grow faster than I can process them.
I've tried automated approaches (for example summarising the text of these webpages and clustering vector embeddings of these) with limited success so far. I realised that maybe I should simply eat the frog and work my way through these, then develop a system for automatically categorising any new/inbound bookmark on the spot so they stay organised in the future.
A new problem was born: how can I efficiently manually organise my bookmarks? The hardest step in my opinion is having a good enough overview of the kinds of things I bookmark such that I can holistically create a hierarchy of categories, rather than the greedy approach where I tag things on the fly.
I decided to first focus on bookmarks that I would categorise as "tools", which are products or services that I currently use, may use in the future, want to look at to see if they're worth using, or may want to recommend to others in the future if they express a particular need. These are a bit more manageable as they're a small subset; the bigger part of my bookmarks are general knowledge resources (articles etc).
At the moment, I rely on my memory for the above use cases. Often I don't remember the name of a tool, but I can usually find it with a substring search of the summaries. Often I don't remember tools in the first place, and am surprised to find that I bookmarked something that I wish I would have remembered existed.
Eventually, I landed on a small script to convert all my notes into files, and then using different file browsers to drag and drop files into the right place. This was still very cumbersome.
On the front page of my public notes I have two different visualisations for browsing these notes. I find them quite useful for getting an overview. I thought it might be quite useful to use the circles view for organisation too. So I thought I should make a minimal file browser that displays files in this way, for easy organisation.
Originally, I took this as an excuse to try Tauri (a lighter Electron equivalent built on Rust that uses native WebViews instead of bundled Chromium), and last month I did get an MVP working, but then I realised that I'm making things hard on myself, especially since the development workflow for Tauri apps wasn't very smooth with my setup.
So instead, I decided to write this as an Obsidian plugin, since Obsidian is my main PKM tool. Below is a video demo of how far I got.
You can:
- Visualise files and directories in your vault
- Pan with middle-mouse
- Zoom with the scroll wheel
- Drag and drop nodes (files or directories) to move them
Unlike the visualisation on my front page, which uses word count for node size, this version uses file size. So far, it helps with organisation, although I would like to work on a few quality-of-life things to make this properly useful.
- A way to peek at the contents in a file without opening it
- Better transitions when the visualisation updates (e.g. things moving or changing size) so you don't get lost
- Mobile support (mainly alternative controls, like long-press to drag)
Blast-off into Geminispace
Today was the "Build a Website in an Hour" IndieWeb event (more info here). I went in not quite knowing what I wanted to do. Then, right as we began, I remembered learning about Gemini and Astrobotany from Jo. I thought this would be the perfect opportunity to explore Gemini, and build a Gemini website!
Gemini is a simple protocol somewhere between HTTP and Gopher. It runs on top of TLS and is deliberately quite minimal. You normally need a Gemini client/browser in order to view gemini:// pages, but there's an HTTP proxy here.
I spent the first chunk of the hour trying to compile Gemini clients on my weird setup. Unfortunately, this proved to be quite tricky on arm64 (I also can't use snap or flatpak because of reasons that aren't important now). I eventually managed to install a terminal client called Amfora and could browse the Geminispace!
Then, I tried to get a server running. I started in Python because I thought this was going to be hard as-is, and I didn't want to take more risks than needed, but then I found that it's actually kind of easy (you only need socket and ssl). Once I had a server working in Python, I thought that I actually would prefer if I could run this off of the same server that this website (yousefamar.com) uses. Most of this website is static, but there's a small Node server that helps with rebuilding, wiki pages, and testimonial submission.
So for the next chunk of time, I implemented the server in Node. You can find the code for that here. I used the tls library to start a server and read/write text directly from/to a socket.
Everything worked fine on localhost with self-signed certificates that I generated with openssl, but for yousefamar.com I needed to piggyback off of the certificates I already have for that domain (LetsEncrypt over Caddy). I struggled with this for most of the rest of the time. I also had an issue where I forgot to end the socket after writing, causing requests to time out.
I thought I might have to throw in the towel, but I fixed it just as the call was about to end, after everyone had shown their websites. My Gemini page now lives at gemini://yousefamar.com/ and you can visit it through the HTTP proxy here!
I found some Markdown to Gemini converters, and I considered having all my public pages as a capsule in Geminispace, but I think many of them wouldn't quite work under those constraints. So instead, in the future I might simply have a gemini/ directory in the root of my notes or similar, and have a little capsule there separate from my normal web stuff.
I'm quite pleased with this. It's not a big deal, but feels a bit like playing with the internet when it was really new (not that I'm old enough to have done that, but I imagine this is what it must have felt like).
Forgotten Conquest port
A while ago I wrote about discovering a long-forgotten project from 2014 I had worked on in the past called Mini Conquest. As the kind of person who likes to try a lot of different things all the time, over my short 30 years on this earth I have forgotten about most of the things I've tried. It can therefore be quite fun to forensically try and piece together what my past self was doing. I thought I had gotten to the bottom of this project and figured it out: an old Java gamedev project that allowed me to play around with the 2.5D mechanic.
Well, it turns out that's not where it ended. Apparently, I had ported the whole thing to Javascript shortly after, meaning it actually runs in the browser, even today somehow! I had renamed it to "Conquest" by then. As was my style back then, I had 0 dependencies and wanted to write everything from scratch.
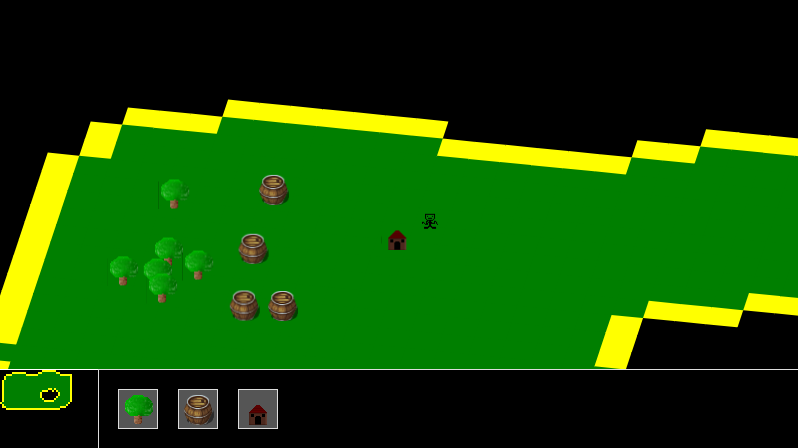
If you've read what I wrote about the last one, you might be wondering why the little Link character is no longer there, and what the deal with that house and the stick figure is. Well, turns out I decided to change genres too! It was no longer a MOBA/RTS but more like a civilisation simulator / god game.
The player can place buildings, but the units have their own AI. The house, when place, can automatically spawn a "Settler". I imagine that I probably envisioned these settlers mining and gathering resources on their own, with which you can decide what things to build next, and eventually fight other players with combat units. To be totally honest though, I no longer remember what my vision was. This forgetfulness is why I write everything down now!
The way I found out about this evolution of Mini Conquest was also kind of weird. On the 24th of January 2023, a GitHub user called markeetox forked my repo, and added continuous deployment to it via Vercel. The only evidence I have of this today is the notification email from Vercel's bot; all traces of this repo/deployment disappeared shortly after. Maybe he was just curious what this is.
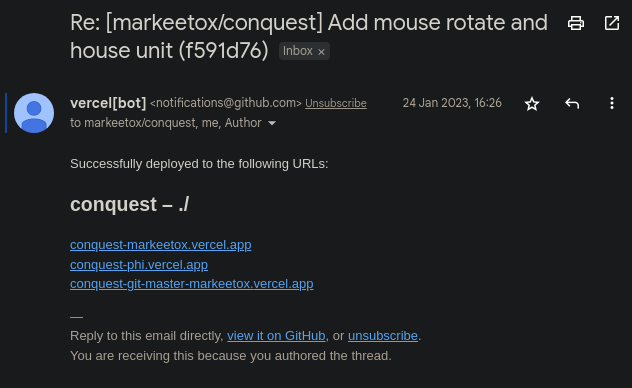
I frankly don't quite understand how this works. The notification came from his repo on a thread related to a commit or something, that is apparently authored by me (since I authored the commit?) and I've been automatically subscribed in his fork? Odd!
Homebound: an old game jam project revived
Around two months ago, I was talking to a friend about these games that involve programming in some form (mainly RTSs where you program your units). Some examples of these are:
- https://leekwars.com
- https://codingame.com
- https://spacetraders.io
- https://screeps.com
- The various normal games that let you program AI players
Needless to say, I'm a fan of these games. However, during that conversation, I suddenly remembered: I made a game like this once! I had completely forgotten that for a game jam, I had made a simple game called Homebound. You can learn more about it at that link!
At the time, you could host static websites off of Dropbox by simply putting your files in the Public folder. That no longer worked, so the link was broken. I dug everywhere for the project files, but just couldn't find them. I was trying to think if I was using git or mercurial back then and where I could have put them. I think it's likely I didn't bother because it was something small to put out in a couple of hours.
Eventually, in the depths of an old hard drive, I found a backup of my old Dropbox folder, and in that, the Homebound source code! Surprisingly, it still worked perfectly in modern browsers (except for a small CSS tweak) and it now lives on GitHub pages.
Then, I forgot about this again (like this project is the Silence), until I saw the VisionScript project by James, which reminded me of making programming languages! So I decided to create a project page for Homebound here.
I doubt I will revisit this project in the future, but I might play with this mechanic again in the context of other projects. In that case, I might add to this devlog to reference that. I figured I should put it out there for posterity regardless!
Collecting testimonials for mentorship/advisory
(Skip to the end for the conclusion on how this has affected my website, or continue reading for the backstory).
For as long as I can remember, I've been almost consistently engaged in some form of education or mentorship. Going back to my grandparents, and potentially great-grandparents, my family on both sides has all been teachers, professors, and even a headmaster, so perhaps it's something in my blood. I started off teaching in university as a TA (and teaching at least one module outright where the lecturer couldn't be bothered). Later, I taught part-time in a pretty rough school (which was quite exhausting) and even later at a much fancier private school (which wasn't as exhausting, but much less fulfilling) and finally I went into tutoring and also ran a related company. I wound this business up when covid started.
Over the years I found that, naturally, the smaller the class, the more disproportional impact you can have when teaching. I also found that that personal impact goes up exponentially not when I teach directly, but zoom out and find out what it is the student actually needs (especially adult students), and help them unblock those problems for themselves. As the proverb goes,
"Give a man a fish, and you feed him for a day. Teach a man to fish, and you feed him for a lifetime."
There's also a law of diminishing returns at play here. By far the biggest impact you can have when guiding someone to reach their goals (academic or otherwise) comes at the very start. This immediate impact has gotten bigger and bigger over time as I've learned more and more myself. Sometimes it's a case of simply reorienting a person, and sending them on their way, rather than holding their hand throughout their whole journey.
This is how I got into mentoring. I focused mainly on supporting budding entrepreneurs and developers from underpriviledged groups, mainly organically through real-life communities, but also through platforms like Underdog Devs, ADPList, Muslamic Makers and a handful of others. If you do this for free (which I was), you can only really do on the side, with a limited amount of time. I wasn't very interested in helping people who could actually afford paying me for my time, paradoxically enough...
I decided recently that there ought to be an optimal middle ground that maximises impact. 1:1 mentoring just doesn't scale, and large workshop series aren't effective. I wanted to test a pipeline of smaller cohorts and mix peer-based support with standard coaching. I have friends who I've worked with before who are willing to help with this, and I think I can set up a system that would be very, very cheap and economically accessible to the people I care about helping.
Anyway, I've started planning a funnel, and building a landing page. Of course, any landing page worth its salt ought to have social proof. So I took to LinkedIn. I never post to LinkedIn (in fact, this might actually have been my very first post in the ~15 years I've been on there). I found a great tool for collecting testimonials in my toolbox called Famewall, set up the form/page, and asked my LinkedIn network to leave me testimonials.
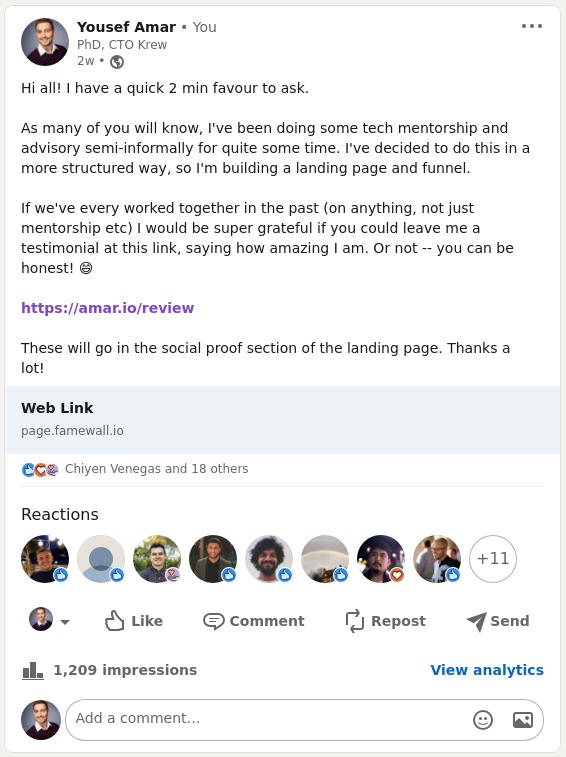
There were a handful of people that I thought would probably respond, but I was surprised that instead other people I completely hadn't expected were responding. In some cases, people that I genuinely didn't remember, and in other cases people where I didn't realise just how much of an impact I had on them. This was definitely an enlightening experience!
I immediately hit the free tier limit of Famewall and had to upgrade to a premium tier to access newer testimonials that were rolling in. It's not cheap, and I'm only using a tiny fraction of the features, but the founder is a fellow indie hacker building it as a solo project and doing a great job, and we chatted a bit, so I figured I should support him.
I cancelled my subscription a few days later when I got around to re-implementing the part that I needed on my own site. That's why this post is under the Website project; the review link (https://amar.io/review) now redirects to a bog standard form for capturing testimonials (with a nice Lottie success animation at the end, similar to Famewall) and in the back end it simply writes the data to disk, and notifies me that there's a new testimonial to review. If it's ok, I tweak the testimonial JSON and trigger an eleventy rebuild (this is a static site). In the future, I might delegate this task to Sentinel!
The testimonials then show up on this page, or any other page onto which I include testimonials.njk (like the future mentoring landing page). For the layout, I use a library called Colcade which is a lighter alternative to Masonry recommended to me by ChatGPT when I asked for alternatives, after Masonry was giving me some grief. It works beautifully!
Editing translation files online
A common way - if not the most common way (looking at WordPress dominance) - to do i18n is using the "Portable Object" format. You start off with a template file (.pot) and normally you would load that into Poedit, type in your translations for every string (including plurals), then download a pair of files: the .po and the "compiled" Machine Object .mo file.
Unfortunately, my daily driver is an arm64 device (my phone actually -- a lot of people think this is insane, but I'll write it up eventually and explain myself). I can't run Poedit without some crazy hacks. You could also copy the .pot file to a .po file, then just edit that directly (it's a straightforward text file), and there are some tools to convert .po to .mo, but that's all a bit of a hassle.
As luck would have it, there's a great free tool online that does everything I need called Loco. You load whatever file in, do your translations (with optional filtering), and download the files. You can save it to a cloud account (which is I think how they make money) but I had no need of that.
I figured this all out after being given access to a WordPress deployment to help an organisation out with some things. Previously, I only had access to the WP dashboard, and changed some text for them via CSS. Now that I had FTP access, I could just change everything in one fell swoop by modifying the English strings for the site, and I deleted the hacky CSS. Once you copy the files back over, everything is automatically updated.
A little CSS trick for editing text
I wrote a short article about a trick for editing the text in HTML text nodes with only CSS. This is one of those articles where the goal is just to share something that I learned or discovered, that someone might benefit from, and the primary mode of finding this content is through a search engine.
It doesn't quite make sense for this to be an "article" in the way that I use that word (a long-form post bound in time that people follow/subscribe to) so I might eventually turn all these guide-type posts into wiki-notes, so they can exist as non-time-bound living documents.
Do NOT use Twilio for SMS
Twilio used to be a cool and trustworthy company. I remember when I was in uni, some CS students (I was not a CS student) built little SMS conversation trees like it was nothing, and suddenly SMS become something you could build things with as a hobby.
Over the past month, my view of Twilio has completely changed.
The attack
Ten days ago (Jan 19th) at around 7am UTC, I woke up to large charges to our business account from Twilio, as well as a series of auto-recharge emails and finally an account suspension email. These charges happened in the span of 3 minutes just before 5am UTC. My reaction at this point was confusion. We were part of Twilio's startup programme and I didn't expect any of our usage to surpass our startup credits at this stage.
I checked the Twilio dashboard and saw that there was a large influx of OTP verification requests from Myanmar numbers that were clearly automated. I could tell that they're automated because they came basically all at once, and mostly from the same IP address (in Palestine). At this point, I realised it was an attack. I could also see that this was some kind of app automation (rather than spamming the underlying API endpoint) as we were also getting app navigation events.
After we were suspended, the verifications failed, so the attack stopped. The attacker seemed to have manually tried a California IP after that some hours later, probably to check if they've been IP blocked, and it probably wasn't a physical phone (Android 7). Then they stopped.
I also saw that our account balance was more than £1.5k in the red (in addition to the charges to our bank account) and our account was suspended until we zero that balance. The timing could not have been worse as we were scheduled to have an important pitch to partners at a tier 1 VC firm. They could be trying the app out already and unable to get in as phone verification was confirmed broken.
Our response
We're on the lowest tier (as a startup) which means our support is limited to email. I immediately opened a ticket to inform Twilio that we were victims of a clear attack, and to ask Twilio for help in blocking these area codes, as we needed our account to be un-suspended ASAP. They took quite a long time to respond, so after some hours I went ahead and paid off the £1.5k balance in order for our account to be un-suspended, with the hope that they can refund us later.
I was scratching my head at what the possible motive of such an attack could be. I thought it must be denial of service, but couldn't think of a motive. We're not big enough for competitors to want to sabotage us, so I was expecting an email at any point from someone asking for bitcoin to stop attacking us, or a dodgy security company coming in and asking for money to prevent it. But Twilio sent an email saying that this is a case of toll fraud.
I recommend reading that article, but in essence, those numbers are premium numbers owned by the attacker, and every time Twilio sends them a verification SMS, they make money, and we foot the bill.
Twilio's response
Twilio seemed to follow a set playbook that they use for these situations. Their documentation names a set of countries as the one where toll fraud numbers most likely come from and recommend are blocked (I suppose it's easy to get premium numbers there): Bangladesh, Sri-Lanka, Myanmar, Pakistan, Uzbekistan, Azerbaijan, Kyrgyzstan, and Nigeria.
I immediately went and blocked those area codes from our side, though Twilio also automatically blocked all countries except the US and the UK anyway, so it didn't really make a difference. Also, the attacker tried again using Indonesian numbers after that, so clearly a blocklist like that is not enough. Later I went and one by one selectively allowed only countries we actually serve.
Beyond this, Twilio's response was to try and do everything to blame this on us. They wash their hands of the responsibility to secure their own APIs, and instead the onus is on us to implement our own unreasonable security measures.
I told a friend about this, and through that friend found out that this is actually a very common problem that people have been having with Twilio, because Twilio dropped the ball. Apparently, out of all of those cases, we got pretty lucky (some people lost 6 figures). For me, the main issues are:
- Why aren't risky countries blocked by default? Worse, why are all countries in the world allowed by default?
- Why isn't "Fraud Guard", one of the switches (free) that Twilio told us we should have turned on, already turned by default?
- I had set up an auto-recharge rule (charge to £20 if balance goes below £10) just in case the startup credits ever ran low. This backfired dramatically as the account kept auto-recharging in an infinite loop until we were suspended (the reason for the huge charges to our bank account). Why?!
- We were already using the default rate-limiting that applies to individual numbers (something like 5 verification requests every 10 minutes), and our server had some general global rate-limiting per-IP (this probably already protected us quite a bit from what could have been). How is it reasonable to expect your clients to put a global rate limit, across IPs and numbers, for specifically the endpoint that asks for Twilio verification? Just have the rate limit on your side maybe? It's not our responsibility to think of these kinds of things; that's why we're using third party provider!
Their email was incredibly patronising, like others have reported, and they acted like they're doing us a huge favour by blessing us with a partial refund in account credits (not even real money). But we need to explain to them first how we promise to be better and not do a silly mistake like this again!
The refund
Twilio tries to push you into agreeing not to dispute the bank charges (see the link above for why they do this). I refused to agree to this, and first wanted to know exactly how much they would refund us, and if they would refund us in real money, not account credits (they agreed to "prioritize" this).
They told us that their finance team is who decides the refund amount, based on the information we provide on how we'll do better and a breakdown of the charges. I told them exactly what we did to combat this, and what the charges were. We had lost a few hundred in startup credits, then just over £2k in real money.
Instead of telling me how much they would refund (remember, I still haven't agreed not to dispute the charges, which they "required" in order to issue a refund), they went ahead and refunded us £847 and some change immediately.
I believe this to be a ploy to try and prevent us from disputing the original charges, because if we dispute now, we would have more back than what they charged.
What now?
I sought some advice, with mixed opinions, but it seems quite clear that if we dispute these charges, at the very least it would mean that we can no longer use Twilio for SMS anymore (which I don't want to anyway). But, this means switching to a different provider before disputing.
It would be relatively easy to switch, as they all tend to work the same way anyway, but would still require:
- Researching other providers (that don't use Twilio in the backend)
- Reading their documentation
- Swapping out the libraries and a dozen or so lines of code
- Making sure we leave no room for another round of toll fraud
- Testing and deploying
This is not difficult, but time and effort that I don't have right now, as well as a distraction from our actual core product. I don't know if £1.1k is worth that "labour", or any extra stress that may come if Twilio decides to make a stink about this and pass us on to collections etc.
All I know is: Twilio, never again. I will advise people to not use Twilio for the rest of my life and longer depending on how that advice may spread and how long this article survives.
Collaborative editing on wiki notes
GitHub Copilot withdrawal
Yesterday GitHub Copilot engineers borked production and I felt like someone had suddenly turned the lights off.
I hadn't realised how accustomed I had become to using it until this happened. I would make my intent clear in the code, then wait for it to do its thing, then it just wouldn't. Y'all got any more of them AIs?
At the same time, the next time you deploy a bad build to production, remember that even the big guys do it!
